This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data is ubiquitous in our modern life. Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world. Since contextual data exposes popular patterns and trends, we have arrived at the stage where businesses take data-driven decisions to […].
Dataengineers are the unsung heroes of the data-driven world, laying the essential groundwork that allows organizations to leverage their data for enhanced decision-making and strategic insights. What is a dataengineer?
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Deeply integrated with the lakehouse, Lakebase simplifies operational data workflows. It eliminates fragile ETL pipelines and complex infrastructure, enabling teams to move faster and deliver intelligent applications on a unified data platform In this blog, we propose a new architecture for OLTP databases called a lakebase.
Agent Bricks is optimized for common industry use cases, including structured information extraction, reliable knowledge assistance, custom text transformation, and orchestrated multi-agent systems. We auto-optimize over the knobs, gain confidence that you are on the most optimized settings.
Just provide a high-level description of the agent’s task and connect your enterprise data — Agent Bricks handles the rest. Agent Bricks is optimized for common industry use cases, including structured information extraction, reliable knowledge assistance, custom text transformation, and building multi-agent systems.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
However, all this information is trapped in our infrastructure without a clear way to make it accessible to our agent. Securely host your own MCP server with Databricks Apps Let’s keep building on our telcom support agent: we have some internal APIs that let us know about any current outages and report new ones.
Specialized Industry Knowledge The University of California, Berkeley notes that remote data scientists often work with clients across diverse industries. Whether it’s finance, healthcare, or tech, each sector has unique data requirements. This role builds a foundation for specialization.
In the current landscape, data science has emerged as the lifeblood of organizations seeking to gain a competitive edge. As the volume and complexity of data continue to surge, the demand for skilled professionals who can derive meaningful insights from this wealth of information has skyrocketed.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. This ensures that the data models and queries developed by data professionals are consistent with the underlying infrastructure.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
Businesses project planning is key to success and now they are increasingly rely on data projects to make informed decisions, enhance operations, and achieve strategic goals. However, the success of any data project hinges on a critical, often overlooked phase: gathering requirements. What are the data quality expectations?
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. For more information on enabling users in IAM Identity Center, see Add users to your Identity Center directory. DataEngineer at Amazon Ads.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Matillion has a Git integration for Matillion ETL with Git repository providers, which can be used by your company to leverage your development across teams and establish a more reliable environment. What is Matillion ETL? Feel free to open a notepad and begin saving some information required for the integration later.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. What is Fivetran?
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Explosive data growth can be too much to handle. each year. .
Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered. What makes the difference is a smart ETL design capturing the nature of process mining data. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses.
Data-driven culture cannot exist without the democratization of the data. Data democratization certainly does not mean unrestricted access to all […]. The post How a Modern DataEngineering Stack Can Help Create a Data-Driven Culture appeared first on DATAVERSITY.
In this post, we will be particularly interested in the impact that cloud computing left on the modern data warehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a Data Warehouse?
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Banks and their employees place trust in their risk models to help ensure the bank maintains liquidity even in the worst of times.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. The solution consists of the following components: Data ingestion: Data is ingested into the data account from on-premises and external sources.
ERP (Enterprise Resource Planning) systems contain information about finance, supplier management, human resources and other operational processes, while CRM (Customer Relationship Management) systems provide data about customer relationships, marketing and sales activities. Copyright by DATANOMIQ.
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. Refer to Unlocking the Power of Big Data Article to understand the use case of these data collected from various sources.
To keep myself sane, I use Airflow to automate tasks with simple, reusable pieces of code for frequently repeated elements of projects, for example: Web scraping ETL Database management Feature building and data validation And much more! Finally, let’s get the data saved to the worker onto our host machine.
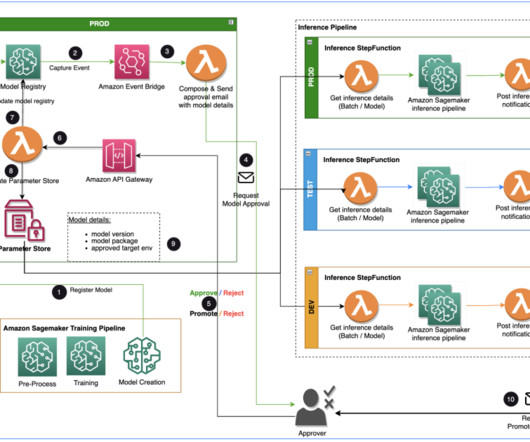
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. The model detail information is stored in Parameter Store, including the model version, approved target environment, and model package. This post is co-written with Jayadeep Pabbisetty, Sr.
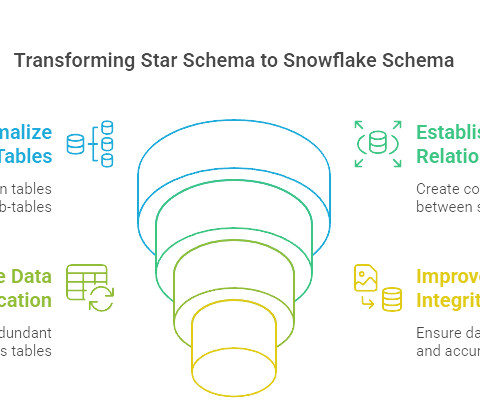
Reduced Data Redundancy By normalizing the dimension tables, the snowflake schema significantly reduces data duplication. Each piece of information is stored once, optimizing storage and improving consistency. Snowflake Schema Lower redundancy as data is normalized. How Does Snowflake Schema Improve Data Integrity?
This has created many different data quality tools and offerings in the market today and we’re thrilled to see the innovation. People will need high-quality data to trust information and make decisions. The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph.
DataEngineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Consider your schedule and budget as you opt for a structure and format for your data science bootcamp. Ensure that the bootcamp of your choice covers these specific topics.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Truly a must-have tool in your dataengineering arsenal!
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. The attempt is disadvantaged by the current focus on data cleaning, diverting valuable skills away from building ML models for sensor calibration.
By analyzing the sentiment of users towards certain products, services, or topics, sentiment analysis provides valuable insights that empower businesses and organizations to make informed decisions, gauge public opinion, and improve customer experiences. Noise in data can arise due to data collection errors, system glitches, or human errors.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content