This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Exploratory dataanalysis (EDA) is a critical component of data science that allows analysts to delve into datasets to unearth the underlying patterns and relationships within. EDA serves as a bridge between raw data and actionable insights, making it essential in any data-driven project.
To address this challenge, businesses need to use advanced dataanalysis methods. These methods can help businesses to make sense of their data and to identify trends and patterns that would otherwise be invisible. In recent years, there has been a growing interest in the use of artificial intelligence (AI) for dataanalysis.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
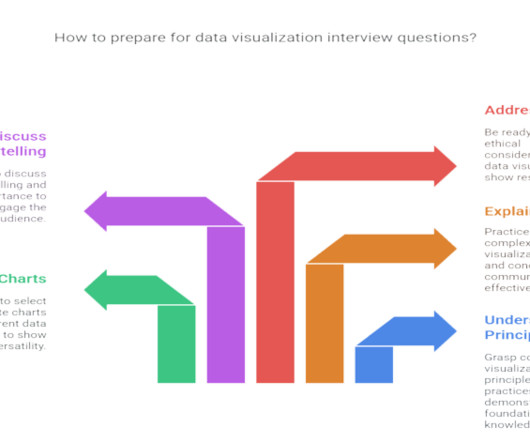
Introduction Data visualization is no longer just a niche skill; it’s a fundamental component of DataAnalysis , business intelligence, and data science. Q1: What is data visualization, and why is it important in DataAnalysis? The approach depends on the context and the amount of missing data.
This new paradigm comes with new rules: Self-service is critical for an insight-driven organization, and in this more fluid data environment, understanding the lineage and context of that data is key to data exploration. Get the latest data cataloging news and trends in your inbox. Subscribe to Alation's Blog.
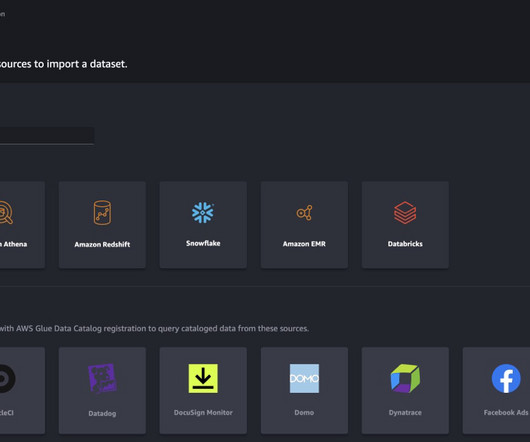
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Tableau+ includes: Einstein Copilot for Tableau (only in Tableau+) : Get an intelligent assistant that helps make Tableau easier and analysts more efficient across the platform: In Tableau Prep (coming in 2024.2) : Automate formula creation and speed up datapreparation.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
release includes features that speed up and streamline your datapreparation and analysis. Automate dashboard insights with Data Stories. If you've ever written an executive summary of a dashboard, you know it’s time consuming to distill the “so what” of the data. Product Marketing Associate, Tableau.
release includes features that speed up and streamline your datapreparation and analysis. Automate dashboard insights with Data Stories. If you've ever written an executive summary of a dashboard, you know it’s time consuming to distill the “so what” of the data. Product Marketing Associate, Tableau.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
Active Governance – Active data governance creates usage-based assignments, which prioritize and delegate curation duties. It also allows for deeper analytics and visibility into people, data, and documentation. It also catalogs datasets and operations that includes datapreparation features and functions.
Learn how Data Scientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, dataanalysis, data cleaning, and data visualization. It facilitates exploratory DataAnalysis and provides quick insights.
Data catalogs have quickly become a core component of modern data management. Organizations with successful data catalog implementations see remarkable changes in the speed and quality of dataanalysis, and in the engagement and enthusiasm of people who need to perform dataanalysis.
While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics. In this blog post, we will show you how to leverage KNIME’s Tableau Integration Extension and discuss the benefits of using KNIME for datapreparation before visualization in Tableau.
Low data discoverability: For example, Sales doesn’t know what data Marketing even has available, or vice versa—or the team simply can’t find the data when they need it. . Unclear change management process: There’s little or no formality around what happens when a data source changes. Data modeling.
Low data discoverability: For example, Sales doesn’t know what data Marketing even has available, or vice versa—or the team simply can’t find the data when they need it. . Unclear change management process: There’s little or no formality around what happens when a data source changes. Data modeling.
Datapreparation and training The datapreparation and training pipeline includes the following steps: The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time. Get started today by referring to the GitHub repository.
For access to the data used in this benchmark notebook, sign up for the competition here. KG 2 bfaiol.wav nonword_repetition chav KG 3 ktvyww.wav sentence_repetition ring the bell on the desk to get her attention 2 4 htfbnp.wav blending kite KG We'll join these datasets together to help with our exploratory dataanalysis.
Summary: This blog presents 15 advanced Excel interview questions designed to evaluate candidates’ expertise in dataanalysis, formula usage, and spreadsheet management. Topics include VLOOKUP vs. INDEX/MATCH, pivot tables, macros, and data validation. What are array formulas, and how do you use them?
Data Manipulation The process through which you can change the data according to your project requirement for further dataanalysis is known as Data Manipulation. The entire process involves cleaning, Merging and changing the data format. This data can help in building the project pipeline.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. The Microsoft Certified: Azure Data Scientist Associate certification is highly recommended, as it focuses on the specific tools and techniques used within Azure.
Augmented Analytics Augmented analytics is revolutionising the way businesses analyse data by integrating Artificial Intelligence (AI) and Machine Learning (ML) into analytics processes. Understand data structures and explore data warehousing concepts to efficiently manage and retrieve large datasets.
We are living in a world where data drives decisions. Data manipulation in Data Science is the fundamental process in dataanalysis. The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
Automated development: With AutoAI , beginners can quickly get started and more advanced data scientists can accelerate experimentation in AI development. AutoAI automates datapreparation, model development, feature engineering and hyperparameter optimization. A strong user community along with support resources (e.g.,
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Summary: Statistical Modeling is essential for DataAnalysis, helping organisations predict outcomes and understand relationships between variables. Introduction Statistical Modeling is crucial for analysing data, identifying patterns, and making informed decisions. Datapreparation also involves feature engineering.
Its visual workflow interface enables users to blend, prepare, and analyse data without writing extensive code. Alteryx supports various data formats and connects easily to various data sources, making it highly flexible. To safeguard data integrity, look for tools that offer encryption, access control, and audit trails.
Data Transformation Transforming dataprepares it for Machine Learning models. Encoding categorical variables converts non-numeric data into a usable format for ML models, often using techniques like one-hot encoding. Outlier detection identifies extreme values that may skew results and can be removed or adjusted.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. I’ll show you best practices for using Jupyter Notebooks for exploratory dataanalysis. When data science was sexy , notebooks weren’t a thing yet. documentation.
Summary: This blog provides a comprehensive guide on how to make and plot graphs in Excel, covering various graph types, datapreparation, and customisation techniques. It emphasises the importance of effective data visualisation for clearly communicating trends and insights, ensuring users can easily create informative charts.
Some LLMs also offer methods to produce embeddings for entire sentences or documents, capturing their overall meaning and semantic relationships. These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering.
It identifies the optimal path for missing data during tree construction, ensuring the algorithm remains efficient and accurate. This feature eliminates the need for preprocessing steps like imputation, saving time in datapreparation. This flexibility is a key reason why its favoured across diverse domains.
Numerous industries have undergone a revolution because of their quick improvements, which have also greatly improved automation and visual dataanalysis capabilities. Make sure that each photograph is well labeled, and segregate the data into folders for each class. What is Image Recognition?
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring. As an example for catalogue data, it’s important to check if the set of mandatory fields like product title, primary image, nutritional values, etc.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Learn more about Metaflow in the documentation and get started through the tutorials or resource pages. Check out the documentation to get started.
ClickUp ClickUp is more than just a project management toolits an AI-powered productivity hub that consolidates task management, document collaboration, and workflow automation in one platform. Sales teams can forecast trends, optimize lead scoring, and enhance customer engagement all while reducing manual dataanalysis.
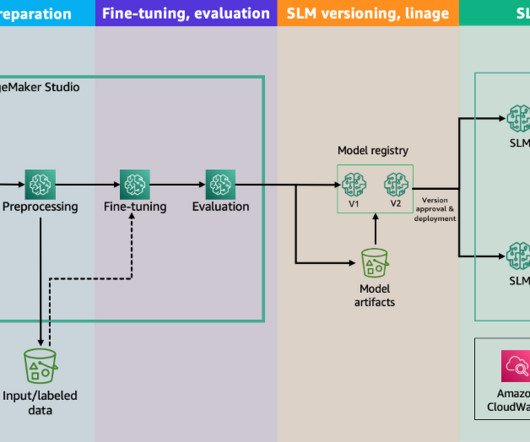
We begin with the dataanalysis phase and progress through the end-to-end process, covering fine-tuning, deployment, and evaluation. Dataanalysis and preparation on SageMaker Studio When you’re fine-tuning LLMs, the quality and composition of your training data are crucial (quality over quantity).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content