This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
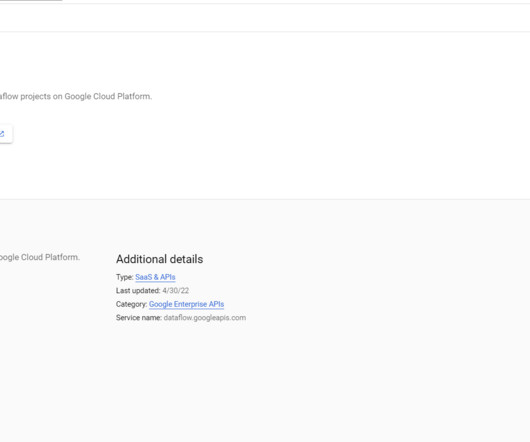
Introduction Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Big dataengineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Dataengineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable datapipelines. Thats where dataengineering tools come in!
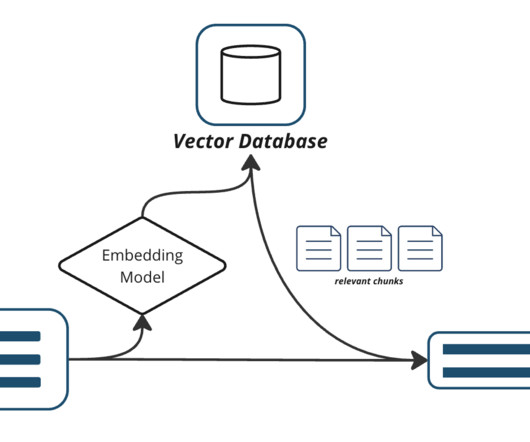
This approach not only enhances data diversity but also alleviates privacy concerns related to sensitive patient data. Image by author This approach not only increases data diversity but also addresses privacy concerns related to sharing sensitive patient information. Example prompt use case #3.
Now that we’re in 2024, it’s important to remember that dataengineering is a critical discipline for any organization that wants to make the most of its data. These data professionals are responsible for building and maintaining the infrastructure that allows organizations to collect, store, process, and analyze data.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
As AI and dataengineering continue to evolve at an unprecedented pace, the challenge isnt just building advanced modelsits integrating them efficiently, securely, and at scale. Join Veronika Durgin as she uncovers the most overlooked dataengineering pitfalls and why deferring them can be a costly mistake.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
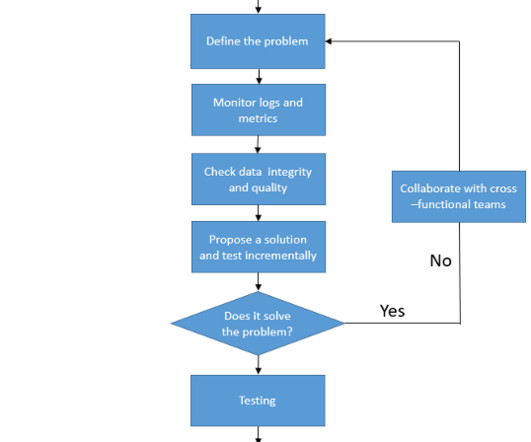
While speaking at AIMs event DES 2025, Manjunatha G, engineering and site leader at the 3M Global Technology Centre, laid out a practical path to integrate AI agents into dataengineering workflows.
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This enables OMRON to extract meaningful patterns and trends from its vast data repositories, supporting more informed decision-making at all levels of the organization.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. What is an ETL datapipeline in ML?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
This article was co-written by Lawrence Liu & Safwan Islam While the title ‘ Machine Learning Engineer ’ may sound more prestigious than ‘DataEngineer’ to some, the reality is that these roles share a significant overlap. Generative AI has unlocked the value of unstructured text-based data.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
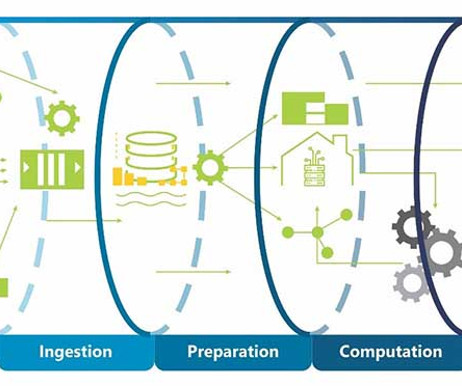
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. This process is shown in the following diagram.
From marketing strategies that target specific demographics to sales optimizations that increase revenue, data science plays a crucial role in giving companies a competitive edge. Business applications Organizations leverage data science to improve various aspects of their operations.
DataEngineer. In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a dataengineer, you could also build and maintain datapipelines that create an interconnected data ecosystem that makes information available to data scientists.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Data products are proliferating in the enterprise, and the good news is that users are consuming data products at an accelerated rate, whether its an AI model, a BI interface, or an embedded dashboard on a website.
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Explosive data growth can be too much to handle. each year. .
Data lineage helps during these investigations. Because lineage creates an environment where reports and data can be trusted, teams can make more informed decisions. Data lineage provides that reliability—and more. That’s why datapipeline observability is so important. Stakeholders?
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
ERP (Enterprise Resource Planning) systems contain information about finance, supplier management, human resources and other operational processes, while CRM (Customer Relationship Management) systems provide data about customer relationships, marketing and sales activities. Copyright by DATANOMIQ.
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. This ensures that the models can make predictions based on the latest information available. Spark, Flink, etc.)
Chatbots and virtual assistants are some of the common applications developed by NLP engineers for modern businesses. Big dataengineer Potential pay range – US$206,000 to 296,000/yr They operate at the backend to build and maintain complex systems that store and process the vast amounts of data that fuel AI applications.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. What is Fivetran?
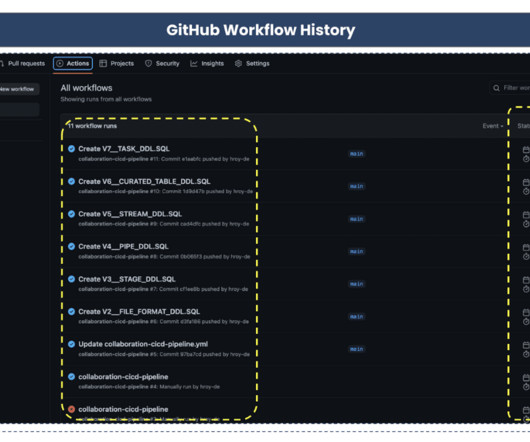
In recent years, dataengineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently. What Are the Benefits of CI/CD Pipeline For Snowflake?
That’s why many organizations invest in technology to improve data processes, such as a machine learning datapipeline. However, data needs to be easily accessible, usable, and secure to be useful — yet the opposite is too often the case. What’s worse, just 3% of the data in a business enterprise meets quality standards.
Outside of the physical servers and data centres that every cloud provider is comprised of, the infrastructure layer encompasses everything related to information architecture, including data access and security, data storage systems, computational resources, availability, and service-level agreements.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
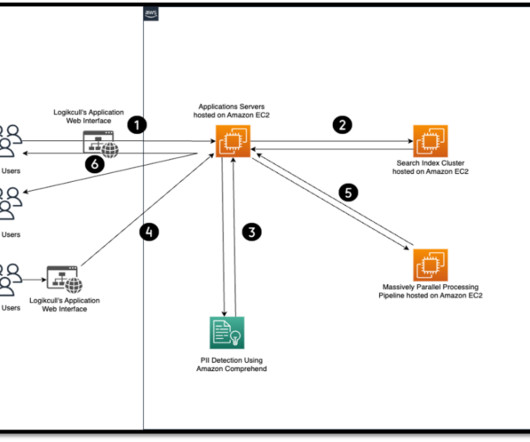
Today, personally identifiable information (PII) is everywhere. It refers to any data or information that can be used to identify a specific individual. It’s a critical component of modern data management and cybersecurity practices. PII is in emails, slack messages, videos, PDFs, and so on.
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its big datapipeline.
In prior blog posts challenges beyond the 3V’s and understanding data , I discussed some issues which hindered the efficiency of data analysts besides drastically raising the bar on their motivation to begin working with new data. Here, I want to drill into a few more experiences around use and management of data.
.” - Brian Sharp, Lead Data Science Engineer, Forcura Challenges Challenges: Forcura faced significant hurdles in standardizing key medical documentation which varies widely by source (such as physician, hospital or skilled nursing facility). Their primary challenges included: Data inconsistencies from non-standardized documentation.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? The value of data lineage applies across all industries, but there are three key focuses when you consider it for banking use cases: 1.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























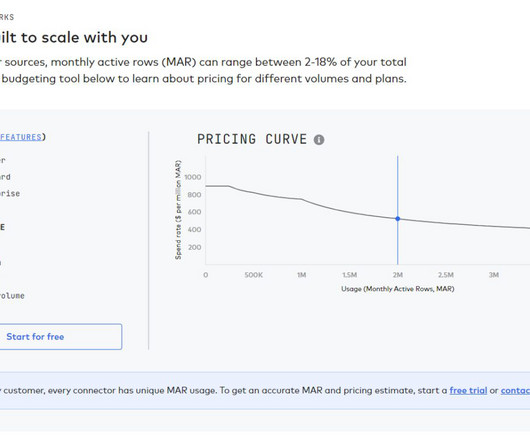












Let's personalize your content