This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In other words, neighbors play a major part in our life. Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. What is KNearestNeighbor? How to get started 1.
It’s like having a super-powered tool to sort through information and make better sense of the world. By comprehending these technical aspects, you gain a deeper understanding of how regression algorithms unveil the hidden patterns within your data, enabling you to make informed predictions and solve real-world problems.
Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information. Working with vector data is tough because regular databases, which usually handle one piece of information at a time, can’t handle the complexity and large amount of this type of data.
In this tutorial, well explore how OpenSearch performs k-NN (k-NearestNeighbor) search on embeddings. Each word or sentence is mapped to a high-dimensional vector space, where similar meanings cluster together. OpenSearch uses k-NearestNeighbors (k-NN) search to find the most similar embeddings in the dataset.
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. ClusteringClustering groups similar data points based on their attributes. What is data mining?
The following image uses these embeddings to visualize how topics are clustered based on similarity and meaning. You can then say that if an article is clustered closely to one of these embeddings, it can be classified with the associated topic. This is the k-nearestneighbor (k-NN) algorithm.
Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificial intelligence. Machine learning algorithms are specialized computational models designed to analyze data, recognize patterns, and make informed predictions or decisions.
Example: Determining whether an email is spam or not based on features like word frequency and sender information. k-NearestNeighbors (k-NN) k-NN is a simple algorithm that classifies new instances based on the majority class among its knearest neighbours in the training dataset.
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. MongoDB Atlas Vector Search uses a technique called k-nearestneighbors (k-NN) to search for similar vectors. k-NN works by finding the k most similar vectors to a given vector.
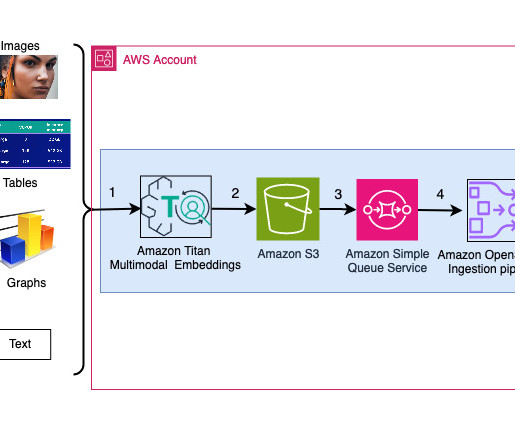
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. For more information on managing credentials securely, see the AWS Boto3 documentation. The closer vectors are to one another in this space, the more similar the information they represent is.
A sector that is currently being influenced by machine learning is the geospatial sector, through well-crafted algorithms that improve data analysis through mapping techniques such as image classification, object detection, spatial clustering, and predictive modeling, revolutionizing how we understand and interact with geographic information.
The implementation included a provisioned three-node sharded OpenSearch Service cluster. Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks. For more information, contact us at info@flotorch.ai. Each provisioned node was r7g.4xlarge,
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI.
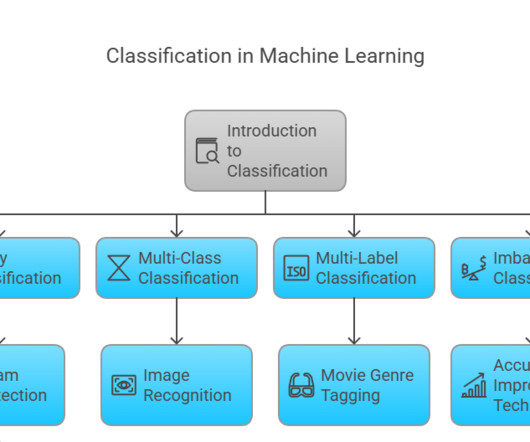
Examples include: Classifying species of plants Categorizing images into animals, vehicles, or landscapes Algorithms like Random Forests, Naive Bayes, and K-NearestNeighbors (KNN) are commonly used for multi-class classification. Each instance is assigned to one of several predefined categories.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
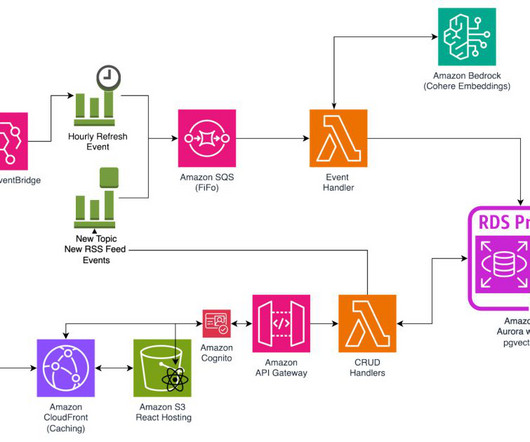
Summary Key Takeaways Citation Information Build a Search Engine: Setting Up AWS OpenSearch Were launching an exciting new series, and this time, were venturing into something new experimenting with cloud infrastructure for the first time! Jump Right To The Downloads Section Introduction What Is AWS OpenSearch?
Adding such extra information should improve the classification compared to the previous method (Principle Label Space Transformation). The prediction is then done using a k-nearestneighbor method within the embedding space. The feature space reduction is performed by aggregating clusters of features of balanced size.
Significantly, the technique allows the model to work independently by discovering its patterns and previously undetected information. There are different kinds of unsupervised learning algorithms, including clustering, anomaly detection, neural networks, etc. Therefore, it mainly deals with unlabelled data.
New users may find establishing a user profile vector difficult due to limited information about their interests. Like content-based recommendations, collaborative systems have their limitations: Identifying the -closest users for new users is difficult because of the limited information about their interests.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decision tree.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decision tree.
movie titles , directors , and release years ), ensuring that search results include rich, meaningful information. e "discovery.type=single-node" : Runs OpenSearch as a single-node cluster (since were not setting up a distributed system locally). After running this command, OpenSearch should now be running locally on port 9200.
Common machine learning algorithms for supervised learning include: K-nearestneighbor (KNN) algorithm : This algorithm is a density-based classifier or regression modeling tool used for anomaly detection. “Means,” or average data, refers to the points in the center of the cluster that all other data is related to.
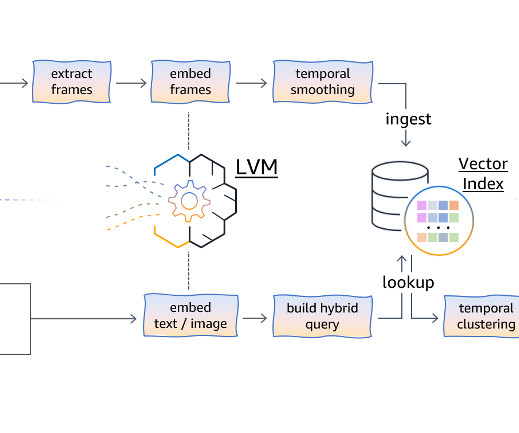
We introduce some use case-specific methods, such as temporal frame smoothing and clustering, to enhance the video search performance. These extracted frames are then passed through an embedding module, which uses the LVM to map each frame into a high-dimensional vector representation containing its semantic information.
Logistic Regression K-NearestNeighbors (K-NN) Support Vector Machine (SVM) Kernel SVM Naive Bayes Decision Tree Classification Random Forest Classification I will not go too deep about these algorithms in this article, but it’s worth it for you to do it yourself.
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. Embeddings are vector representations of text that capture semantic and contextual information.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
Even for simple tasks like information extraction, locating entities and relations can take a half an hour or more, even for simple news stories. So the key problem here is, how can we efficiently identify the most informative training examples? Annotation at word level can actually take 10 times longer than the audio clip.
Solution overview The solution provides an implementation for answering questions using information contained in text and visual elements of a slide deck. We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. I need numbers. Up to 4x higher throughput.
For information about deploying a PyTorch model with SageMaker, refer to Deploy PyTorch Models. out" embeddings.append(json.load(open(embedding_file))[0]) Create an ML-powered unified search engine This section discusses how to create a search engine that that uses k-NN search with embeddings. unsqueeze(0).to(device)
OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing trillions of requests per month. For more information about the code sample in this post, see the GitHub repo. For more information on licensing IMDb datasets, visit developer.imdb.com.
The key to success in managing images lies in extracting the most relevant information. This can lead to enhancing accuracy but also increasing the efficiency of downstream tasks such as classification, retrieval, clusterization, and anomaly detection, to name a few. Its size must be decided depending on the use case.
Make note of the domain Amazon Resource Name (ARN) and domain endpoint, both of which can be found in the General information section of each domain on the OpenSearch Service console. For more information, see Creating connectors for third-party ML platforms. Weve created a small knowledge base comprising population information.
In many fields, finding anomalies can yield insightful data and useful information. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. It identifies regions of high data point density as clusters and flags points with low densities as anomalies.
To make the correct coverage identification, a multitude of information over time must be accounted for, including the way defenders lined up before the snap and the adjustments to offensive player movement once the ball is snapped. Advances in neural information processing systems 30 (2017). Gomez, Łukasz Kaiser, and Illia Polosukhin.
Matrix Factorization Alternating Least Squares RNNs for Music Discovery Playlist Recommendation Using Reinforcement Learning Overview World Model Design Action Head DQN Approach Summary Citation Information Spotify Music Recommendation Systems In this tutorial, you will learn about Spotify’s music recommendation systems. genre, artist, etc.)
So, foundation models, they’re pre-trained on huge corpora of data, and they have a lot of general information from the web or from these data sets. We need additional information to often adapt foundation models to particular tasks. The nice thing here is—if you think about it—they offer complimentary sources of signal.
So, foundation models, they’re pre-trained on huge corpora of data, and they have a lot of general information from the web or from these data sets. We need additional information to often adapt foundation models to particular tasks. The nice thing here is—if you think about it—they offer complimentary sources of signal.
By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Data Science is the art and science of extracting valuable information from data. What is Data Science?
The sub-categories of this approach are negative sampling, clustering, knowledge distillation, and redundancy reduction. Some common quantitative evaluations are linear probing , Knearestneighbors (KNN), and fine-tuning. More details of this approach will be described in a different article.
We must understand that not all the data samples contribute to providing valuable information. Faster Learning Curve Active Learning achieves better model performance with fewer labeled examples by focusing on the most informative cases. But why is this an important and valuable approach? Reason, presence of redundant samples.
Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. customer segmentation), clustering algorithms like K-means or hierarchical clustering might be appropriate.
A set of classes sometimes forms a group/cluster. So, we can plot the high-dimensional vector space into lower dimensions and evaluate the integrity at the cluster level. index.add(xb) # xq are query vectors, for which we need to search in xb to find the knearestneighbors. # Creating the index.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































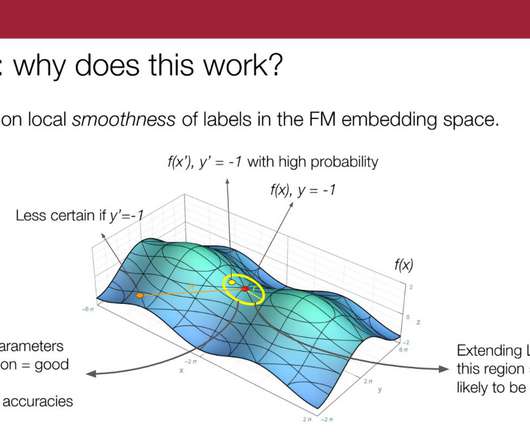
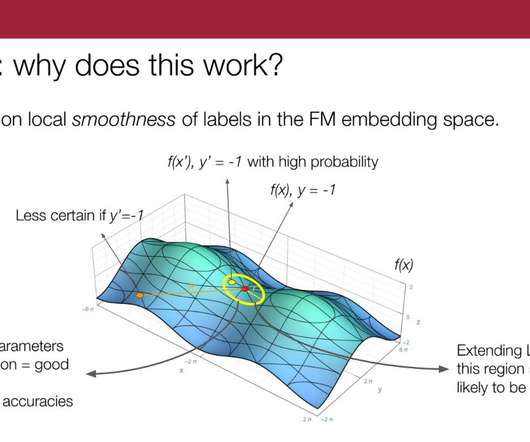











Let's personalize your content