This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Key Skills: Mastery in machinelearning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods.
generally available on May 24, Alation introduces the Open Data Quality Initiative for the modern data stack, giving customers the freedom to choose the data quality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and DataGovernance application.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It integrates well with other Google Cloud services and supports advanced analytics and machinelearning features.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
As firms mature their transformation efforts, applying Artificial Intelligence (AI), machinelearning (ML) and Natural Language Processing (NLP) to the data is key to putting it into action quickly and effecitvely. Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Cloud-based business intelligence (BI): Cloud-based BI tools enable organizations to access and analyze data from cloud-based sources and on-premises databases. Machinelearning and AI analytics: Machinelearning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
The importance of big data management Efficient big data management is crucial for organizations to: Leverage analytics: Improved analytics enable businesses to make better-informed decisions. Maintain competitive advantage: Data-driven strategies help organizations stay ahead in their industries.
View the execution status and details of the workflow by fetching the state machine Amazon Resource Name (ARN) from the CloudFormation stack. His mission is to enable customers achieve their business goals and create value with data and AI.
As firms mature their transformation efforts, applying Artificial Intelligence (AI), machinelearning (ML) and Natural Language Processing (NLP) to the data is key to putting it into action quickly and effecitvely. Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machinelearning models relies on much more than selecting the best algorithm for the job. A machinelearning workflow refers to the sequence of steps or tasks involved in the entire process of building a machinelearning model.
MachineLearning Experience is a Must. By 2020, over 40 percent of all data science tasks will be automated. Machinelearning technology and its growing capability is a huge driver of that automation. Professionals adept at this skill will be desirable by corporations, individuals and government offices alike.
Unstructured data makes up 80% of the world's data and is growing. Managing unstructured data is essential for the success of machinelearning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. Unstructured.io
Creating data pipelines and workflows Data engineers create data pipelines and workflows that enable data to be collected, processed, and analyzed efficiently. By creating efficient data pipelines and workflows, data engineers enable organizations to make data-driven decisions quickly and accurately.
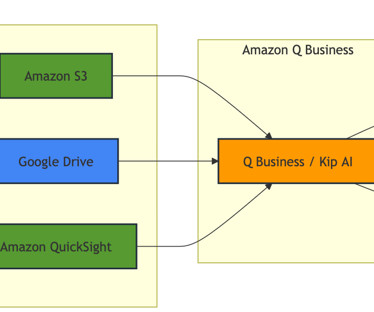
We use multiple data sources, including Amazon S3 for our storage needs, Amazon QuickSight for our business intelligence requirements, and Google Drive for team collaboration. Noah Kershaw leads the product team at Kepler Group, a global digital marketing agency that helps brands connect with their audiences through data-driven strategies.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
Data democratization instead refers to the simplification of all processes related to data, from storage architecture to data management to data security. It also requires an organization-wide datagovernance approach, from adopting new types of employee training to creating new policies for data storage.
In particular, its progress depends on the availability of related technologies that make the handling of huge volumes of data possible. These technologies include the following: Datagovernance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve data quality, and support Advanced Analytics like MachineLearning. Aggregation : Combining multiple data points into a single summary (e.g.,
Regular Data Audits Conduct regular data audits to identify issues and discrepancies. This proactive approach allows you to detect and address problems before they compromise data quality. DataGovernance Framework Implement a robust datagovernance framework.
Key Takeaways Data Engineering is vital for transforming raw data into actionable insights. Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering?
Data integration and automation To ensure seamless data integration, organizations need to invest in data integration and automation tools. These tools enable the extraction, transformation, and loading (ETL) of data from various sources.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machinelearning (ML) from weeks to minutes. In this post, we show how to use Lake Formation as a central datagovernance capability and Amazon EMR as a big data query engine to enable access for SageMaker Data Wrangler.
Based on the McKinsey survey , 56% of orgs today are using machinelearning in at least one business function. AWS Sagemeaker is in fact a great tool for machinelearning operations (MLOps) to automate and standardize processes across the ML lifecycle. This includes data quality, privacy, and compliance.
Data Integration A data pipeline can be used to gather data from various disparate sources in one data store. This makes it easier to compare and contrast information and provides organizations with a unified view of their data. A good datagovernance framework will often minimize manual processes to avoid latency.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machinelearning to responsible AI. With that said, each skill may be used in a different manner.
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. It covers essential topics such as SQL queries, data visualization, statistical analysis, machinelearning concepts, and data manipulation techniques.
Data Integration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis. Understanding ETL (Extract, Transform, Load) processes is vital for students. Students should learn how to apply machinelearning models to Big Data.
With all data in one place, businesses can break down data silos and gain holistic insights. Enablement of Advanced Analytics The raw and unprocessed nature of data in a Data Lake makes it an ideal environment for advanced analytics and machinelearning. What Is a Data Warehouse?
Snowflake enables organizations to instantaneously scale to meet SLAs with timely delivery of regulatory obligations like SEC Filings, MiFID II, Dodd-Frank, FRTB, or Basel III—all with a single copy of data enabled by data sharing capabilities across various internal departments.
The main goal of a data mesh structure is to drive: Domain-driven ownership Data as a product Self-service infrastructure Federated governance One of the primary challenges that organizations face is datagovernance.
A unified data fabric also enhances data security by enabling centralised governance and compliance management across all platforms. Automated Data Integration and ETL Tools The rise of no-code and low-code tools is transforming data integration and Extract, Transform, and Load (ETL) processes.
Gain hands-on experience with data integration: Learn about data integration techniques to combine data from various sources, such as databases, spreadsheets, and APIs. Stay curious and committed to continuous learning.
Salam noted that organizations are offloading computational horsepower and data from on-premises infrastructure to the cloud. This provides developers, engineers, data scientists and leaders with the opportunity to more easily experiment with new data practices such as zero-ETL or technologies like AI/ML.
Data Integration A data pipeline can be used to gather data from various disparate sources in one data store. This makes it easier to compare and contrast information and provides organizations with a unified view of their data. A good datagovernance framework will often minimize manual processes to avoid latency.
Cost reduction by minimizing data redundancy, improving data storage efficiency, and reducing the risk of errors and data-related issues. DataGovernance and Security By defining data models, organizations can establish policies, access controls, and security measures to protect sensitive data.
ThoughSpot can easily connect to top cloud data platforms such as Snowflake AI Data Cloud , Oracle, SAP HANA, and Google BigQuery. In that case, ThoughtSpot also leverages ELT/ETL tools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from raw data to the modern BI stack.
To handle sparse data effectively, consider using junk dimensions to group unrelated attributes or creating factless fact tables that capture events without associated measures. Ensuring Data Consistency Maintaining data consistency across multiple fact tables can be challenging, especially when dealing with conformed dimensions.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. However, merely knowing what it consists of isn’t enough.
Click here to learn more about Amit Levi. In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content