
Interpretable machine learning for predicting optimal surgical timing in polytrauma patients with TBI and fractures to reduce postoperative infection risk
MAY 25, 2025
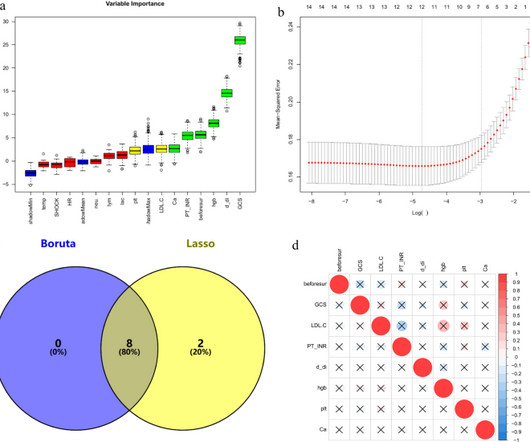
Feature selection via the Boruta and LASSO algorithms preceded the construction of predictive models using Random Forest, Decision Tree, K-Nearest Neighbors, Support Vector Machine, LightGBM, and XGBoost. Demographic data, physiological status, and non-invasive test indicators were collected.










Let's personalize your content