This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
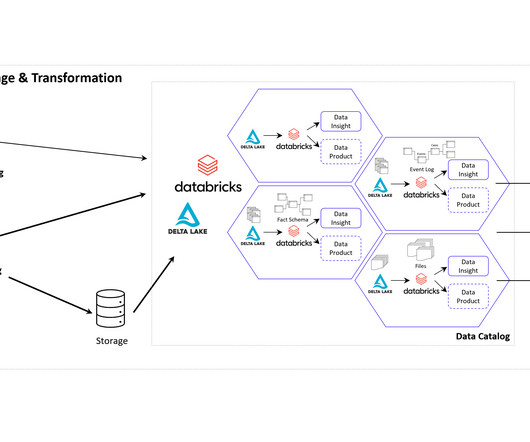
It advocates decentralizing data ownership to domain-oriented teams. Each team becomes responsible for its Data Products , and a self-serve data infrastructure is established. This enables scalability, agility, and improved dataquality while promoting data democratization.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
Also, AI can analyze real-time data and provide risk assessments on the minute. What does Bitcoin price forecast datamodels say? Q2 2025 Outlook: Assuming no macroeconomic shocks, AI sentiment trackers and LSTM models indicate continued range trading of $85,000-$95,000. So whats the outlook for BTC?
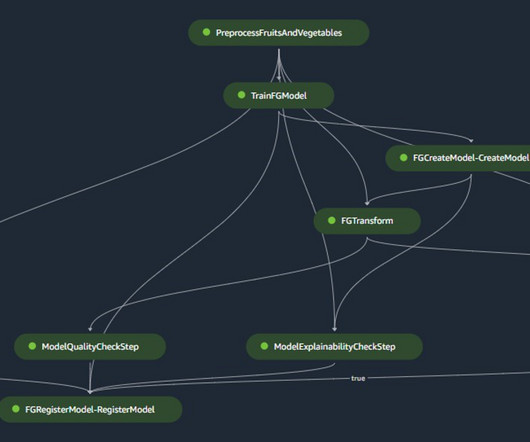
Unified model governance architecture ML governance enforces the ethical, legal, and efficient use of ML systems by addressing concerns like bias, transparency, explainability, and accountability. Associate the model to the ML project and record qualitative information about the model, such as purpose, assumptions, and owner.
In this case, we are developing a forecasting model, so there are two main steps to complete: Train the model to make predictions using historical data. Apply the trained model to make predictions of future events. Workflow B corresponds to modelquality drift checks.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? Your data team can manage large-scale, structured, and unstructured data with high performance and durability.
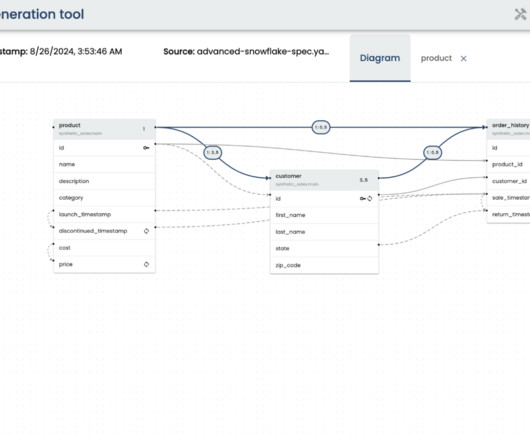
You can combine this data with real datasets to improve AI model training and predictive accuracy. Creating synthetic test data to expedite testing, optimization and validation of new applications and features. Using synthetic data to prevent the exposure of sensitive data in machine learning algorithms.
Data Velocity: High-velocity data streams can quickly overwhelm monitoring systems, leading to latency and performance issues. DataQuality: The accuracy and completeness of data can impact the quality of model predictions, making it crucial to ensure that the monitoring system is processing clean, accurate data.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Data privacy policy: We all have sensitive data—we need policy and guidelines if and when users access and share sensitive data. Dataquality: Gone are the days of “data is data, and we just need more.” Now, dataquality matters. Datamodeling. Data migration .
Data privacy policy: We all have sensitive data—we need policy and guidelines if and when users access and share sensitive data. Dataquality: Gone are the days of “data is data, and we just need more.” Now, dataquality matters. Datamodeling. Data migration .
In contrast, data warehouses and relational databases adhere to the ‘Schema-on-Write’ model, where data must be structured and conform to predefined schemas before being loaded into the database. You can also get data science training on-demand wherever you are with our Ai+ Training platform.
According to a 2023 study from the LeBow College of Business , data enrichment and location intelligence figured prominently among executives’ top 5 priorities for data integrity. 53% of respondents cited missing information as a critical challenge impacting dataquality. What is data integrity?
Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data. It supports batch processing and real-time streaming, making it a go-to tool for data engineers working with large datasets. Apache Kafka Apache Kafka is a distributed event streaming platform used for real-time data processing.
Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance. Introduction In today’s data-driven landscape, organisations are increasingly reliant on Data Analytics to inform decision-making and drive business strategies.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. It is used to extract data from various sources, transform the data to fit a specific datamodel or schema, and then load the transformed data into a target system such as a data warehouse or a database.
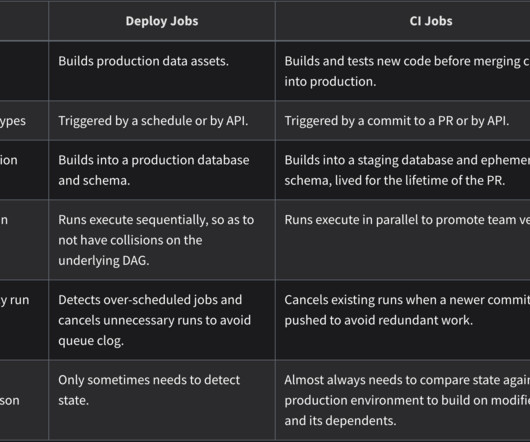
The DAGs can then be scheduled to run at specific intervals or triggered when an event occurs. dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation.
The most common tools in use are Prometheus and Grafana Alerting, based on logs, infra, or ML monitoring outputs ML specific monitoring Experiment tracking: Parameters, models, results, etc. These are both industry standard ways to connect pieces of an application in a way that makes it easy to swap pieces out.
Some of the common career opportunities in BI include: Entry-level roles Data analyst: A data analyst is responsible for collecting and analyzing data, creating reports, and presenting insights to stakeholders. They may also be involved in datamodeling and database design.
Some of the common career opportunities in BI include: Entry-level roles Data analyst: A data analyst is responsible for collecting and analyzing data, creating reports, and presenting insights to stakeholders. They may also be involved in datamodeling and database design.
Data should be designed to be easily accessed, discovered, and consumed by other teams or users without requiring significant support or intervention from the team that created it. Data should be created using standardized datamodels, definitions, and quality requirements. What is Data Mesh?
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. It also involves data enriching – a crucial step for further data travel.
Their prime focus is to keep a tab on data collection and ensure that the exchange and movement of data are as per the policies. DataModeling These are simple diagrams of the system and the data stored in it. It helps you to view how the data flows through the system.
The platform is used by businesses of all sizes to build and deploy machine learning models to improve their operations. ArangoDB ArangoDB is a company that provides a database platform for graph and document data. It is a NoSQL database that uses a flexible datamodel that can be used to store and manage both graphs and documents.
Descriptive analytics helps identify patterns, outliers, and overall data characteristics, allowing businesses to comprehensively understand their historical performance. Diagnostic Analytics Diagnostic analytics goes further than descriptive analytics by focusing on why certain events occurred. Examples of Predictive Analytics: a.
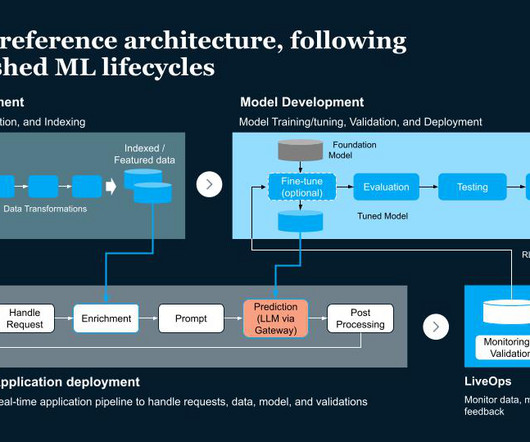
Data Pipeline - Manages and processes various data sources. Application Pipeline - Manages requests and data/model validations. Multi-Stage Pipeline - Ensures correct model behavior and incorporates feedback loops. This includes versioning, ingestion and ensuring dataquality.
Instead, AI agents will proactively respond to business events such as incoming customer inquiries, supply chain disruptions, or demand surges. This will only worsen, and companies must learn to adapt their models to unique, content-rich data sources. In the future, users will not even need to trigger an action.
Because of this, they will be required to work closely with business stakeholders, data teams, and even other tech-focused members of an organization to sure that the needs of the organization are met and comply with overall business objectives. From practical training, hands-on workshops, networking events, and more.
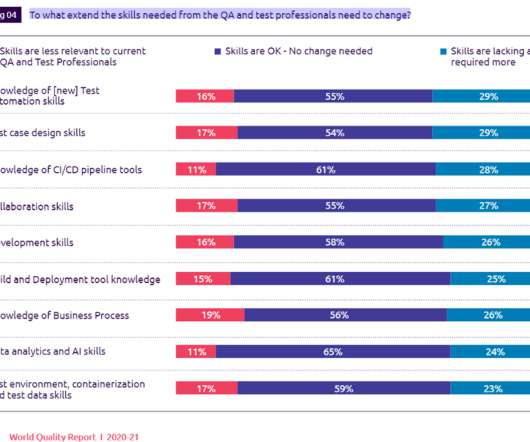
billion annually due to improperly organized testing – despite the fact that 25-40% of budget funds are allocated to methods and tools for Quality Assurance (QA) organization. According to research work done by the National Institute of Standards and Technology, the US economy loses from $22.5 billion to $59.5 What does this mean?
IoT and machine learning: Walking hand in hand towards smarter future The role of data science in optimizing IoT ecosystems Data science plays a critical role in optimizing IoT ecosystems by enabling organizations to derive insights from the vast amounts of data generated by IoT devices and sensors.
IoT and machine learning: Walking hand in hand towards smarter future The role of data science in optimizing IoT ecosystems Data science plays a critical role in optimizing IoT ecosystems by enabling organizations to derive insights from the vast amounts of data generated by IoT devices and sensors.
NoSQL Databases NoSQL databases do not follow the traditional relational database structure, which makes them ideal for storing unstructured data. They allow flexible datamodels such as document, key-value, and wide-column formats, which are well-suited for large-scale data management.
Typical Scenarios: Business intelligence (BI), reporting, and analytics Dataquality and monitoring Governance and privacy Data discovery and cataloging Machine learning and data science Have a look at a complete semantic model in the new dbt Semantic Layer from dbt Docs.
Three reasons you need to build an experiment tracking tool Handling metadata and artifact lineage from data and model origins An experiment tracking tool can help your data scientists trace the lineage of experiment artifacts from their data and model origins, store the resulting metadata, and manage it.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
Nowadays, with the advent of deep learning and convolutional neural networks, this process can be automated, allowing the model to learn the most relevant features directly from the data. Model Training: With the labeled data and identified features, the next step is to train a machine learning model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content