This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative AI for databases will transform how you deal with databases, whether or not you’re a datascientist, […] The post 10 Ways to Use Generative AI for Database appeared first on Analytics Vidhya. Though it appears to dazzle, its true value lies in refreshing the fundamental roots of applications.
Through understanding each phase, teams can effectively harness data to create solutions that address specific problems. Numerous factors contribute to the success of this process, making it essential for datascientists and stakeholders to comprehend the lifecycle comprehensively. What is the machine learning lifecycle?
Logistic regression Logistic regression is designed for binary classification tasks, predicting the likelihood of an event occurring based on input variables. It enhances dataclassification by increasing the complexity of input data, helping organizations make informed decisions based on probabilities.
In fact, SQL’s simplicity coupled with its ability to analyze data thoroughly has also made it a favorite programming language among datascientists looking to compare and analyze various data sets. SQL is a query language, which means it retrieves or changes information from a database through queries.
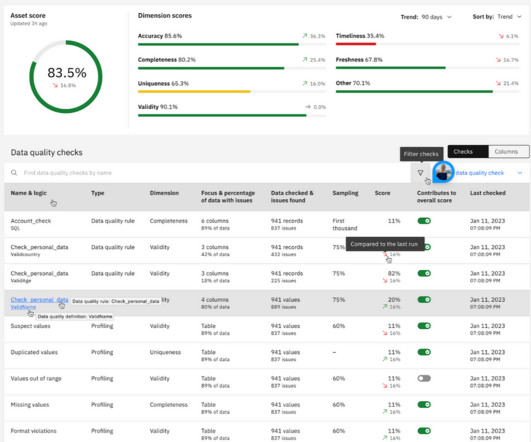
Metadata Enrichment: Empowering Data Governance Data Quality Tab from Metadata Enrichment Metadata enrichment is a crucial aspect of data governance, enabling organizations to enhance the quality and context of their data assets. This dataset spans a wide range of ages, from teenagers to senior citizens.
Data ingestion and extraction Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. Prince Mallari is an NLP DataScientist in the Professional Services team at AWS, specializing in applications of NLP for public sector customers.
For instance, if datascientists were building a model for tornado forecasting, the input variables might include date, location, temperature, wind flow patterns and more, and the output would be the actual tornado activity recorded for those days. Naïve Bayes classifiers —enable classification tasks for large datasets.
Foundation models can be trained to perform tasks such as dataclassification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy.
In the realm of data science, seasoned professionals often carry out research to comprehend how similar issues have been tackled in the past. They investigate the most suitable algorithms, identify the best weights and hyperparameters, and might even collaborate with fellow datascientists in the community to develop an effective strategy.
Similarly, in healthcare, ANNs can predict patient outcomes based on historical medical data. Classification Tasks ANNs are commonly used for classification tasks, where the goal is to assign input data to predefined categories.
Masked data provides a cost-effective way to help test if a system or design will perform as expected in real-life scenarios. As the insurance industry continues to generate a wider range and volume of data, it becomes more challenging to manage dataclassification.
Amazon Comprehend support both synchronous and asynchronous options, if real-time classification isn’t required for your use case, you can submit a batch job to Amazon Comprehend for asynchronous dataclassification. Yanyan Zhang is a Senior DataScientist in the Energy Delivery team with AWS Professional Services.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content