This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
This has created many different data quality tools and offerings in the market today and we’re thrilled to see the innovation. People will need high-quality data to trust information and make decisions. The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph.
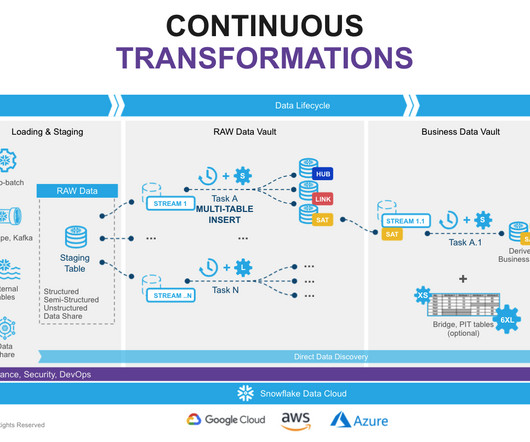
The implementation of a data vault architecture requires the integration of multiple technologies to effectively support the design principles and meet the organization’s requirements. Leverage dbt’s `test` macros within your models and add constraints to ensure data integrity between data vault entities.
It is widely used for storing and managing structured data, making it an essential tool for data engineers. MongoDB MongoDB is a NoSQL database that stores data in flexible, JSON-like documents. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data.
As data types and applications evolve, you might need specialized NoSQL databases to handle diverse data structures and specific application requirements. With an open data lakehouse, you can access a single copy of data wherever your data resides.
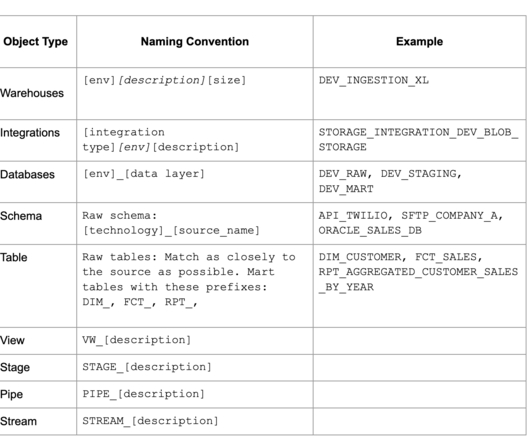
Use Metadata Driven Pipelines When Possible Standardizing ETL/ELT processes can be difficult. Create Standard Process Patterns As a team defines the various stages of data as it flows through their Snowflake environment, it is essential to document a few standard patterns. What is a Pattern?
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. You have the function docstring because with procedural code generally in script form, there is no place to stick documentation naturally.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content