This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction A data model is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details. The post Data Abstraction for DataEngineering with its Different Levels appeared first on Analytics Vidhya.
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
By Josep Ferrer , KDnuggets AI Content Specialist on June 10, 2025 in Python Image by Author DuckDB is a fast, in-process analytical database designed for modern data analysis. DuckDB is a free, open-source, in-process OLAP database built for fast, local analytics. Let’s dive in! What Is DuckDB? What Are DuckDB’s Main Features?
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Introduction Azure Functions is a serverless computing service provided by Azure that provides users a platform to write code without having to provision or manage infrastructure in response to a variety of events. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g.,
In addition to Business Intelligence (BI), Process Mining is no longer a new phenomenon, but almost all larger companies are conducting this data-driven process analysis in their organization. The Event Log Data Model for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Top Employers Microsoft, Facebook, and consulting firms like Accenture are actively hiring in this field of remote data science jobs, with salaries generally ranging from $95,000 to $140,000. Advancing into Leadership For those interested in leadership, progressing to roles like Lead Data Scientist or Chief Data Officer is an option.
What is an online transaction processing database (OLTP)? OLTP is the backbone of modern data processing, a critical component in managing large volumes of transactions quickly and efficiently. This approach allows businesses to efficiently manage large amounts of data and leverage it to their advantage in a highly competitive market.
Here’s what makes it stand out: Agentic AI: Move and clean data between apps automatically, date formats, text extraction, and formatting handled for you. Workflow Automation: Connect any two apps or websites and automate tasks without integrations, perfect for auto filling forms, updating databases, or sending messages.
MCP servers are lightweight programs or APIs that expose real-world tools like databases, file systems, or web services to AI models. Big names like Hugging Face and Meta are now running hackathons where participants build MCP servers, clients, and plugins, showing just how hot this space is right now.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
Email Report Generator Why its useful : If you regularly compile and send data reports via email, this automation can cut your workload substantially. What to build : Develop a script that pulls data from a source (spreadsheet, database, or API), generates a report, and emails it to a predefined list of recipients on a schedule.
Introduction Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
EPAM Thinks You Should Rethink Your Data Stack for AI Navigating the Future of Talent Skills in a Transforming Business Landscape Latest AI News Glean Raises $150M in Series F Round, Hits $7.2B Request Customised Reports & AIM Surveys for a study on topics of your interest.
Because it’s modular, you can easily extend it, maybe add a search bar using Streamlit, store chunks in a vector database like FAISS for smarter lookups, or even plug this into a chatbot. Examples of Articles Conclusion In this guide, you’ve learned how to build a flexible and powerful PDF processing pipeline using only open-source tools.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
In this representation, there is a separate store for events within the speed layer and another store for data loaded during batch processing. The serving layer acts as a mediator, enabling subsequent applications to access the data. This architectural concept relies on event streaming as the core element of data delivery.
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Prescriptive analytics is a branch of data analytics that focuses on advising on optimal future actions based on data analysis. It transcends merely describing past events and predicting future occurrences by providing actionable recommendations that guide decision-making processes in organizations.
Data science and dataengineering are incredibly resource intensive. Between accessing databases, using frameworks, using applications, and more, a lot of power is needed to run even the simplest algorithms. As such, here are a few dataengineering and data science cloud options to make your life easier.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Is Gen AI A DataEngineering or Software Engineering Problem?
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. In the event of a problematic AI model, it can be challenging to determine the root cause.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
This feature chunks and converts input data into embeddings using your chosen Amazon Bedrock model and stores everything in the backend vector database. On the Vector database pane, select Quick create a new vector store and choose the new Amazon OpenSearch Serverless option as the vector store.
Imperva Cloud WAF protects hundreds of thousands of websites against cyber threats and blocks billions of security events every day. Counters and insights based on security events are calculated daily and used by users from multiple departments. Applications use different UI components to allow users to filter and query the data.
EvolvabilityIts Mostly About Data Contracts Editors note: Elliott Cordo is a speaker for ODSC East this May 1315! Be sure to check out his talk, Enabling Evolutionary Architecture in DataEngineering , there to learn about data contracts and plentymore.
Or was the database password for the central subscription service rotated again? By searching for patterns, errors, or anomalies, as well as comparing the trend to the previous period, it helps the agent pinpoint issues related to specific events, such as failed authentications or system crashes. Did an internal TLS certificate expire?
At one IndiaAI event, IT minister Ashwini Vaishnaw declared, “The entire ecosystem is being built right now in AI, and the IT industry should capture this transition as an opportunity.” Notably, all are young tech ventures, with no presence from established giants like Infosys, TCS or Wipro.
In other words, LLMs are not dynamic but rather static in nature, which prevents them from answering questions about recent events or information. This is done by creating a store of relevant knowledge, usually in the form of embeddings in a vector database, to supplement additional context for the LLM to consider when formulating a response.
Navigating the Complex World of Financial DataEngineering Here’s an exploration of a recent podcast, which provides a roadmap for understanding the challenges, opportunities, and future of financial dataengineering. Announcing ODSC East 2025 — The 10th Anniversary of the Best AI Builders Event Around!
Datadog is a monitoring service for cloud-scale applications, bringing together data from servers, databases, tools and services to present a unified view of your entire stack. This customizable and scalable solution allows its ML models to be efficiently deployed and managed to meet diverse project requirements.
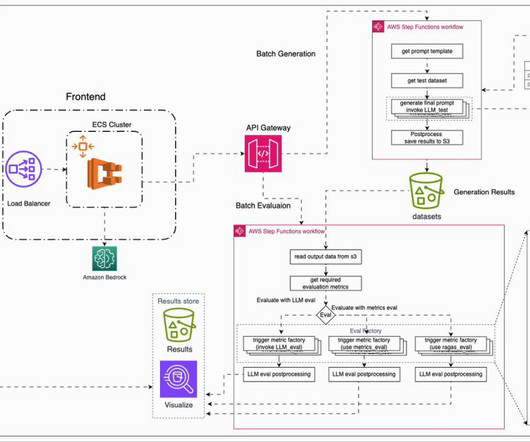
Ragas can be used to evaluate the performance of an information retriever (the component that retrieves relevant information from a database) using metrics like context precision and recall. Kai Zhu, currently works as Cloud Support Engineer at AWS, helping customers with issues in AI/ML related services like SageMaker, Bedrock, etc.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. You encounter bottlenecks because you need to rely on dataengineering and data science teams to accomplish these goals.
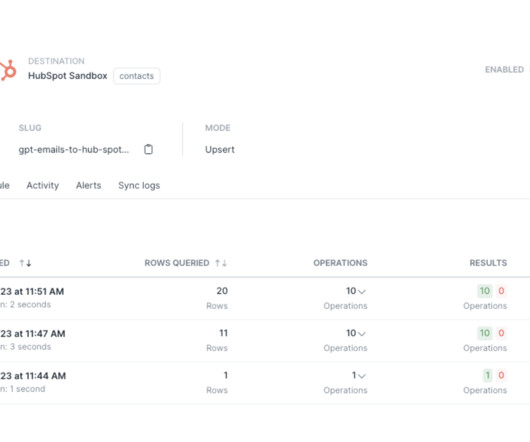
This example assumes an architecture with your CRM, like Salesforce or HubSpot, as the source of your incoming sales leads and customer data. This data is being ingested into the Snowflake Data Cloud using Fivetran , and the dataengineering has been done leveraging dbt.
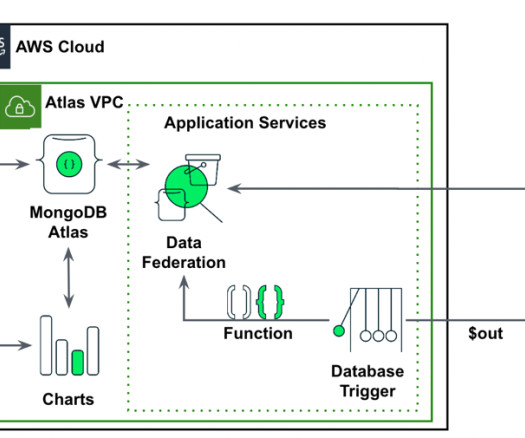
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Setup the Database access and Network access.
Flows CrewAI Flows provide a structured, event-driven framework to orchestrate complex, multi-step AI automations seamlessly. These tools allow agents to interact with APIs, access databases, execute scripts, analyze data, and even communicate with other external systems.
Four reference lines on the x-axis indicate key events in Tableau’s almost two-decade history: The first Tableau Conference in 2008. Chris had earned an undergraduate computer science degree from Simon Fraser University and had worked as a database-oriented software engineer. Release v1.0 April 2005) is in the top left corner.
However, the majority of enterprise data remains unleveraged from an analytics and machine learning perspective, and much of the most valuable information remains in relational database schemas such as OLAP. You can also get data science training on-demand wherever you are with our Ai+ Training platform.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content