This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. Disruptive Trend #1: Hadoop.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
Look for features such as scalability (the ability to handle growing datasets), performance (speed of processing), ease of use (user-friendly interfaces), integration capabilities (compatibility with existing systems), security measures (data protection features), and pricing models (licensing costs). Use Cases : Yahoo!
Lake File System ( LakeFS for short) is an open-source version control tool, launched in 2020, to bridge the gap between version control and those big data solutions (datalakes). It provides ACID transactions, scalable metadata management, and schema enforcement to datalakes.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
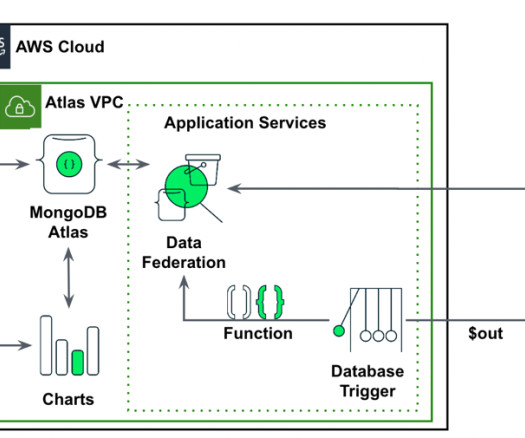
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns. Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs.
External Data Sources: These can be market research data, social media feeds, or third-party databases that provide additional insights. Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions.
It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content