This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It provides high-speed, in-memory data processing capabilities and supports various programming languages like Scala, Java, Python, and R.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable datapipelines.
Skills and knowledge required for big data engineering To thrive as a Big Data Engineer, certain skills and expertise are essential. Familiarity with big data tools Proficiency with big data tools like Apache Hadoop and Apache Spark is vital, as these technologies are key to managing extensive datasets efficiently.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. This ensures that the data is accurate, consistent, and reliable.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? and Pandas or Apache Spark DataFrames. Can you render audio/video?
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala. And you should have experience working with big data platforms such as Hadoop or Apache Spark.
Machine Learning projects evolve rapidly, frequently introducing new data , models, and hyperparameters. Hydra is a powerful Python-based configuration management framework designed to simplify the complexities of handling configurations in Machine Learning (ML) workflows and other projects. What is Hydra?
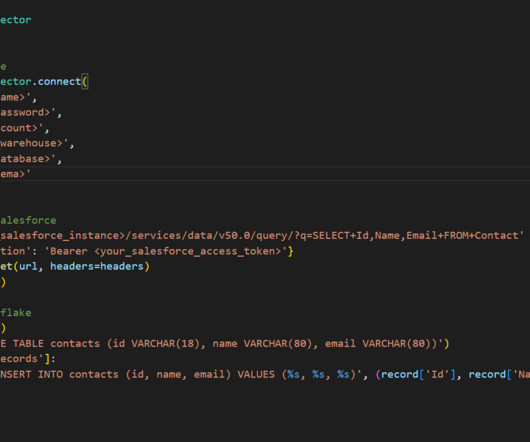
Here’s an example of code that can be used to extract Salesforce data and load it into Snowflake using Python: 2. Third-Party Tools Third-party tools like Matillion or Fivetran can help streamline the process of ingesting Salesforce data into Snowflake.
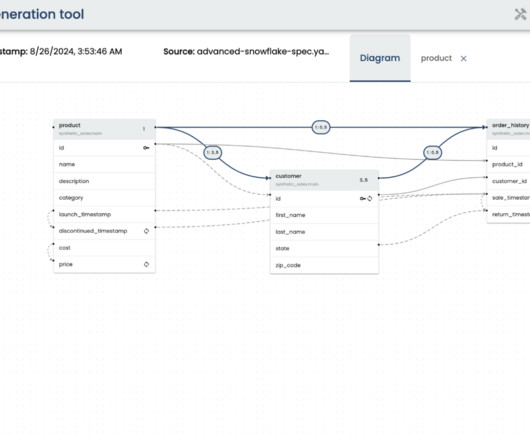
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
Production App - Build resilient and modular production pipelines with automation, scale, testing, observability, versioning, security, risk handling, etc. Monitoring - Monitor all resources, data, model and application metrics to ensure performance. This helps cleanse the data.
Data Engineering Career: Unleashing The True Potential of Data Problem-Solving Skills Data Engineers are required to possess strong analytical and problem-solving skills to navigate complex data challenges. Understanding these fundamentals is essential for effective problem-solving in data engineering.
It even offers a user-friendly interface to visualize the pipelines and monitor progress. Airflow is entirely in Python, so it’s relatively easy for those with some Python experience to get started using it. Aside from migrations, Data Source is also great for data quality checks and can generate datapipelines.
Though scripted languages such as R and Python are at the top of the list of required skills for a data analyst, Excel is still one of the most important tools to be used. Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has.
Data can change a lot, models may also quickly evolve and dependencies become old-fashioned which makes it hard to maintain consistency or reproducibility. With weak version control, teams could face problems like inconsistent data, model drift , and clashes in their code.
IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Key Features: Graphical Framework: Allows users to design datapipelines with ease using a graphical user interface. Read Further: Azure Data Engineer Jobs.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
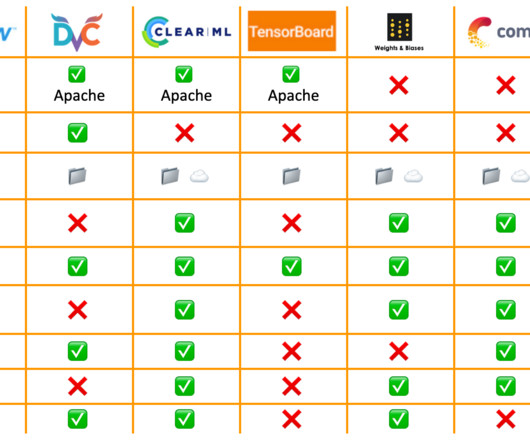
The Git integration means that experiments are automatically reproducible and linked to their code, data, pipelines, and models. With DVC, we don't need to rebuild previous models or datamodeling techniques to achieve the same past state of results.
In one shop we built out one story for each function and used that to gain support and propel the idea of data governance forward. IT , at times, may seem to think that they drive data governance. And for good rason: many data governance jobs postings seek skills like Python, programming skills, etc.
Similar to TensorFlow, PyTorch is also an open-source tool that allows you to develop deep learning models for free. Scikit-learn Scikit-learn is a machine learning library in Python that is majorly used for data mining and data analysis. It is an open-source tool that is free to use without any licensing costs.
The reason is that most teams do not have access to a robust data ecosystem for ML development. billion is lost by Fortune 500 companies because of broken datapipelines and communications. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
The reason is that most teams do not have access to a robust data ecosystem for ML development. billion is lost by Fortune 500 companies because of broken datapipelines and communications. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
dustanbower 7 minutes ago | next [–] Location: Virginia, United States Remote: Yes (have worked exclusively remotely for past 14 years) Willing to relocate: No I've been doing backend work for the past 14 years, with Python, Django, and Django REST Framework. Interested in Python work or full-stack with Python.
Good at Go, Kubernetes (Understanding how to manage stateful services in a multi-cloud environment) We have a Python service in our Recommendation pipeline, so some ML/Data Science knowledge would be good. Data extraction and massage, delivery to destinations like Google/Meta/TikTok/etc.
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages.
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for data scientist to remain competitive in the market. Programming expertise: A medium/high proficiency in Python and SQL is enough.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content