This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cluster quorum disk is a crucial element in high-availability cluster computing, providing the necessary mechanisms to maintain operational integrity among interconnected nodes. Its function ensures that a cluster can effectively manage and coordinate resources, particularly during failover scenarios.
Clustering algorithms play a vital role in the landscape of machine learning, providing powerful techniques for grouping various data points based on their intrinsic characteristics. What are clustering algorithms? Key criteria include: The number of clusters data points can belong to.
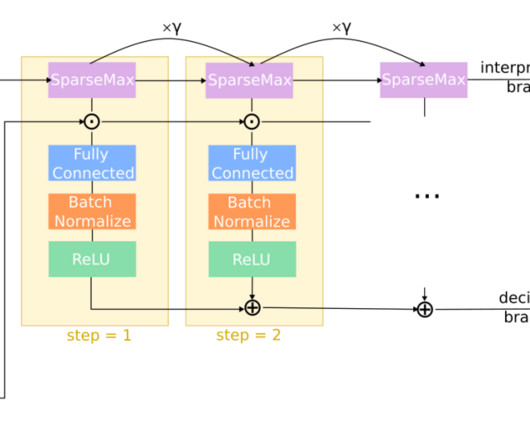
Now, researchers from MIT, Microsoft, and Google are attempting to do just that with I-Con, or Information Contrastive Learning. Each guest (data point) finds a seat (cluster) ideally near friends (similar data). The architecture behind I-Con At its core, I-Con is built on an information-theoretic foundation.
In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters. Create a new training plan.
Clustering in machine learning is a fascinating method that groups similar data points together. By organizing data into meaningful clusters, businesses and researchers can gain valuable insights into their data, facilitating decision-making across various domains. What is clustering in machine learning?
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. The major components of RELand are illustrated in Fig.
The solution is designed to provide customers with a detailed, personalized explanation of their preferred features, empowering them to make informed decisions. Requested information is intelligently fetched from multiple sources such as company product metadata, sales transactions, OEM reports, and more to generate meaningful responses.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. To address these inefficiencies, the implementation of advanced information extraction systems is crucial.
It’s like having a super-powered tool to sort through information and make better sense of the world. By comprehending these technical aspects, you gain a deeper understanding of how regression algorithms unveil the hidden patterns within your data, enabling you to make informed predictions and solve real-world problems.
What is K Means Clustering K-Means is an unsupervised machine learning approach that divides the unlabeled dataset into various clusters. K stands for clustering, which divides data points into K clusters based on how far apart they are from each other’s centres.
Summary: This article explores the fundamental differences between clustered and non-clustered index in database management. Among the different types of indexes, the clustered and non-clustered index stand out as fundamental concepts. Key Takeaways Clustered indexes sort and store data rows in a table.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Elbow curve: In unsupervised learning, particularly clustering, the elbow curve aids in determining the optimal number of clusters for a dataset. It plots the variance explained as a function of the number of clusters. The “elbow point” is a good indicator of the ideal cluster count.
From organizing vast datasets to finding similarities among complex information, unsupervised learning plays a pivotal role in enhancing decision-making processes and operational efficiencies. Autonomous classification Unsupervised learning allows systems to effectively group unsorted information. What is unsupervised learning?
The company’s projection of a $6090 billion AI market by 2027 is contingent on aggressive cluster deployments and sustained capital expenditure, factors that may not fully materialize. However, this growth assumes ideal conditionssustained capital expenditures, aggressive cluster deployments, and limited disruption from competitors.
Solution overview The steps to implement the solution are as follows: Create the EKS cluster. For more information on how to view and increase your quotas, refer to Amazon EC2 service quotas. Create the EKS cluster If you don’t have an existing EKS cluster, you can create one using eksctl. Prepare the Docker image.
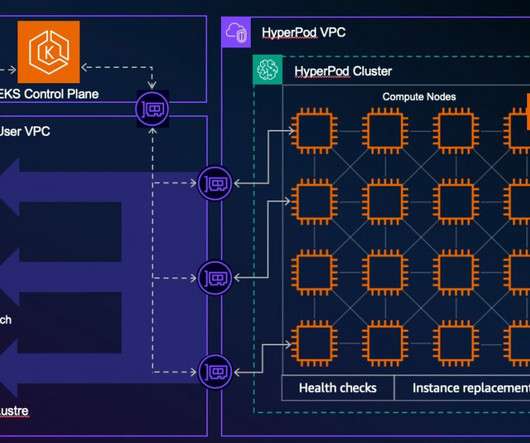
Solution overview Implementing the solution consists of the following high-level steps: Set up your environment and the permissions to access Amazon HyperPod clusters in SageMaker Studio. You can now use SageMaker Studio to discover the SageMaker HyperPod clusters, and view cluster details and metrics.
Now, for this weeks issue, we have a very interesting article on information theory, exploring self-information, entropy, cross-entropy, and KL divergence these concepts bridge probability theory with real-world applications. Ill attend many discussions and am excited to meet some of you there.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. It involves multiple data handling processes, like updating, deleting, or changing information. IVF or Inverted File Index divides the vector space into clusters and creates an inverted file for each cluster.
They constitute essential tools for statistical analysis, hypothesis testing, and predictive modeling, furnishing a systematic approach to evaluate, analyze, and make informed decisions in scenarios involving randomness and unpredictability. It’s like continually refining your knowledge as you gather more data.
The first vase was a cluster of four vessels, all at different levels For the exhibition, Front presented the three vases alongside the sketches they were based on. This involved feeding it information and images of objects they had previously designed so it would learn their style and approach.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
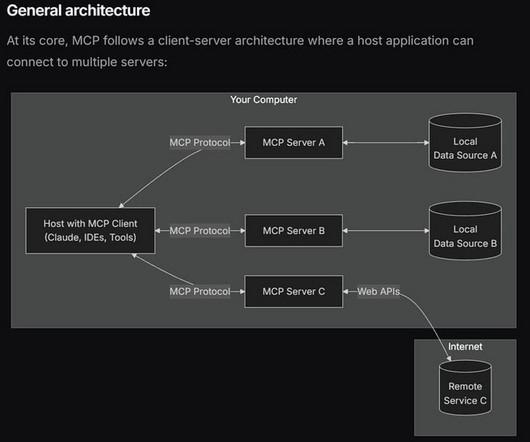
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
Artificial intelligence is changing everything and its impact on high availability (HA) clustering is no exception. The way in which AI and HA are coming together is making clusters more resilient, self-sustaining, and increasingly smarter at handling workloads.
From vCenter, administrators can configure and control ESXi hosts, datacenters, clusters, traditional storage, software-defined storage, traditional networking, software-defined networking, and all other aspects of the vSphere architecture. VMware “clustering” is purely for virtualization purposes.
These FMs work well for many use cases but lack domain-specific information that limits their performance at certain tasks. Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures.
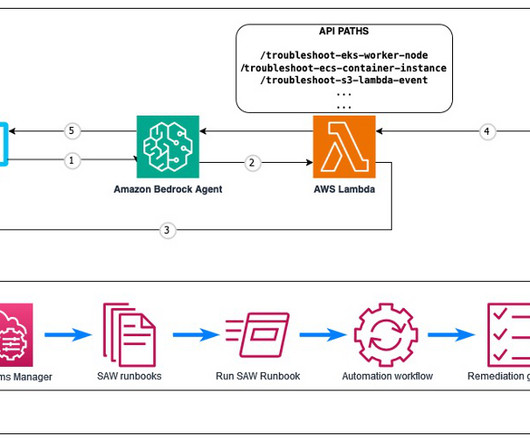
Solution overview Although the solution is versatile and can be adapted to use a variety of AWS Support Automation Workflows, we focus on a specific example: troubleshooting an Amazon Elastic Kubernetes Service (Amazon EKS) worker node that failed to join a cluster. For example, Why isnt my EKS worker node joining the cluster?
OpenAI takes down Iranian cluster using ChatGPT to craft fake news BBC’s Programme Director for Generative AI, Pete Archer, emphasized that publishers should control how their content is used and that AI companies need to disclose how their assistants process news, including error rates. Featured image credit: Kerem Glen/Ideogram
This method of analysis is essential across various fields, from market research to public health, making it a cornerstone of informed decision-making. Cluster sampling Cluster sampling groups the population into clusters, from which random samples are chosen. What is data sampling?
Analysts can use this information to provide incentives to buyers and sellers who frequently use the site, to attract new users, and to drive advertising and promotions. You’re now ready to sign in to both Aurora MySQL cluster and Amazon Redshift Serverless data warehouse and run some basic commands to test them. Port: Redshift 5439.
During the training process, our SageMaker HyperPod cluster was connected to this S3 bucket, enabling effortless retrieval of the dataset elements as needed. The integration of Amazon S3 and the SageMaker HyperPod cluster exemplifies the power of the AWS ecosystem, where various services work together seamlessly to support complex workflows.
our feed and ranking models) that would ingest vast amounts of information to make accurate recommendations that power most of our products. The number of failures scales with the size of the cluster, and having a job that spans the cluster makes it necessary to keep adequate spare capacity to restart the job as soon as possible.
Dimensionality reduction techniques To effectively visualize high-dimensional data, the embedding projector employs several dimensionality reduction techniques, including: Principal Component Analysis (PCA): A statistical method used to transform large datasets into smaller ones while retaining the most important information.
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
This unique blend allows models to learn more effectively from the available information, making it easier to address classification problems without needing to label every data point. K-means works by partitioning data into a number of clusters based on feature similarity.
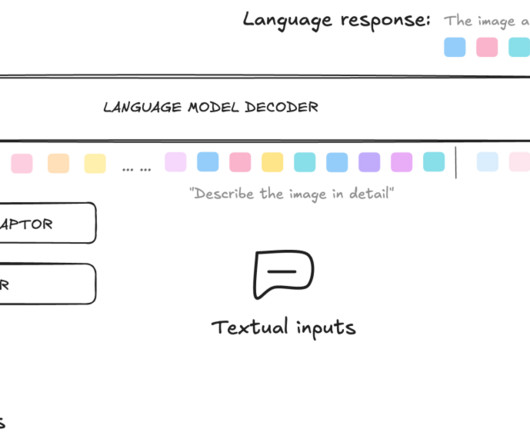
This conversational agent offers a new intuitive way to access the extensive quantity of seed product information to enable seed recommendations, providing farmers and sales representatives with an additional tool to quickly retrieve relevant seed information, complementing their expertise and supporting collaborative, informed decision-making.
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. A Ray cluster consists of a single head node and a number of connected worker nodes. Ray clusters and Kubernetes clusters pair well together.
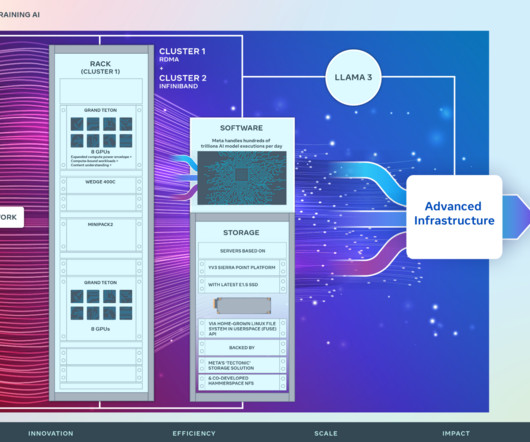
Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We use this cluster design for Llama 3 training. We built these clusters on top of Grand Teton , OpenRack , and PyTorch and continue to push open innovation across the industry. The other cluster features an NVIDIA Quantum2 InfiniBand fabric.
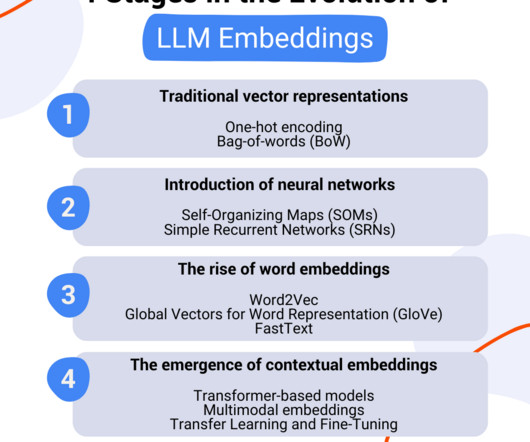
Stage 2: Introduction of neural networks The next step for LLM embeddings was the introduction of neural networks to capture the contextual information within the data. SOMs work to bring down the information into a 2-dimensional map where similar data points form clusters, providing a starting point for advanced embeddings.
Hadoop has become synonymous with big data processing, transforming how organizations manage vast quantities of information. Hadoop is an open-source framework that supports distributed data processing across clusters of computers. This architecture allows efficient file access and management within a cluster environment.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.
This is used for tasks like clustering, dimensionality reduction, and anomaly detection. For example, clustering customers based on their purchase history to identify different customer segments. Feature engineering: Creating informative features can help reduce bias and improve model performance.
Unlike traditional, table-like structures, they excel at handling the intricate, multi-dimensional nature of patient information. Working with vector data is tough because regular databases, which usually handle one piece of information at a time, can’t handle the complexity and large amount of this type of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content