This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. We can use it to represent facts, figures, and other information that we can use to make decisions. The post DataLake or Data Warehouse- Which is Better?
A comparative overview of data warehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
Separation of storage and compute : Lakebases store their data in modern datalakes (object stores) in open formats, which enables scaling compute and storage separately, leading to lower TCO and eliminating lock-in. At zero, the cost of the lakebase is just the cost of storing the data on cheap datalakes.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
Big dataengineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. On the home page, select Synapse DataEngineering.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
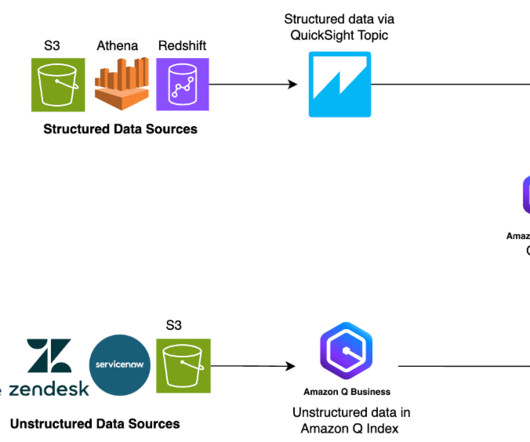
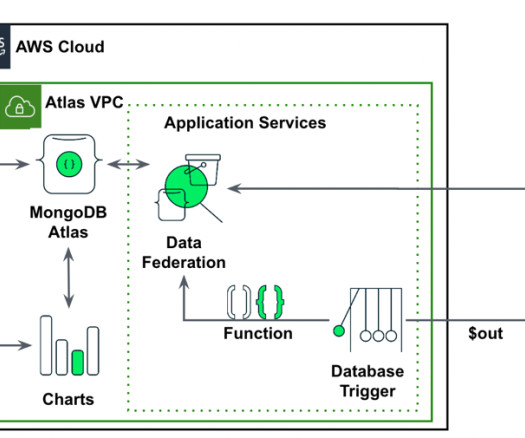
Data is the foundational layer for all generative AI and ML applications. Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. The following diagram illustrates the solution architecture.
In this post, we show you how Amazon Q Business can help augment your generative AI needs in all the abovementioned use cases and more by answering questions, providing summaries, generating content, and securely completing tasks based on data and information in your enterprise systems. Traditionally, businesses face a challenge.
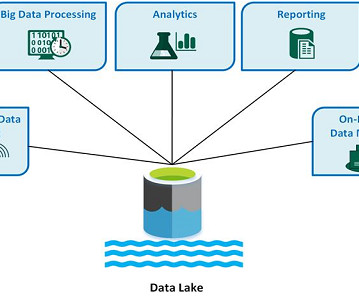
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP.
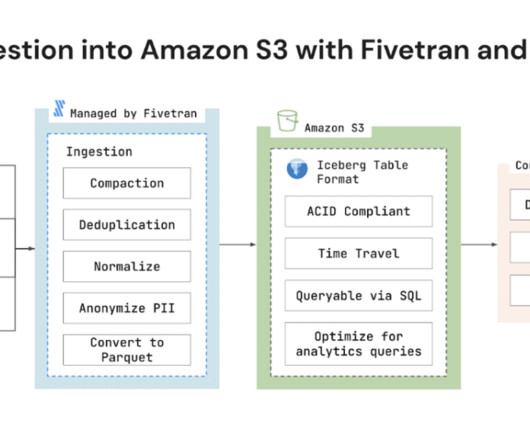
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
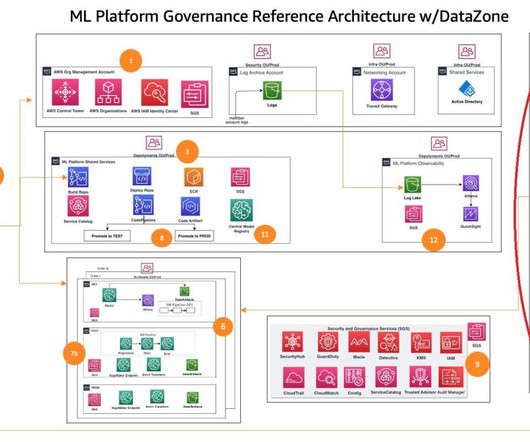
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
When you think of dataengineering , what comes to mind? In reality, though, if you use data (read: any information), you are most likely practicing some form of dataengineering every single day. Said differently, any tools or steps we use to help us utilize data can be considered dataengineering.
It helps you extract information by recognizing sentiments, key phrases, entities, and much more, allowing you to take advantage of state-of-the-art models and adapt them for your specific use case. MLOps requires the integration of software development, operations, dataengineering, and data science.
The main goal of a data mesh structure is to drive: Domain-driven ownership Data as a product Self-service infrastructure Federated governance One of the primary challenges that organizations face is data governance. What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
Many users struggle to access the information they need or understand its full context once that access is unlocked. What’s worse, just 3% of the data in a business enterprise meets quality standards. There’s also no denying that data management is becoming more important, especially to the public.
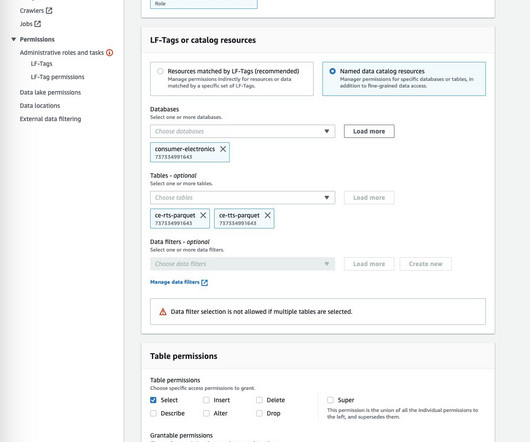
Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake. Create a datalake with Lake Formation.
The vector field should be represented as an array of numbers (BSON int32, int64, or double data types only). Refer to Review knnVector Type Limitations for more information about the limitations of the knnVector type. As a DataEngineer he was involved in applying AI/ML to fraud detection and office automation.
Andreas Kohlmaier, Head of DataEngineering at Munich Re 1. --> Ron Powell, independent analyst and industry expert for the BeyeNETWORK and executive producer of The World Transformed FastForward Series, interviews Andreas Kohlmaier, Head of DataEngineering at Munich Re. But it is a little hard to consume.
Data Mesh More data management systems in 2023 will also shift toward a data mesh architecture. This decentralized architecture breaks datalakes into smaller domains specific to a given team or department. However, enabling these architectures safely will require careful planning and security.
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its big data pipeline.
Big data isn’t an abstract concept anymore, as so much data comes from social media, healthcare data, and customer records, so knowing how to parse all of that is needed. This pushes into big data as well, as many companies now have significant amounts of data and large datalakes that need analyzing.
Quotes It's extremely important because many of the Gen AI and LLM applications take an unstructured data approach, meaning many of the tools require you to give the tools full access to your data in an unrestricted way and let it crawl and parse it completely. Data governance is the only way to ensure those requirements are met.
Enterprise data architects, dataengineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. This also led to a backlog of data that needed to be ingested. Lake Formation makes this data available to both the build and compute accounts.
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. The attempt is disadvantaged by the current focus on data cleaning, diverting valuable skills away from building ML models for sensor calibration.
By exploring these challenges, organizations can recognize the importance of real-time forecasting and explore innovative solutions to overcome these hurdles, enabling them to stay competitive, make informed decisions, and thrive in today’s fast-paced business environment. For more information, refer to the following resources.
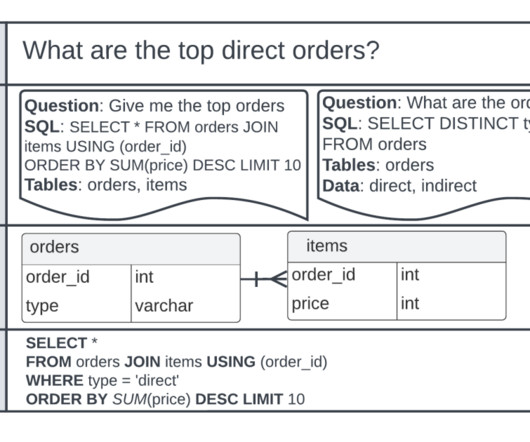
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. Each document holds an example question and information about it.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
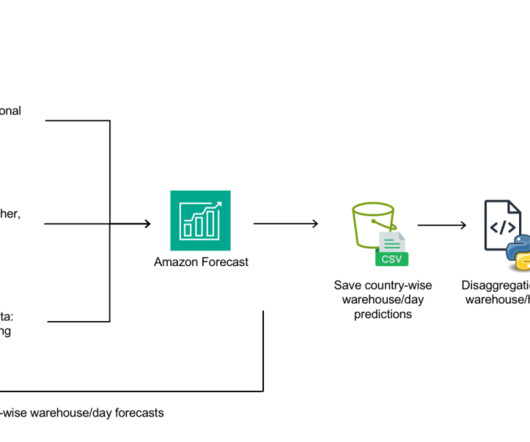
Historic transactional demand data, location-based weather information, holiday dates, promotions and marketing campaign data are the features used in the model as shown in the graph below. He joined Getir in 2022 as a Data Scientist and started working on time-series forecasting and mathematical optimization projects.
“I think one of the most important things I see people do right, is to make sure that you build the data foundation from the ground up correctly,” said Ali Ghodsi, CEO of Databricks. The data lakehouse is one such architecture—with “lake” from datalake and “house” from data warehouse.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. Data scientists will typically perform data analytics when collecting, cleaning and evaluating data. Watsonx comprises of three powerful components: the watsonx.ai
“I think one of the most important things I see people do right, is to make sure that you build the data foundation from the ground up correctly,” said Ali Ghodsi, CEO of Databricks. The data lakehouse is one such architecture—with “lake” from datalake and “house” from data warehouse.
How to leverage Generative AI to manage unstructured data Benefits of applying proper unstructured data management processes to your AI/ML project. What is Unstructured Data? One thing is clear : unstructured data doesn’t mean it lacks information.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. These skilled professionals are tasked with building and deploying models that improve the quality and efficiency of BMW’s business processes and enable informed leadership decisions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content