This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
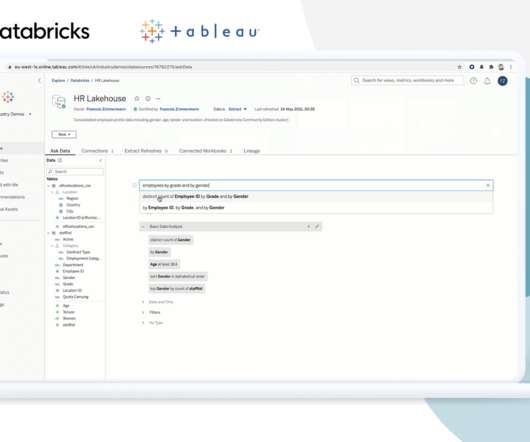
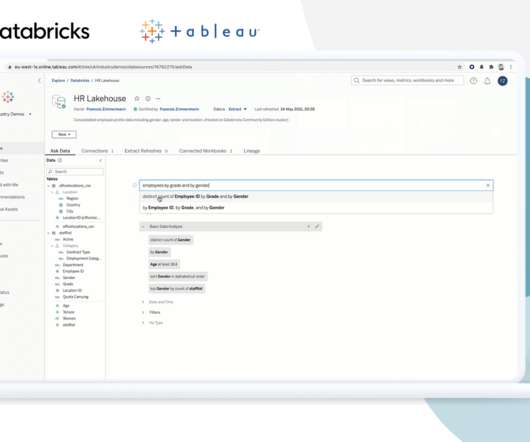
When it comes to data, there are two main types: datalakes and datawarehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Enter AnalyticsCreator AnalyticsCreator, a powerful tool for data management, brings a new level of efficiency and reliability to the CI/CD process. It offers full BI-Stack Automation, from source to datawarehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models.
A unified SQL query interface and portable runtime to locally materialize, accelerate, and query data tables sourced from any database, datawarehouse, or datalake. spiceai/spiceai
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Separation of storage and compute : Lakebases store their data in modern datalakes (object stores) in open formats, which enables scaling compute and storage separately, leading to lower TCO and eliminating lock-in. At zero, the cost of the lakebase is just the cost of storing the data on cheap datalakes.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Now, we can save the data as delta tables to use later for sales analytics.
Discover the nuanced dissimilarities between DataLakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and DataWarehouses. It acts as a repository for storing all the data.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use datawarehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. option("multiLine", "true").option("header",
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQL Database connector and an Azure DataLake Storage Gen2 connector. As our customers increasingly adopt the cloud, we continue to make investments that ensure they can access their data anywhere. March 30, 2021.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
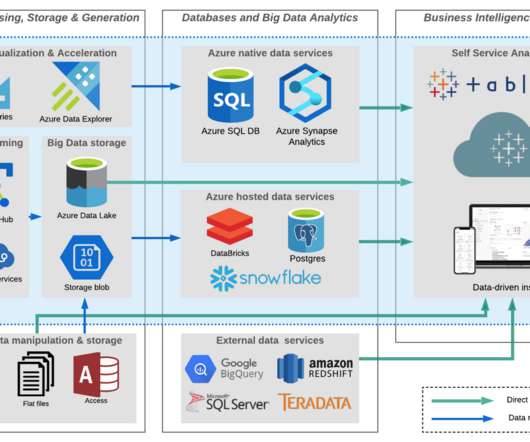
Azure Synapse Analytics can be seen as a merge of Azure SQLDataWarehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Azure Synapse. I think this announcement will have a very large and immediate impact.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
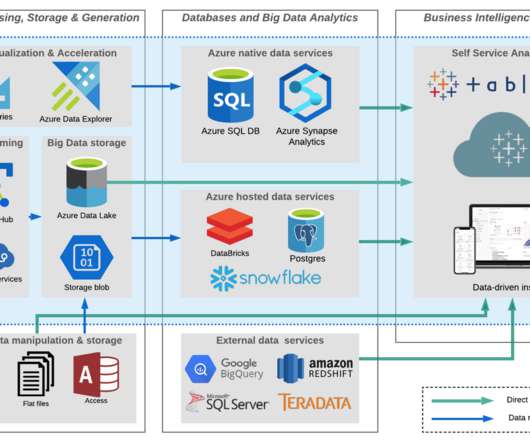
Now they can access databases and datawarehouses, as well as unstructured business data, like emails, reports, charts, graphs, and images. Access all your data whether its stored in datalakes, datawarehouses, third-party or federated data sources.
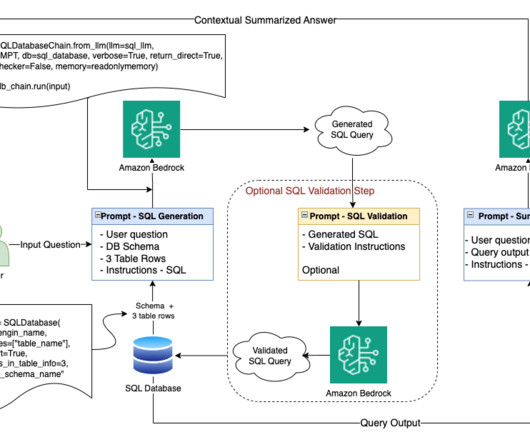
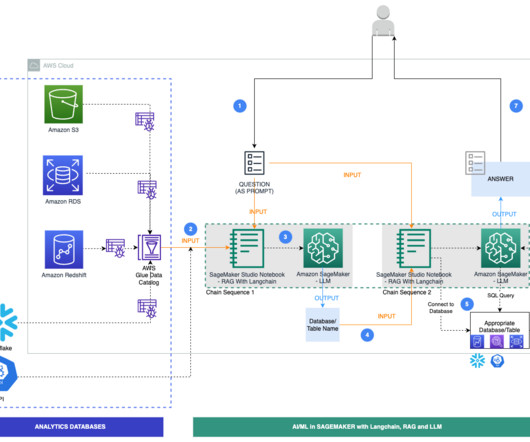
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQL Database connector and an Azure DataLake Storage Gen2 connector. As our customers increasingly adopt the cloud, we continue to make investments that ensure they can access their data anywhere. March 30, 2021.
Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. What is Presto?
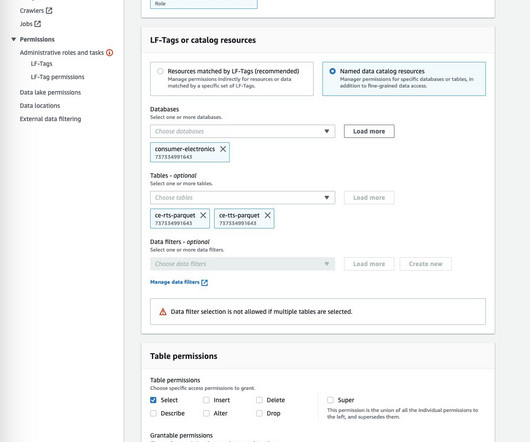
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. This means that business analysts who want to extract insights from the large volumes of data in their datawarehouse must frequently use data stored in Parquet.
One of the main drivers for this problem is that most analytic systems are built within the context of a unified SQL environment. Getting all the data together, in one place, and integrated is generally the main goal of ourwork. Unfortunately in analytic systems, we have been doing little other than tight coupling for decades.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
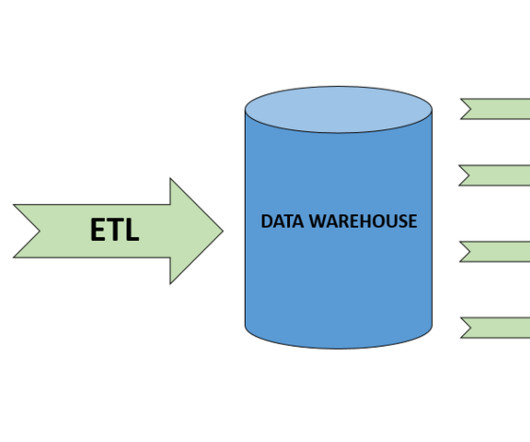
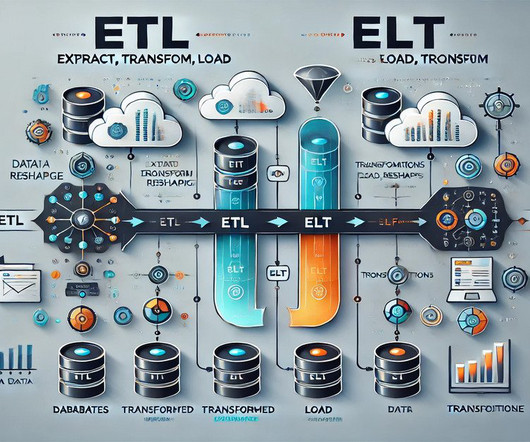
It is a crucial data integration process that involves moving data from multiple sources into a destination system, typically a datawarehouse. This process enables organisations to consolidate their data for analysis and reporting, facilitating better decision-making. ETL stands for Extract, Transform, and Load.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. Data lakehouse was created to solve these problems.
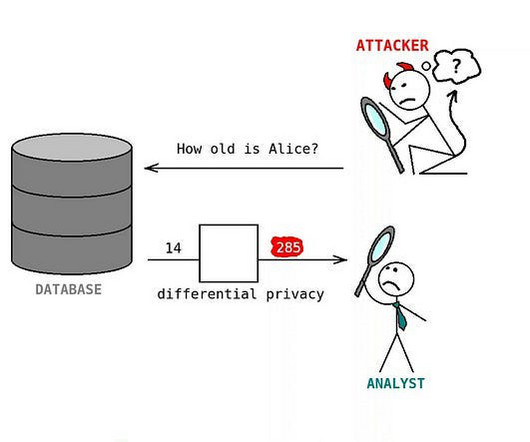
How you now anonymize Data more easily Photo by Dušan veverkolog on Unsplash Google has just announced the public preview of BigQuery differential privacy with SQL building blocks. You can use these functions to anonymize their data. Hence, with this feature you can also ensure that data is shared there securely.
With Great Expectations , data teams can express what they “expect” from their data using simple assertions. Great Expectations provides support for different data backends such as flat file formats, SQL databases, Pandas dataframes and Sparks, and comes with built-in notification and data documentation functionality.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
They all agree that a Datamart is a subject-oriented subset of a datawarehouse focusing on a particular business unit, department, subject area, or business functionality. The Datamart’s data is usually stored in databases containing a moving frame required for data analysis, not the full history of data.
Whether you’re running small-scale analytics or managing enterprise-level datawarehouses, these tips will help drive performance and meaningful business outcomes for your organization. Storage Costs Our first tip involves taking a closer look at managing how your data is stored, organized, and accessed.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, datalakes, datawarehouses and SQL databases, providing a holistic view into business performance. Then, it applies these insights to automate and orchestrate the data lifecycle.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses.
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Oracle – The Oracle connector, a database-type connector, enables real-time data transfer of large volumes of data from on-premises or cloud sources to the destination of choice, such as a cloud datalake or datawarehouse.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and datalakes.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content