This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
According to IDC , 83% of CEOs want their organizations to be more data-driven. Datascientists could be your key to unlocking the potential of the Information Revolution—but what do datascientists do? What Do DataScientists Do? Datascientists drive business outcomes.
These massive storage pools of data are among the most non-traditional methods of data storage around and they came about as companies raced to embrace the trend of Big Data Analytics which was sweeping the world in the early 2010s. The First Problem – Data Ingestion. The Third Problem – Preparation of Data.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Can you see the complete model lineage with data/models/experiments used downstream?
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificial intelligence (AI) applications.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. Saurabh Gupta is a Principal Engineer at Zeta Global.
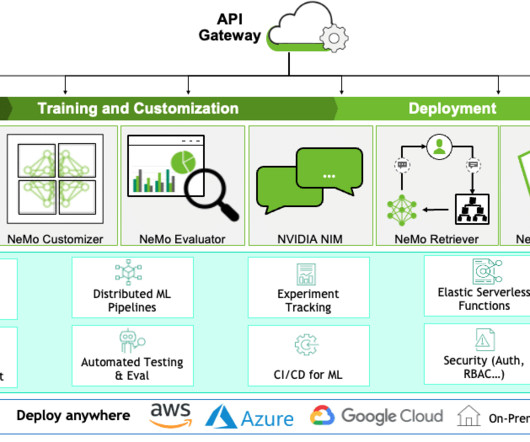
The blog is based on the webinar Deploying Gen AI in Production with NVIDIA NIM & MLRun with Amit Bleiweiss, Senior DataScientist at NVIDIA, and Yaron Haviv, co-founder and CTO and Guy Lecker, ML Engineering Team Lead at Iguazio (acquired by McKinsey). Ensuring data security, lineage and risk controls.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Making data engineering more systematic through principles and tools will be key to making AI algorithms work.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Datascientists frame the business problem and the objective into a statistical solution and start with the very first step of data exploration. Team composition The team comprises domain experts, data engineers, datascientists, and ML engineers.
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for datascientists. ArangoDB is designed to be scalable, reliable, and easy to use.
It brings together business users, datascientists , data analysts, IT, and application developers to fulfill the business need for insights. DataOps then works to continuously improve and adjust datamodels, visualizations, reports, and dashboards to achieve business goals. Using DataOps to Empower Users.
Data quality is ownership of the consuming applications or data producers. Governance The two key areas of governance are model and data: Model governance Monitor model for performance, robustness, and fairness. Model versions should be managed centrally in a model registry.
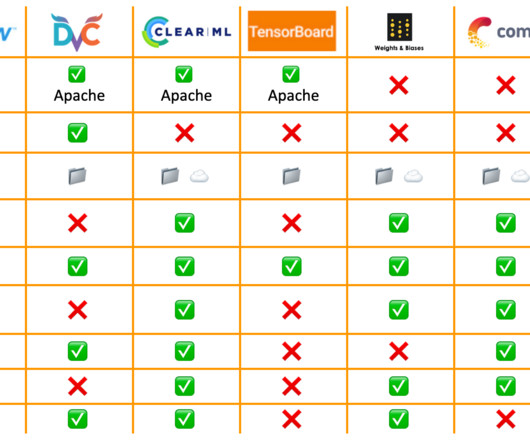
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. It does not support the ‘dvc repro’ command to reproduce its datapipeline.
Production App - Build resilient and modular production pipelines with automation, scale, testing, observability, versioning, security, risk handling, etc. Monitoring - Monitor all resources, data, model and application metrics to ensure performance. This helps cleanse the data.
Data Engineering Career: Unleashing The True Potential of Data Problem-Solving Skills Data Engineers are required to possess strong analytical and problem-solving skills to navigate complex data challenges. Understanding these fundamentals is essential for effective problem-solving in data engineering.
data sources or simpler datamodels) of the data products we want to build? Answering these questions allows datascientists to develop useful data products that start out simple and can be improved and made more complex over time until the long-term vision is achieved. What are the dependencies (e.g.
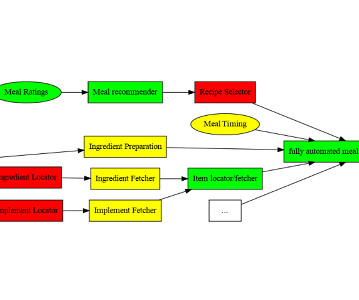
Data engineers, datascientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. LLMOps is MLOps for LLMs.
Though just about every industry imaginable utilizes the skills of a data-focused professional, each has its own challenges, needs, and desired outcomes. This is why you’ll often find that there are jobs in AI specific to an industry, or desired outcome when it comes to data. So, what are you waiting for?
It helps datascientists keep track of their experiments, reproduce their results, and collaborate with others effectively. Experiment tracking tools enable us to log experiment metadata, such as hyperparameters, dataset/code versions, and model performance metrics. This is where ML experiment tracking comes into play!
This collaboration of ML and operations teams is what you call MLOps and focuses on streamlining the process of deploying the ML models to production, along with maintaining and monitoring them. Model Training Frameworks This stage involves the process of creating and optimizing the predictive models with labeled and unlabeled data.
Features and Capabilities of Time Series Databases TSDBs offer a rich set of functionalities that empower developers and datascientists to effectively manage and analyse time series data. Here are some key features: High-performance Write and Read Operations TSDBs are optimised for rapid data ingestion and retrieval.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. billion is lost by Fortune 500 companies because of broken datapipelines and communications.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. billion is lost by Fortune 500 companies because of broken datapipelines and communications.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for datascientists.
Enter dbt dbt provides SQL-centric transformations for your datamodeling and transformations, which is efficient for scrubbing and transforming your data while being an easy skill set to hire for and develop within your teams. It should also enable easy sharing of insights across the organization.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a data engineering team as one of the first engineers. We were focused on building datapipelines and models to protect our users from malicious phonecalls. "[1] type problems.
Designing AI datapipelines to process billions of data points. Open roles include: • Senior ML/Data Engineers • Senior AI Consultants • Senior AI Project Managers • Industry Directors • Junior ML/Data Engineers and many more! We have PMF, and it's time to scale!
The platform typically includes components for the ML ecosystem like data management, feature stores, experiment trackers, a model registry, a testing environment, model serving, and model management. They include: 1 Data (or input) pipeline. 2 Model (or training) pipeline.
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for datascientist to remain competitive in the market. Coding skills remain important, but the real value of datascientists today is shifting.
This includes responsible AI, Gartners concept of AI TRiSM (Trust, Risk and Security in AI Models) and Sovereign AI. AI engineering - AI is being democratized for developers and engineers, expanding beyond the limited pool of datascientists. AI Agents and multi-agent systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content