This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
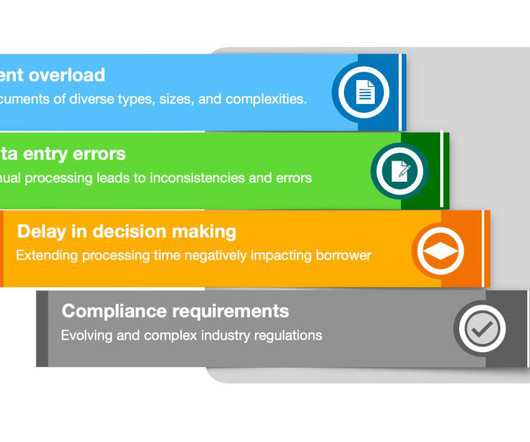
Mortgage processing is a complex, document-heavy workflow that demands accuracy, efficiency, and compliance. In this post, we introduce agentic automatic mortgage approval, a next-generation sample solution that uses autonomous AI agents powered by Amazon Bedrock Agents and Amazon Bedrock Data Automation. Why agentic IDP?
Figure 5 Feature Extraction and Evaluation Because most classifiers and learning algorithms require numerical feature vectors with a fixed size rather than raw text documents with variable length, they cannot analyse the text documents in their original form.
Its internal deployment strengthens our leadership in developing dataanalysis, homologation, and vehicle engineering solutions. These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests.
Technical Approaches: Several techniques can be used to assess row importance, each with its own advantages and limitations: Leave-One-Out (LOO) Cross-Validation: This method retrains the model leaving out each data point one at a time and observes the change in model performance (e.g., accuracy).
Here is a simple example using the snowflake-arctic model: EXTRACT_ANSWER EXTRACT_ANSWER will answer a question based on a text document in plain English or as a string representation of JSON. Users can now extract key information buried within large documents without any code or ML knowledge required.
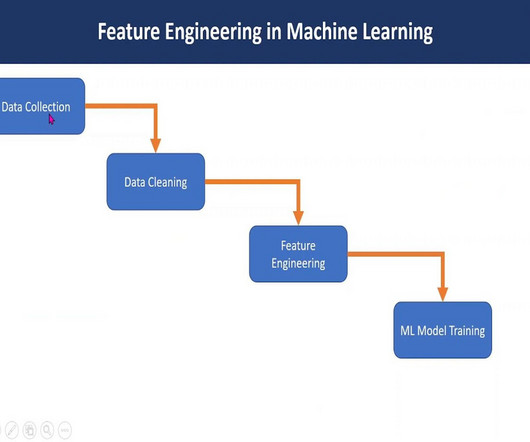
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through Exploratory DataAnalysis , imputation, and outlier handling, robust models are crafted. Text feature extraction Objective: Transforming textual data into numerical representations.
Model Evaluation and Tuning After building a Machine Learning model, it is crucial to evaluate its performance to ensure it generalises well to new, unseen data. Unit testing ensures individual components of the model work as expected, while integration testing validates how those components function together.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
Here are some notable applications where KNN shines: Classification Tasks Image Recognition: KNN is adept at classifying images into different categories, making it invaluable in applications like facial recognition, object detection, and medical image analysis. Unlock Your Data Science Career with Pickl.AI
Summary: Statistical Modeling is essential for DataAnalysis, helping organisations predict outcomes and understand relationships between variables. Introduction Statistical Modeling is crucial for analysing data, identifying patterns, and making informed decisions.
A cheat sheet for Data Scientists is a concise reference guide, summarizing key concepts, formulas, and best practices in DataAnalysis, statistics, and Machine Learning. It serves as a handy quick-reference tool to assist data professionals in their work, aiding in data interpretation, modeling , and decision-making processes.
Documenting Objectives: Create a comprehensive document outlining the project scope, goals, and success criteria to ensure all parties are aligned. Making Data Stationary: Many forecasting models assume stationarity. Split the Data: Divide your dataset into training, validation, and testing subsets to ensure robust evaluation.
Data storage : Store the data in a Snowflake data warehouse by creating a data pipe between AWS and Snowflake. Data Extraction, Preprocessing & EDA : Extract & Pre-process the data using Python and perform basic Exploratory DataAnalysis. Please refer to this documentation link.
Data Cleaning: Raw data often contains errors, inconsistencies, and missing values. Data cleaning identifies and addresses these issues to ensure data quality and integrity. Data Visualisation: Effective communication of insights is crucial in Data Science.
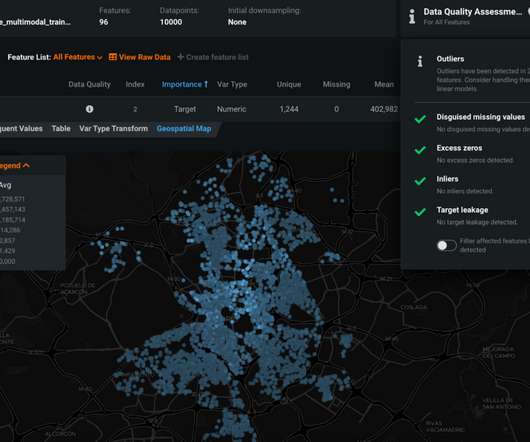
You can understand the data and model’s behavior at any time. Once you use a training dataset, and after the Exploratory DataAnalysis, DataRobot flags any data quality issues and, if significant issues are spotlighted, will automatically handle them in the modeling stage. Rapid Modeling with DataRobot AutoML.
Although it disregards word order, it offers a simple and efficient way to analyse textual data. TF-IDF (Term Frequency-Inverse Document Frequency) TF-IDF builds on BoW by emphasising rare and informative words while minimising the weight of common ones. Adopt an Iterative Approach Feature extraction is rarely a one-time process.
Scikit-learn Scikit-learn is a machine learning library in Python that is majorly used for data mining and dataanalysis. It also provides tools for model evaluation , including cross-validation, hyperparameter tuning, and metrics such as accuracy, precision, recall, and F1-score.
Regular updates, detailed documentation, and widespread tutorials ensure that users have ample resources to troubleshoot and innovate. Monitor Overfitting : Use techniques like early stopping and cross-validation to avoid overfitting. This flexibility is a key reason why its favoured across diverse domains.
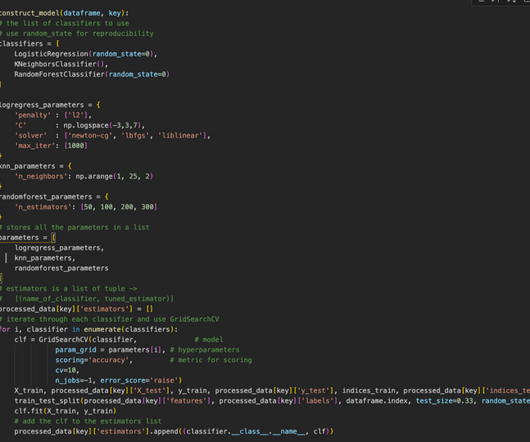
With all of that, the model gets retrained with all the data and stored in the Sagemaker Model Registry. This is a relatively straightforward process that handles training with cross-validation, optimization, and, later on, full dataset training. After that, a chosen model gets deployed and used in the model pipeline.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratory dataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content