This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The data repository should […]. The post Basics of DataModeling and Warehousing for Data Engineers appeared first on Analytics Vidhya. Even asking basic questions like “how many customers we have in some places,” or “what product do our customers in their 20s buy the most” can be a challenge.
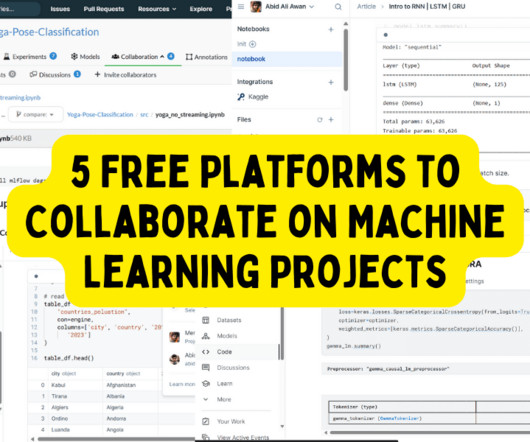
Collaborating on a machinelearning project is a bit different from collaborating on a traditional software project. In a machinelearning project, engineers are working with data, models, and source code. Additionally, they are also sharing features, model experiment results, and pipelines.
Data, undoubtedly, is one of the most significant components making up a machinelearning (ML) workflow, and due to this, data management is one of the most important factors in sustaining ML pipelines.
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on June 11, 2025 in Language Models Image by Author | Canva If you work in a data-related field, you should update yourself regularly. Data scientists use different tools for tasks like data visualization, datamodeling, and even warehouse systems.
Data Scientist Data scientists are responsible for designing and implementing datamodels, analyzing and interpreting data, and communicating insights to stakeholders. They require strong programming skills, knowledge of statistical analysis, and expertise in machinelearning.
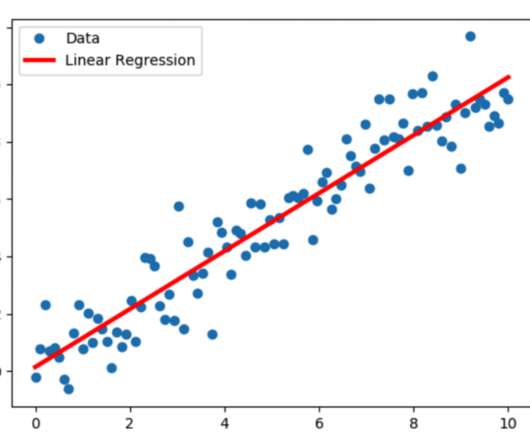
This article was published as a part of the Data Science Blogathon. Introduction Regression problems are prevalent in machinelearning, and regression analysis is the most often used technique for solving them.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Key Skills: Mastery in machinelearning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods.
Data splitting is a fundamental technique in the field of machinelearning and data science that allows practitioners to evaluate and improve the performance of their models. Understanding the intricacies of data splitting can significantly influence the robustness and reliability of predictive models.
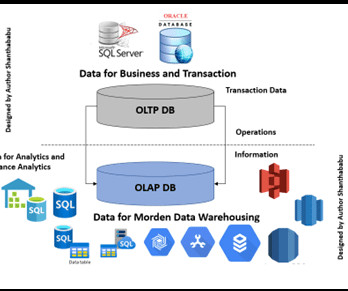
Traditional vs vector databases Datamodels Traditional databases: They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. Hence, the data is well-organized and maintains a well-defined relationship between different entities.
To be successful with a graph database—such as Amazon Neptune, a managed graph database service—you need a graph datamodel that captures the data you need and can answer your questions efficiently. Building that model is an iterative process.
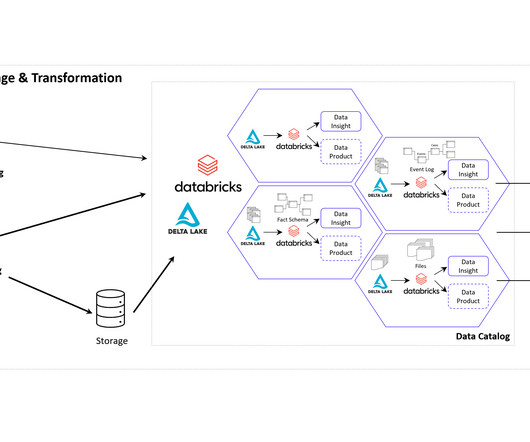
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Applications of BI, Data Science and Process Mining grow together More and more all these disciplines are growing together as they need to be combined in order to get the best insights. So while Process Mining can be seen as a subpart of BI while both are using MachineLearning for better analytical results.
Summary: Hydra simplifies process configuration in MachineLearning by dynamically managing parameters, organising configurations hierarchically, and enabling runtime overrides. As the global MachineLearning market, valued at USD 35.80 These issues can hinder experimentation, reproducibility, and workflow efficiency.
Data science platforms are reshaping the landscape of how organizations harness data to drive insights and foster innovation. By providing a comprehensive ecosystem for data professionals, these platforms enhance the capabilities around machinelearning, advanced analytics, and collaborative efforts.
With open open-source machinelearning library, NVIDIA cuML, you can achieve significantly higher speed and scale for dimensionality reduction using UMAP without changing any of your code. cuML brings GPU-acceleration to UMAP and HDBSCAN , in addition to scikit-learn algorithms.
Given that there are so many laptops and laptop configurations out there, we've gone out and found our favorites for data science so you don't have to.
How structured data works Understanding how structured data operates involves recognizing the role of datamodels and repositories. These frameworks facilitate the organization and integrity of data across various applications. They represent the structure and constraints that govern how data is stored.
In technology and business, entities often represent either real objects or abstract concepts, allowing clarification in datamodeling and communication. Named entities and recognition Named entities refer to specific, identifiable units within a set of data, crucial for tasks in data mining and machinelearning applications.
Mechanics of data virtualization Understanding how data virtualization works reveals its benefits in organizations. Middleware role Data virtualization often functions as middleware that bridges various datamodels and repositories, including cloud data lakes and on-premise warehouses.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machinelearning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
Machinelearning (ML) has enabled a whole host of innovations and new business models in fintech, driving breakthroughs in areas such as personalized wealth management, automated fraud detection, and real-time small business accounting tools.
They dive deep into artificial neural networks, algorithms, and data structures, creating groundbreaking solutions for complex issues. These professionals venture into new frontiers like machinelearning, natural language processing, and computer vision, continually pushing the limits of AI’s potential.
Source: Author Introduction Machinelearningmodel monitoring tracks the performance and behavior of a machinelearningmodel over time. Organizations can ensure that their machine-learningmodels remain robust and trustworthy over time by implementing effective model monitoring practices.
Today, we officially take the step to combine the data, models, compute, distribution and talent. xAI and Xs futures are intertwined, Musk wrote in a post on X. This combination will unlock immense potential by blending xAIs advanced AI capability and expertise with Xs massive reach.
Data Science is a field that encompasses various disciplines, including statistics, machinelearning, and data analysis techniques to extract valuable insights and knowledge from data. It is divided into three primary areas: data preparation, datamodeling, and data visualization.
Sources of Hallucinations: Generalized Training Data: Models trained on non-specialized data may lack depth in healthcare-specific contexts.Probabilistic Generation: LLMs generate text based on probability, which sometimes leads them to select… Read the full blog for free on Medium.
Shared learning enables models to learn from a diverse range of experiences and perspectives, leading to improved performance ( Image Credit ) What is shared learning? This approach helps the student model benefit from the knowledge and generalization abilities of the larger model.
GPTs for Data science are the next step towards innovation in various data-related tasks. These are platforms that integrate the field of data analytics with artificial intelligence (AI) and machinelearning (ML) solutions. The learning assistance provides deeper insights and improved accuracy.
Data vault is not just a method; its an innovative approach to datamodeling and integration tailored for modern data warehouses. As businesses continue to evolve, the complexity of managing data efficiently has grown. As businesses continue to evolve, the complexity of managing data efficiently has grown.
These skills include programming languages such as Python and R, statistics and probability, machinelearning, data visualization, and datamodeling. These languages are used for data cleaning, manipulation, and analysis, and for building and deploying machinelearningmodels.
By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries. She leads machinelearning projects in various domains such as computer vision, natural language processing, and generative AI.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any data science and machinelearning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
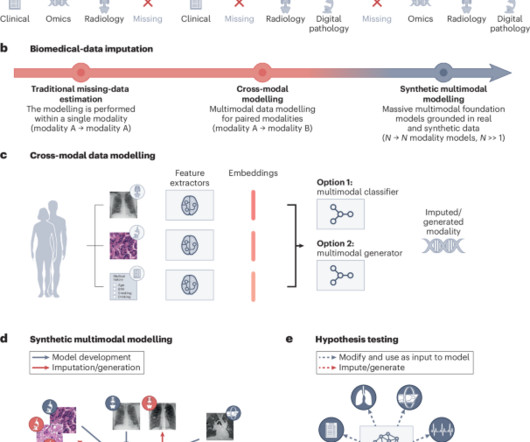
Nature Biomedical Engineering - Foundation models can be advantageously harnessed to estimate missing data in multimodal biomedical datasets and to generate realistic synthetic samples.
In order for us to start using any kind of data logic on this, we need to identify the board location first. Author(s): Ashutosh Malgaonkar Originally published on Towards AI. Here is how tic tac toe looks. So, let us figure out a system to determine board location.
Additionally, consider exploring other AWS services and tools that can complement and enhance your AI-driven applications, such as Amazon SageMaker for machinelearningmodel training and deployment, or Amazon Lex for building conversational interfaces. He is passionate about cloud and machinelearning.
First, the amount of data available to organizations has grown exponentially in recent years, creating a need for professionals who can make sense of it. Second, advancements in technology, such as big data and machinelearning, have made it easier and more efficient to analyze data.
The rise of machinelearning and the use of Artificial Intelligence gradually increases the requirement of data processing. That’s because the machinelearning projects go through and process a lot of data, and that data should come in the specified format to make it easier for the AI to catch and process.
With Bitcoin surpassing $87,000 in March 2025, AI and data science have become essential tools in crypto trading, enabling the extraction of meaningful insights from complex market data. AI models used in Bitcoin prediction Different AI models adapt to continuously emerging needs and features of crypto markets.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content