This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Cornellius Yudha Wijaya , KDnuggets Technical Content Specialist on July 17, 2025 in Data Science Image by Author | Ideogram Data is the asset that drives our work as data professionals. Thus, securing suitable data is crucial for any data professional, and datapipelines are the systems designed for this purpose.
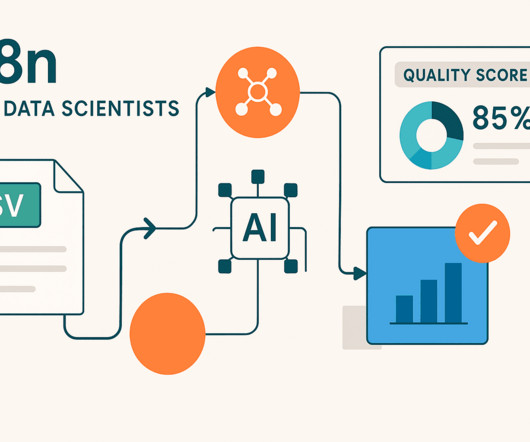
By Josep Ferrer , KDnuggets AI Content Specialist on July 15, 2025 in Data Science Image by Author Delivering the right data at the right time is a primary need for any organization in the data-driven society. But lets be honest: creating a reliable, scalable, and maintainable datapipeline is not an easy task.
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
With over 30 million monthly downloads, Apache Airflow is the tool of choice for programmatically authoring, scheduling, and monitoring datapipelines. Airflow enables you to define workflows as Python code, allowing for dynamic and scalable pipelines suitable to any use case from ETL/ELT to running ML/AI operations in production.
Shinoy Vengaramkode Bhaskaran, Senior Big Data Engineering Manager, Zoom Communications Inc. As AI agents become more intelligent, autonomous and pervasive across industries—from predictive customer support to automated infrastructure management—their performance hinges on a single foundational …
Get a Demo Login Try Databricks Blog / Platform / Article What’s New with Azure Databricks: Unified Governance, Open Formats, and AI-Native Workloads Explore the latest Azure Databricks capabilities designed to help organizations simplify governance, modernize datapipelines, and power AI-native applications on a secure, open platform.
🔗 Link to the code on GitHub Why Data Cleaning Pipelines? Think of datapipelines like assembly lines in manufacturing. Wrapping Up Datapipelines arent just about cleaning individual datasets. Each step performs a specific function, and the output from one step becomes the input for the next.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts 8 Ways to Scale your Data Science Workloads Vibe Coding Something Useful with Repl.it
In Airflow, DAGs (your datapipelines) support nearly every use case. As these workflows grow in complexity and scale, efficiently identifying and resolving issues becomes a critical skill for every data engineer. This is a comprehensive guide with best practices and examples to debugging Airflow DAGs.
From UI improvements to more advanced workflow control, check out the latest in Databricks’ native data orchestration solution and discover how data engineers can streamline their end-to-end datapipeline experience. More controlled and efficient data flows Our orchestrator is constantly being enhanced with new features.
Latency While streaming promises real-time processing, it can introduce latency, particularly with large or complex data streams. To reduce delays, you may need to fine-tune your datapipeline, optimize processing algorithms, and leverage techniques like batching and caching for better responsiveness.
Generative AI: A Self-Study Roadmap Get the FREE ebook The Great Big Natural Language Processing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts 10 Surprising Things You Can Do with Python’s collections Module The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs 10 Python Math & Statistical Analysis One-Liners 10 GitHub Repositories for Python Projects Building (..)
Adding high-quality entity resolution capabilities to enterprise applications, services, data fabrics or datapipelines can be daunting and expensive. Organizations often invest millions of dollars and years of effort to achieve subpar results.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Next post => Latest Posts The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs 10 Python Math & Statistical Analysis One-Liners 10 GitHub Repositories for Python Projects Building End-to-End DataPipelines: From Data Ingestion to Analysis (..)
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Next post => Latest Posts 8 Ways to Scale your Data Science Workloads Vibe Coding Something Useful with Repl.it
Top Posts 7 Python Web Development Frameworks for Data Scientists Build Your Own Simple DataPipeline with Python and Docker 10 GitHub Repositories for Machine Learning Projects 10 Python One-Liners for JSON Parsing and Processing What Does Python’s __slots__ Actually Do?
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on June 19, 2025 in Programming Image by Author | Ideogram Youre architecting a new datapipeline or starting an analytics project, and you’re probably considering whether to use Python or Go. We compare Go and Python to help you make an informed decision.
Example processing flow: utilizing databricks to communicate with APIs to improve data. Image by author Automated harmonization, labeling, and data generation By establishing datapipelines, organizations can utilize GenAI as new data enters their systems.
By integrating Agile methodologies into data practices, DataOps enhances collaboration among cross-functional teams, leading to improved data quality and speed in delivering insights. DataOps is an Agile methodology that focuses on enhancing the efficiency and effectiveness of the data lifecycle through collaborative practices.
The full code is available in the Colab notebook embedded below, ready for you to explore and adapt to your own data. Pipeline: Images are encoded by DINOv2 into feature vectors, which are then used to train a linear classification head | Image by the author.
Relational Graph Transformers represent the next evolution in Relational Deep Learning, allowing AI systems to seamlessly navigate and learn from data spread across multiple tables.
Instead of sweating the syntax, you describe the “ vibe ” of what you want—be it a datapipeline, a web app, or an analytics automation script—and frameworks like Replit, GitHub Copilot, Gemini Code Assist, and others do the heavy lifting. Learn more at Gemini Code Assist.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts Benefits of Using LiteLLM for Your LLM Apps 5 Fun Generative AI Projects for Absolute Beginners 8 Ways to Scale your Data Science Workloads Vibe Coding Something Useful with Repl.it
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Choose Delete stack.
Scheduled Analysis Replace the Manual Trigger with a Schedule Trigger to automatically analyze datasets at regular intervals, perfect for monitoring data sources that update frequently. This proactive approach helps you identify datapipeline issues before they impact downstream analysis or model performance.
Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex datapipelines. The following diagram illustrates the conceptual architecture of an AI assistant with Amazon Bedrock IDE.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs 10 Python Math & Statistical Analysis One-Liners 10 GitHub Repositories for Python Projects Building End-to-End DataPipelines: From Data Ingestion to Analysis Bootstrapping (..)
Building effective datapipelines is critical for organizations seeking to transform raw research data into actionable insights. Businesses rely on seamless, efficient, scalable pipelines for proper data collection, processing, and analysis.
High latency may indicate high user demand or inefficient datapipelines, which can slow down response times. For instance, when latency spikes on a specific instance, a monitor in the monitor summary section of the dashboard will turn red and trigger alerts through Datadog or other paging mechanisms (like Slack or email).
Feeding data for analytics Integrated data is essential for populating data warehouses, data lakes, and lakehouses, ensuring that analysts have access to complete datasets for their work.
What started as an awkward moment for Astronomer on a stadium screen has become one of the most unexpected marketing pivots in tech and a case study in how AI infrastructure companies can build brand resilience as effectively as they build datapipelines. Astronomer: Personal Goes Public On July 16, …
Knowledge-intensive analytical applications retrieve context from both structured tabular data and unstructured, text-free documents for effective decision-making. Large language models (LLMs) have made it significantly easier to prototype such retrieval and reasoning datapipelines.
Key Features Tailored for Data Science These platforms offer specialised features to enhance productivity. Managed services like AWS Lambda and Azure Data Factory streamline datapipeline creation, while pre-built ML models in GCPs AI Hub reduce development time. Below are key strategies for achieving this.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Next post => Latest Posts 7 Python Web Development Frameworks for Data Scientists What Does Python’s __slots__ Actually Do?
Today’s datapipelines use transformations to convert raw data into meaningful insights. Yet, ensuring the accuracy and reliability of these transformations is no small feat – tools and methods to test the variety of data and transformation can be daunting.
Data Visualization & Analytics Explore creative and technical approaches to visualizing complex datasets, designing dashboards, and communicating insights effectively. Ideal for anyone focused on translating data into impactful visuals and stories. Perfect for building the infrastructure behind data-driven solutions.
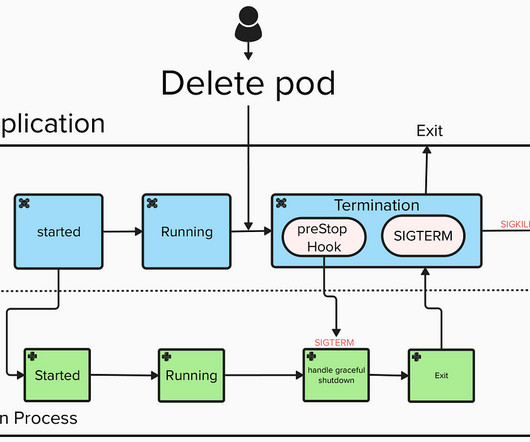
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. What happens when a user or system administrator needs to kill a job mid-execution?
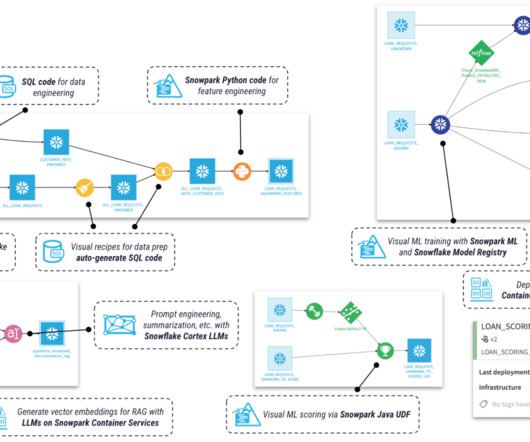
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
What Is Continuous Delivery? Continuous delivery (CD) refers to a software engineering approach where teams produce software in short cycles, ensuring that software can be reliably released at any time. Its main goals are to build, test, and release software faster and more frequently.
Distinction between data architect and data engineer While there is some overlap between the roles, a data architect typically focuses on setting high-level data policies. In contrast, data engineers are responsible for implementing these policies through practical database designs and datapipelines.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Next post => Latest Posts Benefits of Using LiteLLM for Your LLM Apps 5 Fun Generative AI Projects for Absolute Beginners 8 Ways to Scale your Data Science Workloads Vibe Coding Something Useful with Repl.it
Shafeeq Ur Rahaman is a seasoned data analytics and infrastructure leader with over a decade of experience developing innovative, data-driven solutions. Shafeeq is passionate about advancing data science, fostering continuous learning, and translating data into actionable insights.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content