This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering DataScience Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
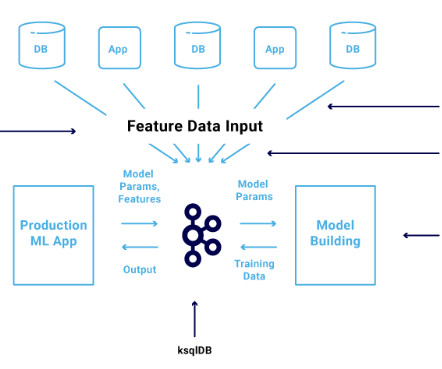
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Now, we can save the data as delta tables to use later for sales analytics.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
Most data scientists are familiar with the concept of time series data and work with it often. The time series database (TSDB) , however, is still an underutilized tool in the datascience community. Typically, time series analysis is performed either on CSV files or datalakes.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
AI integration: Employing artificial intelligence for automation in response to unexpected events. Diagnostic analytics Diagnostic analytics focuses on understanding the causes behind past events. It analyzes data to uncover reasons for occurrences, closely related to descriptive analytics for a comprehensive view.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. Instead, use Prefect where interactive workflows are now natively supported. See them here!
They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a data engineer.
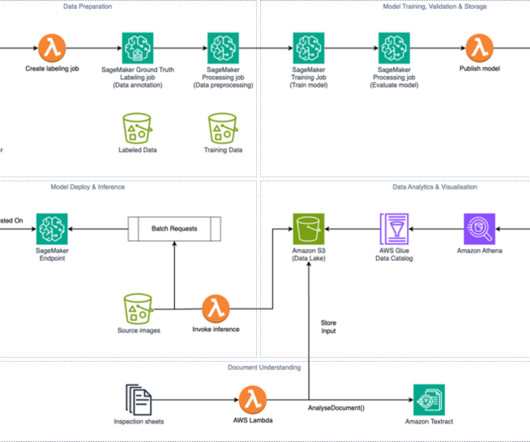
Recent events including Tropical Cyclone Gabrielle have highlighted the susceptibility of the grid to extreme weather and emphasized the need for climate adaptation with resilient infrastructure. The model is then trained using a fully managed infrastructure, validated, and published to the Amazon SageMaker Model Registry.
Learn about cutting-edge developments in AI and datascience from the experts who know them best on ODSC’s Ai X Podcast. Beyond his technical achievements, James is a sought-after speaker and is a prolific voice in the data community through his blog, JamesSerra.com. Interested in attending an ODSC event?
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
Data Engineer Data engineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, datalakes, and big data technologies to build and maintain data pipelines. Interested in attending an ODSC event?
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. Ensure that data is clean, consistent, and up-to-date.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
Imperva Cloud WAF protects hundreds of thousands of websites against cyber threats and blocks billions of security events every day. Counters and insights based on security events are calculated daily and used by users from multiple departments. The data is stored in a datalake and retrieved by SQL using Amazon Athena.
The week was filled with engaging sessions on top topics in datascience, innovation in AI, and smiling faces that we haven’t seen in a while. Expo Hall ODSC events are more than just datascience training and networking events. You can read the recap here and watch the full keynote here. What’s next?
They are working through organizational design challenges while also establishing foundational data management capabilities like metadata management and data governance that will allow them to offer trusted data to the business in a timely and efficient manner for analytics and AI.”
This is a pretty important job as once the data has been integrated, it can be used for a variety of purposes, such as: Reporting and analytics Business intelligence Machine learning Data mining All of this provides stakeholders and even their own teams with the data they need when they need it.
The two most prominent implementations are dbt Model Contracts , and the Open Data Contract Standard (ODCS, not to be confused withODSC. Sample dbt ModelContract Essentially, both solutions are JSON schema (widely used in APIs and event models), and thankfully, expressed in YAML for the ease of human typing.
Data Pipeline Architecture — Stop Building Monoliths Elliott Cordo | Founder, Architect, Builder | Datafutures Although common, data monoliths present several challenges, especially for larger teams and organizations that allow for federated data product development. Interested in attending an ODSC event?
Introducing the Topic Tracks for ODSC East 2024 — Highlighting Gen AI, LLMs, and Responsible AI ODSC East 2024 , coming up this April 23rd to 25th, is fast approaching and this year we will have even more tracks comprising hands-on training sessions, expert-led workshops, and talks from datascience innovators and practitioners.
Datascience teams often face challenges when transitioning models from the development environment to production. Usually, there is one lead data scientist for a datascience group in a business unit, such as marketing. ML Dev Account This is where data scientists perform their work.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
A novel approach to solve this complex security analytics scenario combines the ingestion and storage of security data using Amazon Security Lake and analyzing the security data with machine learning (ML) using Amazon SageMaker. Store new security logs in an S3 bucket and queue events in Amazon Simple Queue Service (Amazon SQS).
Time Series Forecasting for Managers — All Forecasts Are Wrong but Some Are Useful Tanvir Ahmed Shaikh | Data Strategist (Director) | Genentech, Inc Time series forecasting remains an under-appreciated technique in datascience education, often overshadowed by more popular machine learning methods.
HPCC Systems — The Kit and Kaboodle for Big Data and DataScience Bob Foreman | Software Engineering Lead | LexisNexis/HPCC Join this session to learn how ECL can help you create powerful data queries through a comprehensive and dedicated datalake platform. Interested in attending an ODSC event?
Building an Effective OSS Management Layer for Your DataLake Ahead of her ODSC West session on OSS management layers, the speaker discusses how datalakes can benefit from this system.
Businesses require Data Scientists to perform Data Mining processes and invoke valuable data insights using different software and tools. What is Data Mining and how is it related to DataScience ? What is Data Mining? Why is Data Mining Important? Let’s learn from the following blog!
Summary: This blog provides a comprehensive roadmap for aspiring Azure Data Scientists, outlining the essential skills, certifications, and steps to build a successful career in DataScience using Microsoft Azure. Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage.
Manager DataScience at Marubeni Power International. Data collection and ingestion The data collection and ingestion layer connects to all upstream data sources and loads the data into the datalake. This construct provides a fully event-driven workflow. He holds a Ph.D.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides datascience and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic datascience concepts to advanced machine learning techniques.
Enterprise data architects, data engineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface.
With the recently launched Amazon Monitron Kinesis data export v2 feature , your OT team can stream incoming measurement data and inference results from Amazon Monitron via Amazon Kinesis to AWS Simple Storage Service (Amazon S3) to build an Internet of Things (IoT) datalake. Choose Create delivery stream.
Databricks Databricks is the developer of Delta Lake, an open-source project that brings reliability to datalakes for machine learning and other cases. Originally posted on OpenDataScience.com Read more datascience articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels!
Set up regular game days to test workload and team responses to simulated events. Learn from all operational failures – Drive improvement through lessons learned from all operational events and failures. By centralizing datasets within the flywheel’s dedicated Amazon S3 datalake, you ensure efficient data management.
We are also building models trained on different types of business data, including code, time-series data, tabular data, geospatial data and IT eventsdata. A data store built on open lakehouse architecture, it runs both on premises and across multi-cloud environments.
Amazon Simple Storage Service (Amazon S3) object storage acts as a content datalake. TR built processes to securely access data from the content datalake to users’ experimentation workspaces while maintaining required authorization and auditability.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















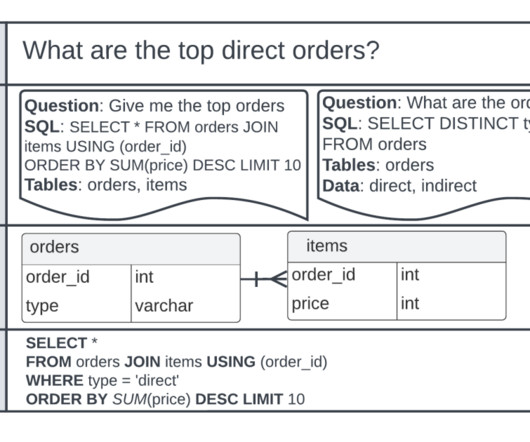






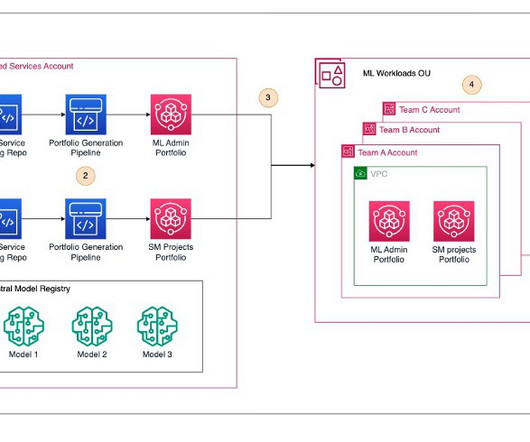

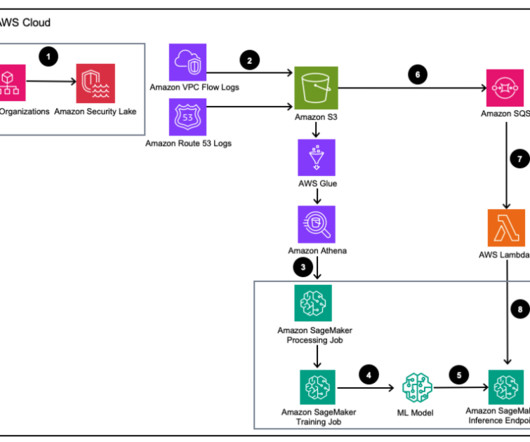





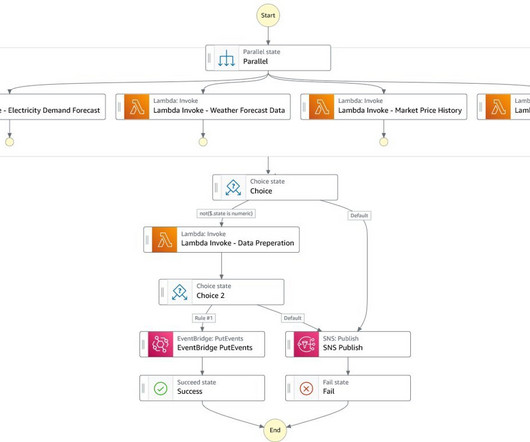












Let's personalize your content