This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
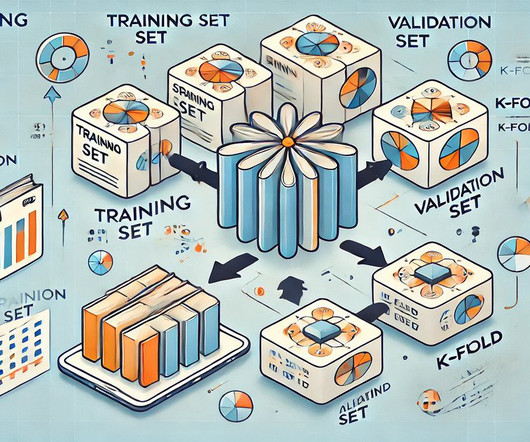
Noisy data Noisy data, filled with random variations and irrelevant information, can mislead the model. Signs of overfitting Common signs of overfitting include a significant disparity between training and validation performance metrics. The model is trained K times, each time using a different subset for validation.
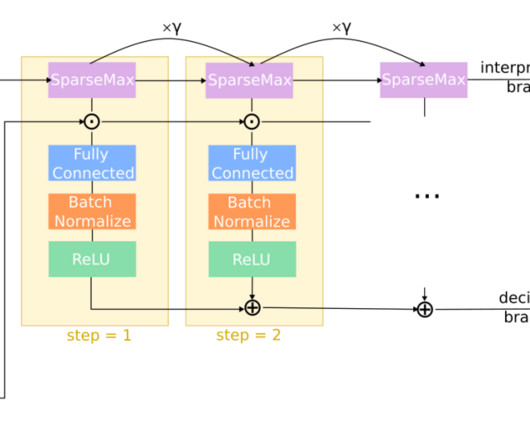
Theses initial surveys are currently carried out by human experts who evaluate the possible presence of landmines based on available information and that provided by the residents. For the Risk Modeling component, we designed a novel interpretable deeplearning tabular model extending TabNet. Validation results in Colombia.
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Introduction In this article, we will explore the concept of cross-validation in Machine Learning, a crucial technique for assessing model performance and generalisation.
Deeplearning is a branch of machine learning that makes use of neural networks with numerous layers to discover intricate data patterns. Deeplearning models use artificial neural networks to learn from data. Semi-Supervised Learning : Training is done using both labeled and unlabeled data.
Deeplearning models with multilayer processing architecture are now outperforming shallow or standard classification models in terms of performance [5]. Deep ensemble learning models utilise the benefits of both deeplearning and ensemble learning to produce a model with improved generalisation performance.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! It’s like having a super-powered tool to sort through information and make better sense of the world. Learn in detail about machine learning algorithms 2. accuracy).
Some machine learning packages focus specifically on deeplearning, which is a subset of machine learning that deals with neural networks and complex, hierarchical representations of data. Let’s explore some of the best Python machine learning packages and understand their features and applications.
It involves human annotators using a tool to label images or tag relevant information. The resulting structured data is then used to train a machine learning algorithm. There are a lot of image annotation techniques that can make the process more efficient with deeplearning.
I am involved in an educational program where I teach machine and deeplearning courses. Machine learning is my passion and I often take part in competitions. Training data was splited into 5 folds for crossvalidation. Incorporating time and location information for each pixel (i.e.
For more information, you can read the competition's Problem Description. Model architectures : All four winners created ensembles of deeplearning models and relied on some combination of UNet, ConvNext, and SWIN architectures. In the modeling phase, XGBoost predictions serve as features for subsequent deeplearning models.
Ultimately, the judging panel chose the winning submission for its excellent constructive discussion of label noise, discussion about interactions between mass spectrometry data collection and machine learning, and interesting use of engineered features that capture peak information.
Tabular data has been around for decades and is one of the most common data types used in data analysis and machine learning. Traditionally, tabular data has been used for simply organizing and reporting information. The synthetic datasets were created using a deep-learning generative network called CTGAN.[3]
Several additional approaches were attempted but deprioritized or entirely eliminated from the final workflow due to lack of positive impact on the validation MAE. Her primary interests lie in theoretical machine learning. She currently does research involving interpretability methods for biological deeplearning models.
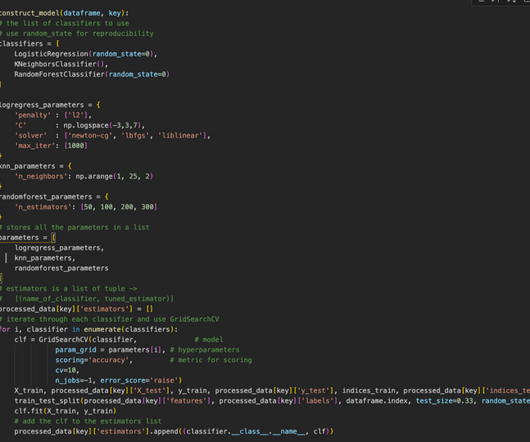
Applying XGBoost on a Problem Statement Applying XGBoost to Our Dataset Summary Citation Information Scaling Kaggle Competitions Using XGBoost: Part 4 Over the last few blog posts of this series, we have been steadily building up toward our grand finish: deciphering the mystery behind eXtreme Gradient Boosting (XGBoost) itself.
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. Embeddings are vector representations of text that capture semantic and contextual information.
This is where machine learning comes in. Machine learning algorithms are like tools that help computers learn from data and make informed decisions or predictions. As you gather more information (e.g., What is machine learning? Machine learning algorithms help you find patterns in this data.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. TensorFlow and Keras: TensorFlow is an open-source platform for machine learning.
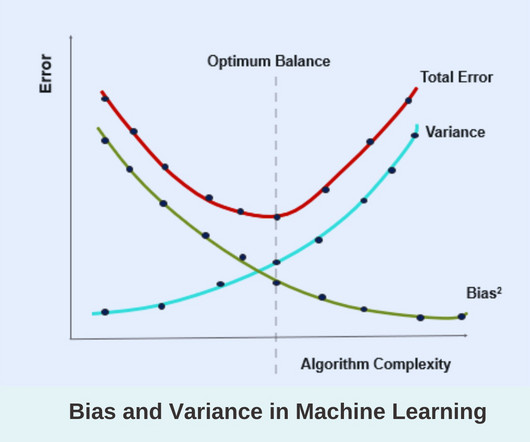
To mitigate variance in machine learning, techniques like regularization, cross-validation, early stopping, and using more diverse and balanced datasets can be employed. Cross-ValidationCross-validation is a widely-used technique to assess a model’s performance and find the optimal balance between bias and variance.
It enables organizations to create powerful, data-driven models that reveal patterns, trends, and insights, leading to more informed decision-making and more effective automation. MLOps practices include cross-validation, training pipeline management, and continuous integration to automatically test and validate model updates.
In the fast-paced world of Data Science, having quick and easy access to essential information is invaluable when using a repository of Cheat sheets for Data Scientists. Cheat sheets for Data Scientists Cheat sheets are like treasure maps for Data Scientists, helping them navigate the vast sea of information and tools available to them.
Without linear algebra, understanding the mechanics of DeepLearning and optimisation would be nearly impossible. For instance, understanding distributions helps select appropriate models and evaluate their likelihood, while hypothesis testing aids in validating assumptions about data.
Revolutionizing Healthcare through Data Science and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating data science, machine learning, and information technology.
Neural Networks In DeepLearning, key model-related hyperparameters include the number of layers, neurons in each layer, and the activation functions. Combine with cross-validation to assess model performance reliably. Best Practices Start with Grid Search for smaller, more defined hyperparameter spaces.
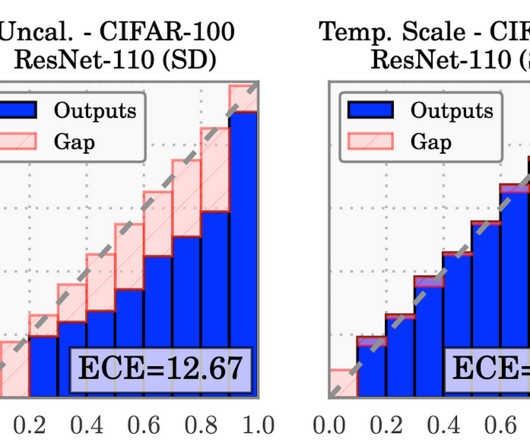
Calibrating neural networks is especially important in safety-critical applications where reliable confidence estimates are crucial for making informed decisions. On mixup training: Improved calibration and predictive uncertainty for deep neural networks.” Advances in Neural Information Processing Systems 32 (2019). [8]
Researchers have explored a variety of approaches over the years from classical statistical methods to deeplearning architectures to tackle these challenges. This step: Integrates MultiResolution Information: Merges insights from various scales. We built APDTFlow specifically to address these challenges.
Feature engineering is the process of creating new features or transforming existing features in a dataset to improve the performance of Machine Learning models. It involves selecting, extracting, and transforming raw data into informative features that capture the underlying patterns and relationships in the data.
These models use the transformer architecture , a type of natural language processing (NLP), to interpret the vast amount of genomic information available, allowing researchers and scientists to extract meaningful insights more accurately than with existing in silico approaches and more cost-effectively than with existing in situ techniques.
With the advent of DeepLearning, recommender systems have seen significant advancements. With Comet, we've gained valuable insights and made informed decisions to elevate our recommender systems. These methods accurately capture complex, non-linear relationships between users and items.
Summary: Feature extraction in Machine Learning is essential for transforming raw data into meaningful features that enhance model performance. It involves identifying relevant information and reducing complexity, which improves accuracy and efficiency. What is Feature Extraction?
Data analytics deals with checking the existing hypothesis and information and answering questions for a better and more effective business-related decision-making process. Long format DataWide-Format DataHere, each row of the data represents the one-time information of a subject. What is deeplearning?
Feature Engineering: Feature engineering involves creating new features from existing ones that may be more informative or relevant for the machine learning task. Batch size and learning rate are two important hyperparameters that can significantly affect the training of deeplearning models, including LLMs.
Scikit-Learn Scikit Learn is associated with NumPy and SciPy and is one of the best libraries helpful for working with complex data. Its modified feature includes the cross-validation that allowing it to use more than one metric. The number of TensorFlow applications is unlimited and is the best version.
This technology enables businesses to make informed decisions, optimize resources, and enhance strategic planning. This capability is essential for businesses aiming to make informed decisions in an increasingly data-driven world. In 2024, the global Time Series Forecasting market was valued at approximately USD 214.6
This usually involved gathering market and property information, socio-economic data about a city on a zip code level and information regarding access to amenities (e.g., This would entail a roughly +/-€24,520 price difference on average, compared to the true price, using MAE (Mean Absolute Error) CrossValidation.
By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Data Science is the art and science of extracting valuable information from data.
To make the correct coverage identification, a multitude of information over time must be accounted for, including the way defenders lined up before the snap and the adjustments to offensive player movement once the ball is snapped. Advances in neural information processing systems 30 (2017). Gomez, Łukasz Kaiser, and Illia Polosukhin.
Organisations must develop strategies to store and manage this vast amount of information effectively. DeepLearning An introduction to deeplearning concepts and frameworks like TensorFlow and PyTorch, focusing on their applications in processing large datasets.
Cross-Validation: Instead of using a single train-test split, cross-validation involves dividing the data into multiple folds and training the model on each fold. Data Quality Issues One of the primary hurdles in Machine Learning is ensuring high-quality data.
Scientific studies forecasting — Machine Learning and deeplearning for time series forecasting accelerate the rates of polishing up and introducing scientific innovations dramatically. 19 Time Series Forecasting Machine Learning Methods How exactly does time series forecasting machine learning work in practice?
Understanding these distinctions enables informed algorithm selection, ensuring optimal performance tailored to the specific needs of your project. Monitor Overfitting : Use techniques like early stopping and cross-validation to avoid overfitting. Start with Default Values : Begin with default settings and evaluate performance.
Moving the machine learning models to production is tough, especially the larger deeplearning models as it involves a lot of processes starting from data ingestion to deployment and monitoring. Now you might be wondering why you should believe me with all this information. What is MLOps?
For example, in medical imaging, techniques like skull stripping and intensity normalization are often used to remove irrelevant background information and normalize tissue intensities across different scans, respectively. Domain-specific preprocessing: for certain tasks, domain-specific preprocessing can lead to better model performance.
The blog also presents popular data analytics courses, emphasizing their curriculum, learning methods, certification opportunities, and benefits to help aspiring Data Analysts choose the proper training for their career advancement. Techniques such as cross-validation, regularisation , and feature selection can prevent overfitting.
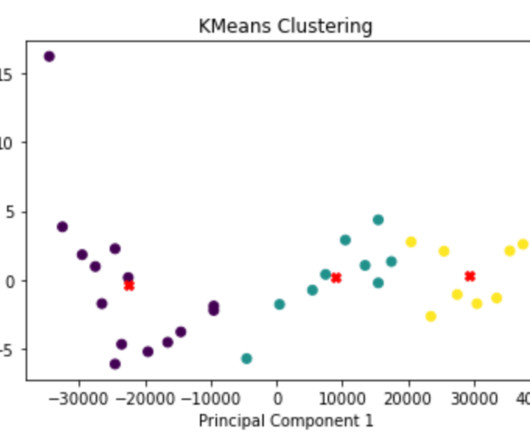
The optimal value for K can be found using ideas like CrossValidation (CV). By applying the Elbow or Knee method, data analysts can make an informed decision about the appropriate number of clusters for their specific dataset, balancing the trade-off between model complexity and the level of within-cluster variation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content