This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These skills include programming languages such as Python and R, statistics and probability, machinelearning, data visualization, and datamodeling. This includes sourcing, gathering, arranging, processing, and modelingdata, as well as being able to analyze large volumes of structured or unstructured data.
Data Science is a field that encompasses various disciplines, including statistics, machinelearning, and data analysis techniques to extract valuable insights and knowledge from data. It is divided into three primary areas: datapreparation, datamodeling, and data visualization.
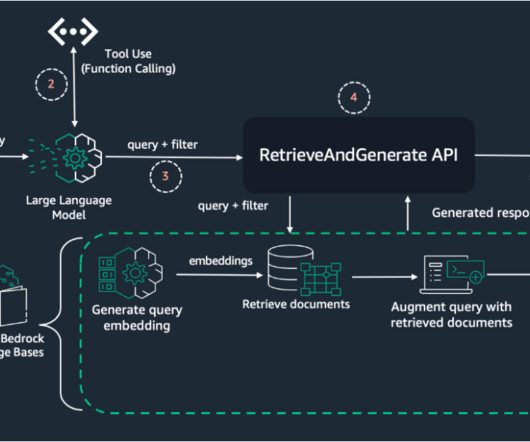
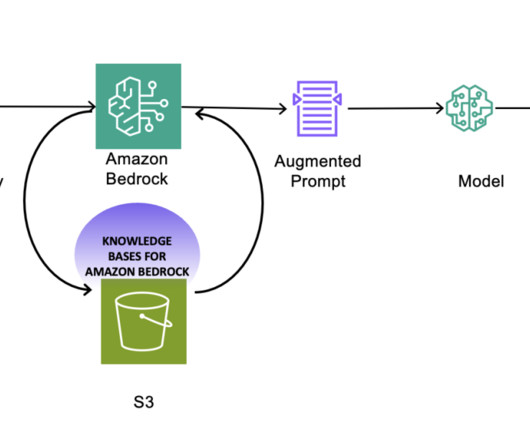
By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries. Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata.
Consequently, there is a growing need to establish best practices for effectively integrating these models into operational workflows. LLMOps facilitates the streamlined deployment, continuous monitoring, and ongoing maintenance of large language models. LLMOps MLOps for Large Language Model What are the components of LLMOps?
You can now register machinelearning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks.
They are using tools like Amazon SageMaker to take advantage of more powerful machinelearning capabilities. Amazon SageMaker is a hardware accelerator platform that uses cloud-based machinelearning technology. IBM Watson Studio is a very popular solution for handling machinelearning and data science tasks.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation.
These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data. These statistical models are growing as a result of the wide swaths of available current data as well as the advent of capable artificial intelligence and machinelearning.
How to Use MachineLearning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machinelearning were introduced.
Nonetheless, Data Scientists need to be mindful of its limitations and ethical issues. This blog discusses best practices, real-world use cases, security and privacy considerations, and how Data Scientists can use ChatGPT to their full potential. This will enhance the datapreparation stage of machinelearning.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
Amazon Forecast is a fully managed service that uses statistical and machinelearning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machinelearning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
Utilizing data streamed through LnW Connect, L&W aims to create better gaming experience for their end-users as well as bring more value to their casino customers. With predictive maintenance, L&W can get advanced warning of machine breakdowns and proactively dispatch a service team to inspect the issue.
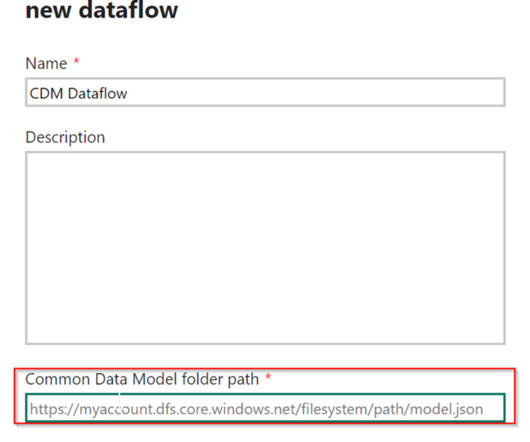
Dataflows represent a cloud-based technology designed for datapreparation and transformation purposes. Dataflows have different connectors to retrieve data, including databases, Excel files, APIs, and other similar sources, along with data manipulations that are performed using Online Power Query Editor.
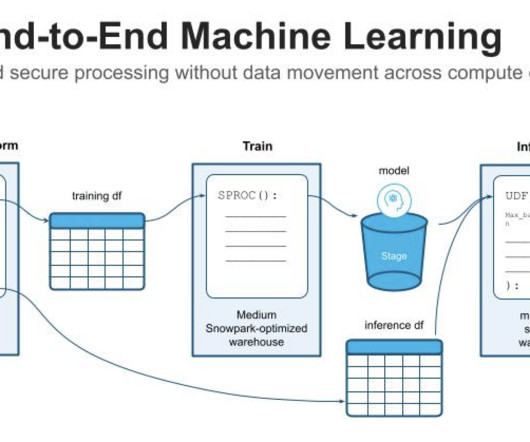
In today’s landscape, AI is becoming a major focus in developing and deploying machinelearningmodels. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
Datapreparation Before creating a knowledge base using Knowledge Bases for Amazon Bedrock, it’s essential to prepare the data to augment the FM in a RAG implementation. He is passionate about cloud and machinelearning.
Credit scoring and decisioning models have been used by financial institutions for many years to predict the risk associated with lending to individuals or entities. However, these models are evolving, with machinelearning now playing an essential role in refining and improving the accuracy and efficiency of credit scoring and decisioning.
Source: [link] Similarly, while building any machinelearning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. You need to make that model available to the end users, monitor it, and retrain it for better performance if needed.
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machinelearning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machinelearning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
Summary: Artificial Intelligence Models as a Service (AIMaaS) provides cloud-based access to scalable, customizable AI models. Businesses can rapidly deploy MachineLearning solutions without extensive infrastructure or expertise, benefiting from cost efficiency and flexibility.
These days enterprises are sitting on a pool of data and increasingly employing machinelearning and deep learning algorithms to forecast sales, predict customer churn and fraud detection, etc., Most of its products use machinelearning or deep learningmodels for some or all of their features.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
In 2020, we released some of the most highly-anticipated features in Tableau, including dynamic parameters , new datamodeling capabilities , multiple map layers and improved spatial support, predictive modeling functions , and Metrics. We continue to make Tableau more powerful, yet easier to use.
It now allows users to clean, transform, and integrate data from various sources, streamlining the Data Analysis process. This eliminates the need to rely on separate tools for datapreparation, saving time and resources. Ensure data consistency and accuracy for trustworthy insights.
However, as your model development process becomes more complex and involves numerous experiments and iterations, keeping track of your progress, managing experiments, and collaborating effectively with team members becomes increasingly challenging. Introducing MLOps Machinelearning (ML) is an essential tool for businesses of all sizes.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Data science / AI / ML leaders: Heads of Data Science, VPs of Advanced Analytics, AI Lead etc. Exploratory data analysis (EDA) and modeling.
LLMOps (Large Language Model Operations), is a specialized domain within the broader field of machinelearning operations (MLOps). LLMOps focuses specifically on the operational aspects of large language models (LLMs). Data Pipeline - Manages and processes various data sources. What is LLMOps? What is MLOps?
Although tabular data are less commonly required to be labeled, his other points apply, as tabular data, more often than not, contains errors, is messy, and is restricted by volume. One might say that tabular datamodeling is the original data-centric AI!
Data Collection The process begins with the collection of relevant and diverse data from various sources. This can include structured data (e.g., databases, spreadsheets) as well as unstructured data (e.g., DataPreparation Once collected, the data needs to be preprocessed and prepared for analysis.
In 2020, we released some of the most highly-anticipated features in Tableau, including dynamic parameters , new datamodeling capabilities , multiple map layers and improved spatial support, predictive modeling functions , and Metrics. We continue to make Tableau more powerful, yet easier to use.
They run scripts manually to preprocess their training data, rerun the deployment scripts, manually tune their models, and spend their working hours keeping previously developed models up to date. Building end-to-end machinelearning pipelines lets ML engineers build once, rerun, and reuse many times.
Check out our five #TableauTips on how we used data storytelling, machinelearning, natural language processing, and more to show off the power of the Tableau platform. . Einstein Discovery in Tableau uses machinelearning (ML) to create models and deliver predictions and recommendations within the analytics workflow.
Check out our five #TableauTips on how we used data storytelling, machinelearning, natural language processing, and more to show off the power of the Tableau platform. . Einstein Discovery in Tableau uses machinelearning (ML) to create models and deliver predictions and recommendations within the analytics workflow.
With these tools in hand, the next challenge is to integrate LLM evaluation into the MachineLearning and Operation (MLOps) lifecycle to achieve automation and scalability in the process. Lastly, evaluation logics define the criteria and metrics used to assess the model’s performance.
Data often arrives from multiple sources in inconsistent forms, including duplicate entries from CRM systems, incomplete spreadsheet records, and mismatched naming conventions across databases. Data […] These issues slow analysis pipelines and demand time-consuming cleanup.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content