This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Airbyte, creators of a fast-growing open-source data integration platform, made available results of the biggest dataengineering survey in the market which provides insights into the latest trends, tools, and practices in dataengineering – especially adoption of tools in the modern data stack.
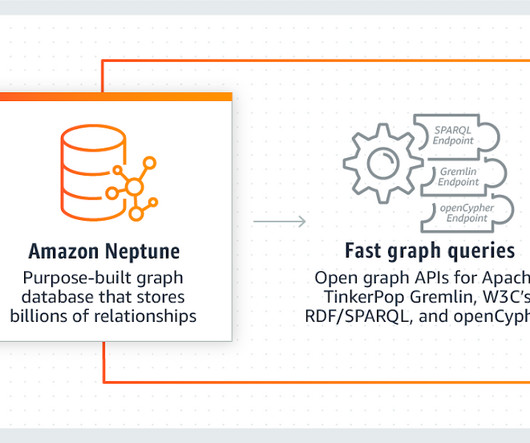
Introduction Managing complicated, interrelated information is more important than ever in today’s data-driven society. Traditional databases, while still valuable, often falter when it comes to handling highly connected data. Enter the unsung heroes of the data world: graph databases.
Introduction Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers.
Introduction A data model is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details. As mentioned earlier, when determining requirements, we collect information about different business processes and […].
Overview OLTP and OLAP are 2 data processing capabilities Understand the difference between OLTP and OLAP Introduction You acquire new information every day. The post DataEngineering for Beginners – Difference Between OLTP and OLAP appeared first on Analytics Vidhya.
In the world of data, two crucial roles play a significant part in unlocking the power of information: Data Scientists and DataEngineers. But what sets these wizards of data apart? Welcome to the ultimate showdown of Data Scientist vs DataEngineer!
Data is the new oil of the industry. The way raw oil empowers the industrial economy, data is empowering the information economy. […]. The post The DataHour Synopsis: Learning Path to Master DataEngineering in 2022 appeared first on Analytics Vidhya.
Whether you are a data analyst, data scientist, or dataengineer, summarizing and aggregating data is essential. This skill helps distill complex information into meaningful insights, driving informed decisions across various industries like finance, healthcare, retail, and technology.
Big dataengineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
The generation and accumulation of vast amounts of data have become a defining characteristic of our world. This data, often referred to as Big Data , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more.
Suri Nuthalapati, Technical Leader - Data & AI at Cloudera | Founder Trida Labs | Founder Farmioc. The rise of artificial intelligence(AI) is fundamentally changing the world of data analytics and dataengineering. Advanced AI systemsAI agents that autonomously act, starting to change how
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
As the digital world grows increasingly data-centric, businesses are compelled to innovate continuously to keep up with the vast amounts of information flowing through their systems. To remain competitive, organizations must embrace cutting-edge technologies and trends that optimize how data is engineered, processed, and utilized.
In today’s rapidly evolving data landscape, organizations must make sense of the overwhelming amounts of data generated daily. The roles of dataengineers and data scientists are central to this mission. They each require distinct skill sets that, when combined, can create a powerful synergy.
However, behind the glitz and glamor of these advancements, there is an underappreciated field: dataengineering. Data is the lifeblood that fuels today’s […] The post The Role of DataEngineering in AI and Machine Learning Projects appeared first on DATAVERSITY.
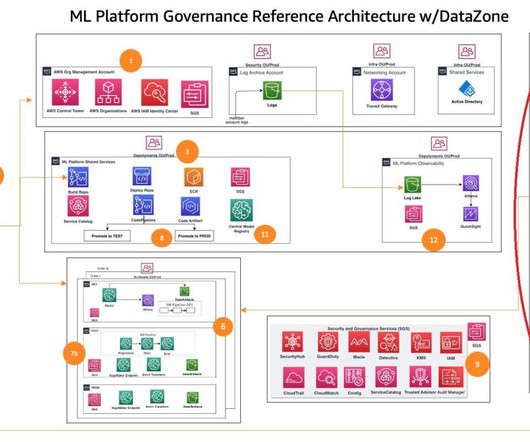
Data science team account (consumer) – There can be one or more data science team accounts or data consumer accounts within the organization. We provide additional information later in this post. For more information about the architecture in detail, refer to Part 1 of this series.
Dataengineering requires expertise in programming and data management, and now IT leaders need to include large language models in their data strategy.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
A 2-for-1 ODSC East Black Friday Deal, Multi-Agent Systems, Financial DataEngineering, and LLM Evaluation ODSC East 2025 Black Friday Deal Take advantage of our 2-for-1 Black Friday sale and join the leading conference for data scientists and AI builders. Learn, innovate, and connect as we shape the future of AI — together!
This article was published as a part of the Data Science Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. We can use it to represent facts, figures, and other information that we can use to make decisions. The post Data Lake or Data Warehouse- Which is Better?
Data-driven organizations require complex collaboration between data teams and business stakeholders. Here are 4 proactive tips for reducing information asymmetries and achieving better collaboration.
Now that we’re in 2024, it’s important to remember that dataengineering is a critical discipline for any organization that wants to make the most of its data. These data professionals are responsible for building and maintaining the infrastructure that allows organizations to collect, store, process, and analyze data.
Specialized Industry Knowledge The University of California, Berkeley notes that remote data scientists often work with clients across diverse industries. Whether it’s finance, healthcare, or tech, each sector has unique data requirements. This role builds a foundation for specialization.
This article was published as a part of the Data Science Blogathon. Introduction I’ve always wondered how big companies like Google process their information or how companies like Netflix can perform searches in concise times.
This article was published as a part of the Data Science Blogathon. In the field of information technology, a container is like a typical container you could encounter in daily life. Introduction We may have heard much about using Containers in IT, especially in Cloud environments. But what exactly are these containers?
In the current landscape, data science has emerged as the lifeblood of organizations seeking to gain a competitive edge. As the volume and complexity of data continue to surge, the demand for skilled professionals who can derive meaningful insights from this wealth of information has skyrocketed.
Introduction Data replication is also known as database replication, which is copying data to ensure that all information remains consistent across all data resources in real-time. data replication is like a safety net that keeps your information safe from disappearing or falling through the cracks.
A comparative overview of data warehouses, data lakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
As AI and dataengineering continue to evolve at an unprecedented pace, the challenge isnt just building advanced modelsits integrating them efficiently, securely, and at scale. Join Veronika Durgin as she uncovers the most overlooked dataengineering pitfalls and why deferring them can be a costly mistake.
Bioinformatic Data Processing Due to the increased attention paid to the development of remedies for novel pathogens, it’s likely that additional staff will soon be needed to manage the influx of information regarding these treatments.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Pretty much everything or all sorts of information available online is. The post What is relational about Relational Databases? appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Data is ubiquitous in our modern life. Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world.
This article was published as a part of the Data Science Blogathon Overview: Machine Learning (ML) and data science applications are in high demand. When ML algorithms offer information before it is known, the benefits for business are significant. The ML algorithms, on […].
In this blog, we discuss the 10 Vs as metrics to gauge the complexity of big data. When we think of “ big data ,” it is easy to imagine a vast, intangible collection of customer information and relevant data required to grow your business. It is one of the three Vs of big data, along with volume and variety.
This wealth of content provides an opportunity to streamline access to information in a compliant and responsible way. Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles.
This approach not only enhances data diversity but also alleviates privacy concerns related to sensitive patient data. Image by author This approach not only increases data diversity but also addresses privacy concerns related to sharing sensitive patient information. Example prompt use case #3.
Data + AI Summit Dates: June 912, 2025 Location: San Francisco, California In a world where data is king and AI is the game-changer, staying ahead means keeping up with the latest innovations in data science, ML, and analytics. Thats where Data + AI Summit 2025 comes in!
It is so extensive and diverse that traditional data processing methods cannot handle it. The volume, velocity, and variety of Big Data can make it difficult to process and analyze.
Introduction With the world of data science constantly evolving, it is important to stay up-to-date with the latest trends and techniques for aspiring and established professionals alike.
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks. ML builders can request access to data published by dataengineers.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content