This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Imperva Cloud WAF protects hundreds of thousands of websites against cyber threats and blocks billions of security events every day. Counters and insights based on security events are calculated daily and used by users from multiple departments. The data is stored in a datalake and retrieved by SQL using Amazon Athena.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Now, we can save the data as delta tables to use later for sales analytics.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. earthquake, flood, or fire), where the data collected does not need to be as tightly controlled.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Although setting up a database to run your analyses may seem like an arduous task, modern open-source time series databases can provide significant benefits to any scientist running time series analysis on a large data set — and with much less effort than you might imagine. Interested in attending an ODSC event?
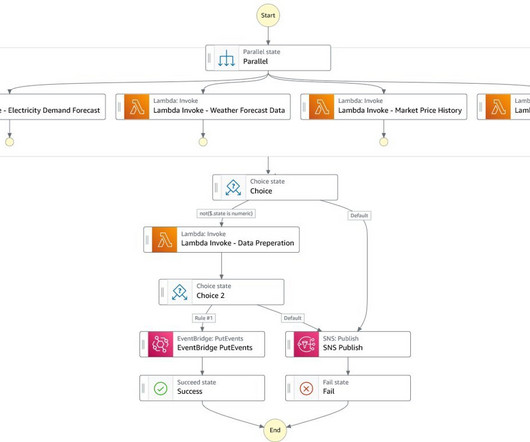
Recent events including Tropical Cyclone Gabrielle have highlighted the susceptibility of the grid to extreme weather and emphasized the need for climate adaptation with resilient infrastructure. The model is then trained using a fully managed infrastructure, validated, and published to the Amazon SageMaker Model Registry.
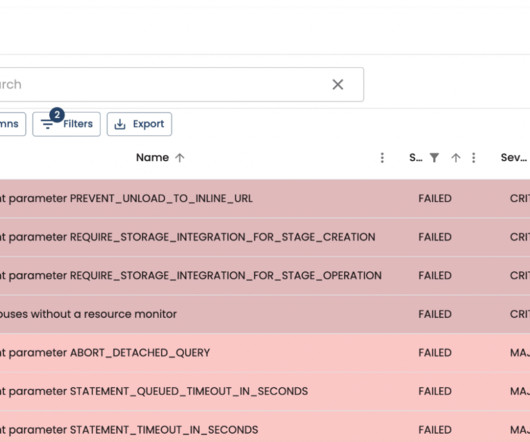
Depending on the requirement, it is important to choose between transient and permanent tables, as well as data recovery needs and downtime considerations. We can set the STATEMENT_TIMEOUT_IN_SECONDS parameter to define the maximum time a SQL statement can run before it is canceled.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
One of the main drivers for this problem is that most analytic systems are built within the context of a unified SQL environment. Getting all the data together, in one place, and integrated is generally the main goal of ourwork. Unfortunately in analytic systems, we have been doing little other than tight coupling for decades.
Configure the following scopes on your connected app: Manage user data via APIs ( api ). Perform ANSI SQL queries on Salesforce Data Cloud data (Data Cloud_query_api ). Manage Data Cloud profile data ( Data Cloud_profile_api ). Drag and drop the file, then choose Edit in SQL.
With the recently launched Amazon Monitron Kinesis data export v2 feature , your OT team can stream incoming measurement data and inference results from Amazon Monitron via Amazon Kinesis to AWS Simple Storage Service (Amazon S3) to build an Internet of Things (IoT) datalake. The latest version of Firefox or Chrome.
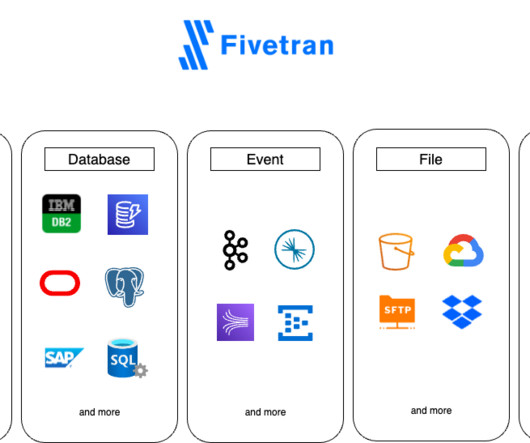
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
Apache Spark Apache Spark is a unified analytics engine for Big Data processing, with built-in modules for streaming, SQL, Machine Learning , and graph processing. Key Features : Speed : Spark processes data in-memory, making it up to 100 times faster than Hadoop MapReduce in certain applications.
We had bigger sessions on getting started with machine learning or SQL, up to advanced topics in NLP, and how to make deepfakes. Expo Hall ODSC events are more than just data science training and networking events. Top Sessions With sessions both online and in-person in Boston, there was something for everyone.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
The DataRobot AI Platform seamlessly integrates with Azure cloud services, including Azure Machine Learning, Azure DataLake Storage Gen 2 (ADLS), Azure Synapse Analytics, and Azure SQL database. DATAROBOT LAUNCH EVENT From Vision to Value. For more information, visit [link].
Data collection and ingestion The data collection and ingestion layer connects to all upstream data sources and loads the data into the datalake. Amazon Athena to provide developers and business analysts SQL access to the generated data for analysis and troubleshooting.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
Example: models: my_project: events: # materialize all models in models/events as tables +materialized: table csvs: # this is redundant, and does not need to be set +materialized: view We can also configure the materialization type inside the dbt SQL file or the yaml file. This is done via a create view statement.
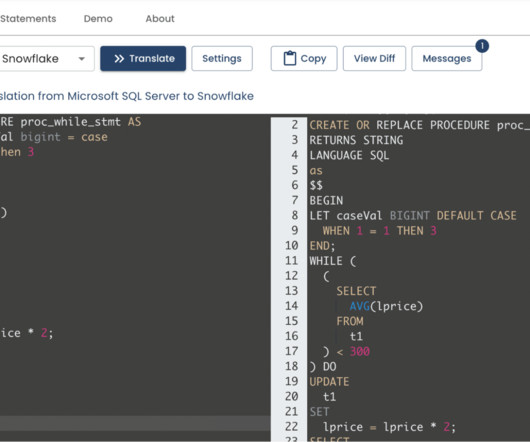
The tool converts the templated configuration into a set of SQL commands that are executed against the target Snowflake environment. Replicate can interact with a wide variety of databases, data warehouses, and datalakes (on-premise or based in the cloud). It is also a helpful tool for learning a new SQL dialect.
Select the uploaded file and from Actions dropdown and choose the Query with S3 Select option to query the.csv data using SQL if the data was loaded correctly. In this demonstration, let’s assume that you need to remove the data related to a particular customer.
LakeFS LakeFS is an open-source platform that provides datalake versioning and management capabilities. It sits between the datalake and cloud object storage, allowing you to version and control changes to datalakes at scale. Notebook for interactive Python, SQL, and R editors for coding data pipelines.
They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. These professionals will work with their colleagues to ensure that data is accessible, with proper access. The reason this is an important skill is that ETL is a critical process for data warehousing and business intelligence.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Data warehousing is a vital constituent of any business intelligence operation.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. This text has a lot of information, but it is not structured.
NoSQL Databases These databases, such as MongoDB, Cassandra, and HBase, are designed to handle unstructured and semi-structured data, providing flexibility and scalability for modern applications. Understanding the differences between SQL and NoSQL databases is crucial for students.
For instance, differential privacy adds noise to query results as a means of preventing access to Personally Identifiable Information (PII) and running multi-party computations directly on encrypted data. Object Tagging Tags are schema-level objects that allow data stewards to monitor sensitive data for compliance, protection, or discovery.
Why External Tables are Important Data Ingestion: External tables allow you to easily load data into Snowflake from various external data sources without the need to first stage the data within Snowflake. Data Integration: Snowflake supports seamless integration with other data processing systems and datalakes.
Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage. Key features and benefits of Azure for Data Science include: Scalability: Easily scale resources up or down based on demand, ideal for handling large datasets and complex computations.
What Are the Best Third-Party Data Ingestion Tools for Snowflake? Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake. To help you make your choice, here are the ones we consider to be the best.
Data pipeline orchestration. Support for languages and SQL. Moving/integrating data in the cloud/data exploration and quality assessment. Supports the ability to interact with the actual data and perform analysis on it. Pushing data to a datalake and assuming it is ready for use is shortsighted.
The service will consume the features in real time, generate predictions in near real-time , such as in an event processing pipeline, and write the outputs to a prediction queue. I have worked with customers where R and SQL were the first-class languages of their data science community. Data engineers are mostly in charge of it.
One of the hardest things about MLOps today is that a lot of data scientists aren’t native software engineers, but it may be possible to lower the bar to software engineering. And so those are more sideshows of the conversations or other complementary pieces, maybe. Thank you for sharing that, David.
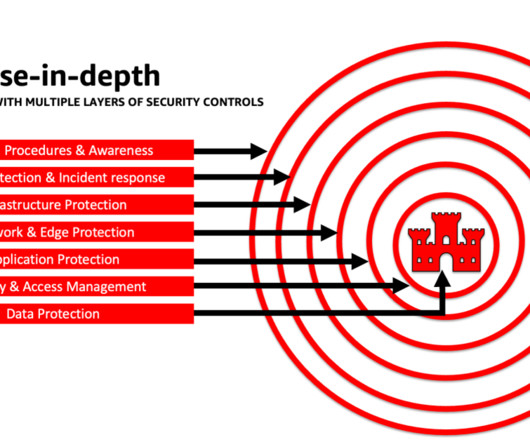
Plan for rollback and recovery from production security events and service disruptions such as prompt injection, training data poisoning, model denial of service, and model theft early on, and define the mitigations you will use as you define application requirements.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content