This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This initial phase of analysis lays the groundwork for more in-depth methods, making it an essential practice in today’s data-driven world. What is data exploration? Data exploration is a vital phase in the dataanalysis process.
In the increasingly competitive world, understanding the data and taking quicker actions based on that help create differentiation for the organization to stay ahead! EDA is an iterative process, and is used to uncover hidden insights and uncover relationships within the data.
Parallel file systems are sophisticated solutions designed to optimize data storage and retrieval processes across multiple networked servers, facilitating robust I/O operations needed in various computing environments. By industry sector National laboratories: Focus on scientific research applications requiring extensive dataanalysis.
One particularly striking example showcased how a simple change to hyperlink text in search engine advertisements generated an additional $100 million in revenue, demonstrating the remarkable potential of data-driven decision making.
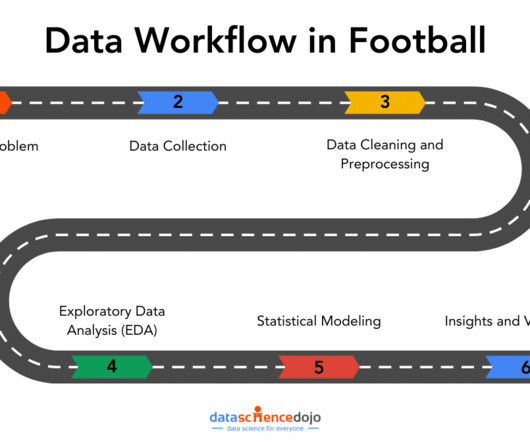
Whether youre passionate about football or data, this journey highlights how smart analytics can increase performance. Defining the Problem The starting point for any successful data workflow is problem definition. Correcting these issues ensures your analysis is based on clean, reliable data.
It involves data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and correlations that can drive decision-making. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on dataanalysis and interpretation to extract meaningful insights.
From this project, I saw a really great post from Darragh Murray about the importance of exploratorydataanalysis. Over the years I’ve been asked many times about how one becomes a better data analyst. While my suggested approach works in a sense, Darragh’s is a bit more prescriptive and it’s definitely worth a read.
From this project, I saw a really great post from Darragh Murray about the importance of exploratorydataanalysis. Over the years I’ve been asked many times about how one becomes a better data analyst. While my suggested approach works in a sense, Darragh’s is a bit more prescriptive and it’s definitely worth a read.
Summary: The Data Science and DataAnalysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. billion INR by 2026, with a CAGR of 27.7%.
The Use of LLMs: An Attractive Solution for DataAnalysis Not only can LLMs deliver dataanalysis in a user-friendly and conversational format “via the most universal interface: Natural Language,” as Satya Nadella, the CEO of Microsoft, puts it, but also they can adapt and tailor their responses to immediate context and user needs.
We can define an AI Engineering Process or AI Process (AIP) which can be used to solve almost any AI problem [5][6][7][9]: Define the problem: This step includes the following tasks: defining the scope, value definition, timelines, governance, and resources associated with the deliverable.
Email classification project diagram The workflow consists of the following components: Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratorydataanalysis (EDA), data cleaning and preparation, and building prototype models.
Summary: Dive into programs at Duke University, MIT, and more, covering DataAnalysis, Statistical quality control, and integrating Statistics with Data Science for diverse career paths. offer modules in Statistical modelling, biostatistics, and comprehensive Data Science bootcamps, ensuring practical skills and job placement.
It supports Pearson, Kendall, and Spearman methods, aiding in insightful DataAnalysis. Introduction Pandas is a powerful Python library widely used for DataAnalysis. It offers flexible and efficient data manipulation tools. This article explores using Pandas’s corr() method for effective DataAnalysis.
In the context of time series, model monitoring is particularly important as time series data can be highly dynamic because change is definite over time in ways that can impact the accuracy of the model. Comet has another noteworthy feature: it allows us to conduct exploratorydataanalysis.
Data storage : Store the data in a Snowflake data warehouse by creating a data pipe between AWS and Snowflake. Data Extraction, Preprocessing & EDA : Extract & Pre-process the data using Python and perform basic ExploratoryDataAnalysis. The data is in good shape.
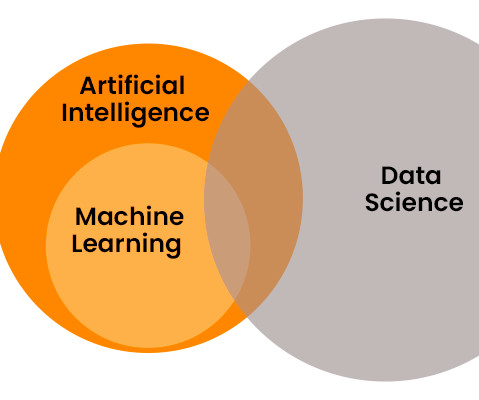
AI automates and optimises Data Science workflows, expediting analysis for strategic decision-making. Data Science Vs Machine Learning Vs AI Aspect Data Science Artificial Intelligence Machine Learning DefinitionData Science is the field that deals with the extraction of knowledge and insights from data through various processes.
Data Scientists are highly in demand across different industries for making use of the large volumes of data for analysisng and interpretation and enabling effective decision making. One of the most effective programming languages used by Data Scientists is R, that helps them to conduct dataanalysis and make future predictions.
I initially conducted detailed exploratorydataanalysis (EDA) to understand the dataset, identifying challenges like duplicate entries and missing Coordinate Reference System (CRS) information. I'd definitely would try more models pre-trained on remote sensing data.
I know similarities languages are not the sole and definite barometers of effectiveness in learning foreign languages. And importantly, starting naively annotating data might become a quick solution rather than thinking about how to make uses of limited labels if extracting data itself is easy and does not cost so much.
These capabilities take the form of: Exploratorydataanalysis to prepare basic features from raw data. Specialized automated feature engineering and reduction for time series data. The transparency of a model depends on understanding not only the model building process but also its training and prediction data.
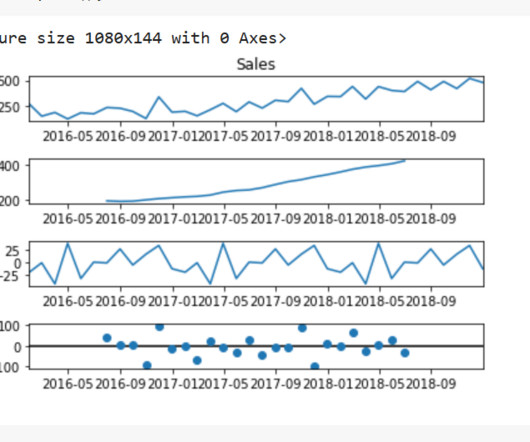
The Art of Forecasting in the Retail Industry Part I : ExploratoryDataAnalysis & Time Series Analysis In this article, I will conduct exploratorydataanalysis and time series analysis using a dataset consisting of product sales in different categories from a store in the US between 2015 and 2018.
GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do dataanalysis BI report generation/dataanalysis In BI/dataanalysis world, people usually need to query data (small/large).
You know that there is a vocabulary exam type of question in SAT that asks for the correct definition of a word that is selected from the passage that they provided. The AI generates questions asking for the definition of the vocabulary that made it to the end after the entire filtering process. So I tried to think of something else.
Firstly, we have the definition of the training set, which is refers to the training sample , which has features and labels. Applying XGBoost to Our Dataset Next, we will do some exploratorydataanalysis and prepare the data for feeding the model. Before we begin, just a few points.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. AB : Makes sense.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. AB : Makes sense.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. AB : Makes sense.
Definition of KNN Algorithm K Nearest Neighbors (KNN) is a simple yet powerful machine learning algorithm for classification and regression tasks. Unlock Your Data Science Career with Pickl.AI Hands-On Experience: Dive into ExploratoryDataAnalysis and Feature Engineering for practical experience.
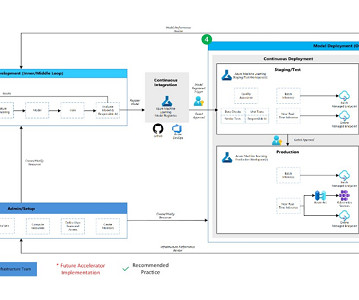
Definition of project team users, their roles, and access controls to other resources. Model Development (Inner Loop): The inner loop element consists of your iterative data science workflow. Creation of Azure Machine Learning workspaces for the project. Creation of CI/CD (Continuous Integration and Continuous Delivery) pipelines.
Scikit-learn: A simple and efficient tool for data mining and dataanalysis, particularly for building and evaluating machine learning models. This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape.
You may also like Building a Machine Learning Platform [Definitive Guide] Consideration for data platform Setting up the Data Platform in the right way is key to the success of an ML Platform. When you look at the end-to-end journey of an eCommerce platform, you will find there are plenty of components where data is generated.
AdaBoos t A formal definition of AdaBoost (Adaptive Boosting) is “the combination of the output of weak learners into a weighted sum, representing the final output.” A bit of exploratorydataanalysis (EDA) on the dataset would show many NaN (Not-a-Number or Undefined) values. But that leaves a lot of things vague. .
Here’s what they mean, age: The person’s age in years sex: The person’s sex (1 = male, 0 = female) cp: The chest pain experienced (Value 0: typical angina, Value 1: atypical angina, Value 2: non-anginal pain, Value 3: asymptomatic) trestbps: The person’s resting blood pressure (mm Hg on admission to the hospital) chol: The person’s cholesterol measurement (..)
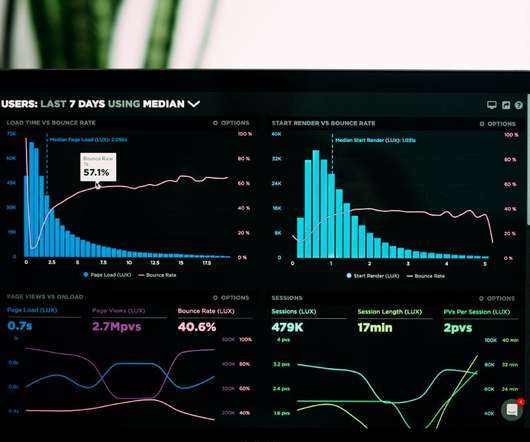
The term “data visualization” refers to the visual representation of data using tables, charts, graphs, maps, and other aids to analyze and interpret information. It is a crucial component of the Exploration DataAnalysis (EDA) stage, which is typically the first and most critical step in any data project.
In most cases, there is no definitive right or wrong answer, he says. Its important to network with people to understand what kind of data science they are doing, what the role entails, and what skills are needed to make sure that its a good fit for you, he says. There are eight of what he calls spokes in data science.
I have 2 years of experience in dataanalysis and over 3 years of experience in developing deep learning architectures. During an actual dataanalysis project that I was involved in, I had the opportunity to extract insights from a large-scale text dataset similar to what we used for this project.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content