This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Explainable AI is no longer just an optional add-on when using ML algorithms for corporate decision making. The post Adding Explainability to Clustering appeared first on Analytics Vidhya. Introduction The ability to explain decisions is increasingly becoming important across businesses.
Introduction Kubeflow is an open-source platform that makes it easy to deploy and manage machine learning (ML) workflows on Kubernetes, a popular open-source system for automating containerized applications’ deployment, scaling, and management.
The post Understand The DBSCAN Clustering Algorithm! ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, I’m gonna explain about DBSCAN algorithm. appeared first on Analytics Vidhya.
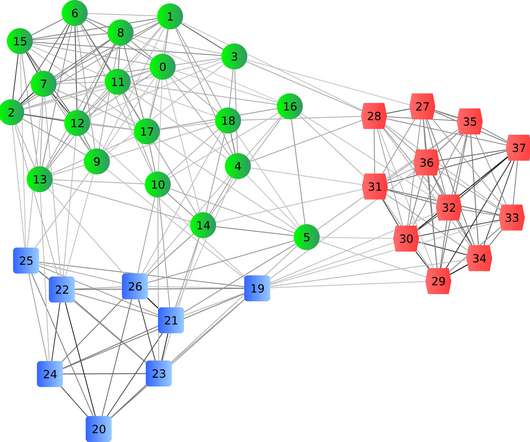
ArticleVideo Book This article was published as a part of the Data Science Blogathon Agglomerative Clustering using Single Linkage (Source) As we all know, The post Single-Link Hierarchical Clustering Clearly Explained! appeared first on Analytics Vidhya.
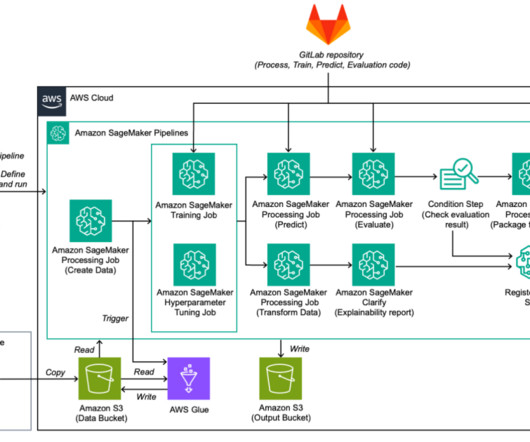
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters. Create a new training plan.
Scaling machine learning (ML) workflows from initial prototypes to large-scale production deployment can be daunting task, but the integration of Amazon SageMaker Studio and Amazon SageMaker HyperPod offers a streamlined solution to this challenge. Create a JupyterLab space and mount an Amazon FSx for Lustre file system to your space.
At the time, I knew little about AI or machine learning (ML). But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML. Panic set in as we realized we would be competing on stage in front of thousands of people while knowing little about ML.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. Larger clusters, more failures, smaller MTBF As cluster size increases, the entropy of the system increases, resulting in a lower MTBF. It implies that if a single instance fails, it stops the entire job.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster.
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. RELand consistently outperforms the benchmark models on all relevant metrics.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. For this post we’ll use a provisioned Amazon Redshift cluster.
Ray has emerged as a powerful framework for distributed computing in AI and ML workloads, enabling researchers and practitioners to scale their applications from laptops to clusters with minimal code changes.
Solution overview The steps to implement the solution are as follows: Create the EKS cluster. Create the EKS cluster If you don’t have an existing EKS cluster, you can create one using eksctl. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
This is why businesses are looking to leverage machine learning (ML). In this article, we will share some best practices for improving your analytics with ML. Top ML approaches to improve your analytics. Clustering. ?lustering They need a more comprehensive analytics strategy to achieve these business goals.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both ML Algorithms, and we’ll explore them more in detail in a bit. They are both ML Algorithms, and we’ll explore them more in detail in a bit.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
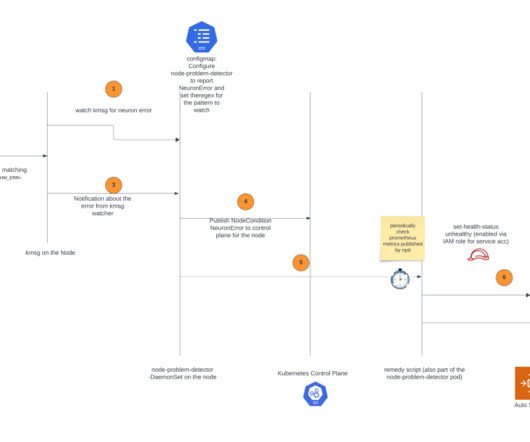
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group. # install.sh
Hammerspace, the company orchestrating the Next Data Cycle, unveiled the high-performance NAS architecture needed to address the requirements of broad-based enterprise AI, machine learning and deep learning (AI/ML/DL) initiatives and the widespread rise of GPU computing both on-premises and in the cloud.
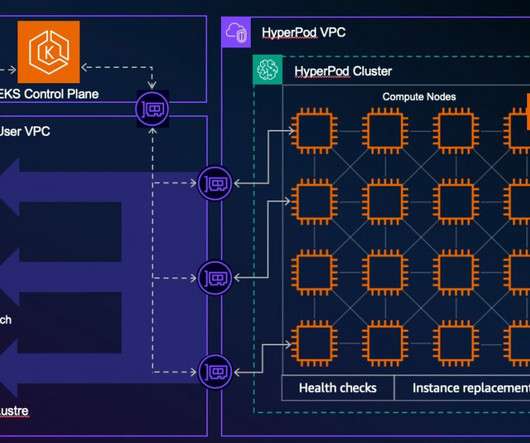
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
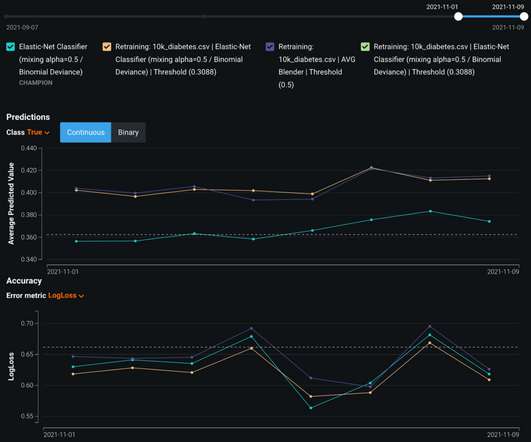
With a goal to help data science teams learn about the application of AI and ML, DataRobot shares helpful, educational blogs based on work with the world’s most strategic companies. Time Series Clustering empowers you to automatically detect new ways to segment your series as economic conditions change quickly around the world.
Recent developments in machine learning (ML) have led to increasingly large models, some of which require hundreds of billions of parameters. In such distributed environments, observability of both instances and ML chips becomes key to model performance fine-tuning and cost optimization.
TensorFlow provides high-level APIs, such as tf.distribute, to distribute training across multiple devices, machines, or clusters. It offers a comprehensive ecosystem that supports distributed training and inference, allowing developers to scale their machine learning workflows seamlessly.
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application.
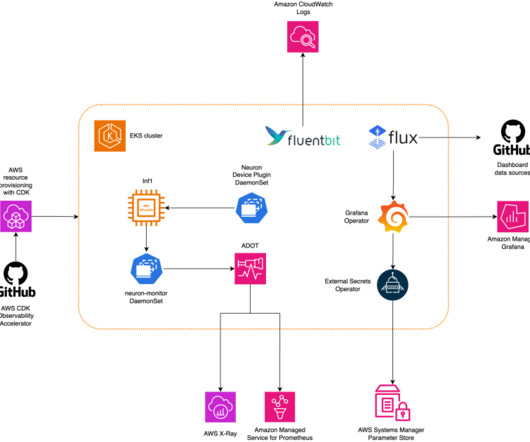
This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to set up and manage your machine learning (ML) workflows with AWS AI Chips. By deploying the Neuron Monitor DaemonSet across EKS nodes, developers can collect and analyze performance metrics from ML workload pods.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The dataset was stored in an Amazon Simple Storage Service (Amazon S3) bucket, which served as a centralized data repository.
Image generated with DALL-E 3 In the fast-paced world of Machine Learning (ML) research, keeping up with the latest findings is crucial and exciting, but let’s be honest — it’s also a challenge. Enter ML Conference Paper Explorer: your sidekick in navigating the ML paper maze with ease. What’s the next big thing in ML?
IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster. A file records vectors that belong to each cluster. It enables comparison and detailed data search within clusters. Both methods aim to enhance the similarity search in vector databases.
The rise of generative AI has significantly increased the complexity of building, training, and deploying machine learning (ML) models. It now demands deep expertise, access to vast datasets, and the management of extensive compute clusters. Builders can use built-in ML tools within SageMaker HyperPod to enhance model performance.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. The training data, securely stored in Amazon Simple Storage Service (Amazon S3), is copied to the cluster.
Business challenge Today, many developers use AI and machine learning (ML) models to tackle a variety of business cases, from smart identification and natural language processing (NLP) to AI assistants. You can train foundation models (FMs) for weeks and months without disruption by automatically monitoring and repairing training clusters.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
On June 12, 2025 at NVIDIA GTC Paris, learn more about cuML and clustering algorithms during the hands-on workshop, Accelerate Clustering Algorithms to Achieve the Highest Performance. Data-Intensive Workloads Today’s data is growing at an unprecedented rate which makes for highly complex data processing workflows for ML.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. This approach combines the efficiency of machine learning with human judgment in the following way: The ML model processes and classifies transactions rapidly.
The embedding projector is a powerful visualization tool that helps data scientists and researchers understand complex, high-dimensional data often encountered in machine learning (ML) and natural language processing (NLP). By revealing these clusters, the tool provides important insights that can inform model refinement processes.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content