This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
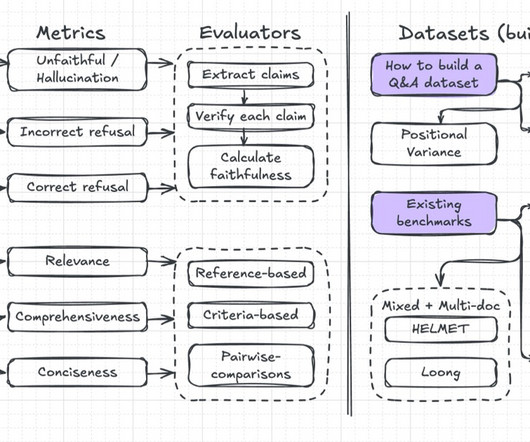
eugeneyan Start Here Writing Speaking Prototyping About Evaluating Long-Context Question & Answer Systems [ llm eval survey ] · 28 min read While evaluating Q&A systems is straightforward with short paragraphs, complexity increases as documents grow larger. Helpfulness: How relevant, comprehensive, and useful the response is for the user.
Python is a powerful and versatile programming language that has become increasingly popular in the field of data science. NumPy NumPy is a fundamental package for scientific computing in Python. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python.
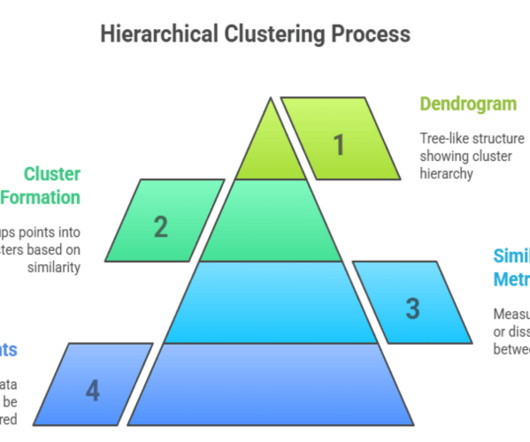
Summary: Hierarchical clustering in machine learning organizes data into nested clusters without predefining cluster numbers. While computationally intensive, it excels in interpretability and diverse applications, with practical implementations available in Python for exploratory data analysis.
Cluster Setup Crusoe graciously lent us a cluster of 300 L40S GPUs. torchft can have many, many hosts in each replica group, but for this cluster, a single host/10 gpus per replica group had the best performance due to limited network bandwidth. If you have a new use case you’d like to collaborate on, please reach out!
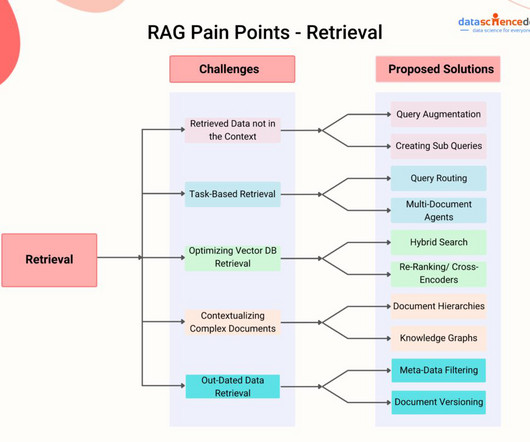
For businesses, RAG offers a powerful way to use internal knowledge by connecting company documentation to a generative AI model. When an employee asks a question, the RAG system retrieves relevant information from the company’s internal documents and uses this context to generate an accurate, company-specific response.
Python is a powerful and versatile programming language that has become increasingly popular in the field of data science. NumPy NumPy is a fundamental package for scientific computing in Python. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python.
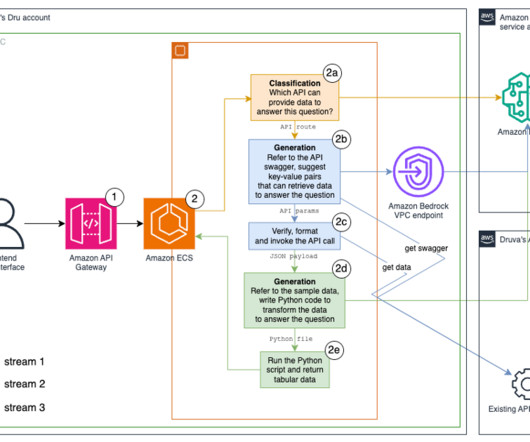
Agent architecture The following diagram illustrates the serverless agent architecture with standard authorization and real-time interaction, and an LLM agent layer using Amazon Bedrock Agents for multi-knowledge base and backend orchestration using API or Python executors. Domain-scoped agents enable code reuse across multiple agents.
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
Atlas is a multi-cloud database service provided by MongoDB in which the developers can create clusters, databases and indexes directly in the cloud, without installing anything locally. Get Started with Atlas MongoDB Atlas After the Cluster has been created, its time to create a Database and a collection.
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. As the global Python market is projected to reach USD 100.6
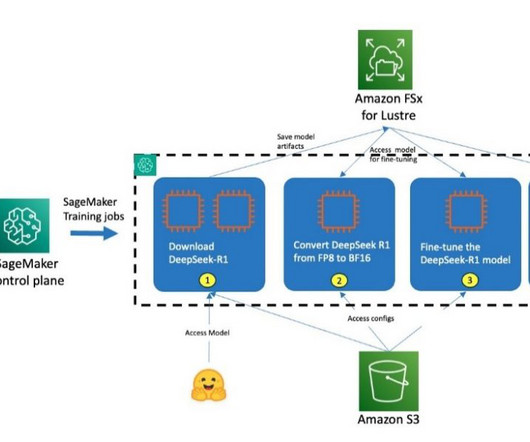
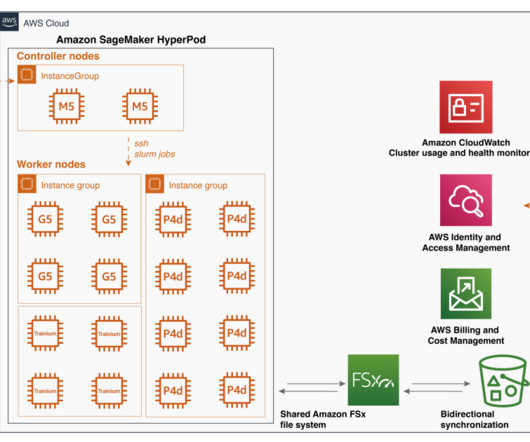
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
Rise of data lakes Data lakes originated in Hadoop clusters during the early 2000s and offered a cost-effective means of storing a variety of data types, including structured, semi-structured, and unstructured data. Decoupled storage and compute: Enhanced scalability through separate server clusters for storage and processing.
These diagrams serve as essential communication tools for stakeholders, documentation of compliance requirements, and blueprints for implementation teams. Set up your environment Before you can start creating diagrams, you need to set up your environment with Amazon Q CLI, the AWS Diagram MCP server, and AWS Documentation MCP server.
Tesla’s Automated Driving Documents Have Been Requested by The U.S. Create Audience Segments Using K-Means Clustering, Churn Prevention with Reinforcement Learning… was originally published in ODSCJournal on Medium, where people are continuing the conversation by highlighting and responding to this story.
For example, imagine a consulting firm that manages documentation for multiple healthcare providerseach customers sensitive patient records and operational documents must remain strictly separated. Using the query embedding and the metadata filter, relevant documents are retrieved from the knowledge base.
Ray is an open source framework that makes it straightforward to create, deploy, and optimize distributed Python jobs. At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. Ray clusters and Kubernetes clusters pair well together.
Document Vectors With the success of word embeddings , it’s understood that entire documents can be represented in a similar way. Document Vectors With the success of word embeddings , it’s understood that entire documents can be represented in a similar way. Let’s create a table to hold our document vectors.
Intelligent responses and a direct conduit to Druva’s documentation – Users can gain in-depth knowledge about product features and functionalities without manual searches or watching training videos. Generate and run data transformation Python code. A custom Python function runs the Python code and returns the answer in tabular format.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. Fine-tune using the SageMaker Python SDK You can also fine-tune Meta Llama 3.2
Home Table of Contents Introduction to GitHub Actions for Python Projects Introduction What Is CICD? For Python projects, CI/CD pipelines ensure that your code is consistently integrated and delivered with high quality and reliability. Git is the most commonly used VCS for Python projects, enabling collaboration and version tracking.
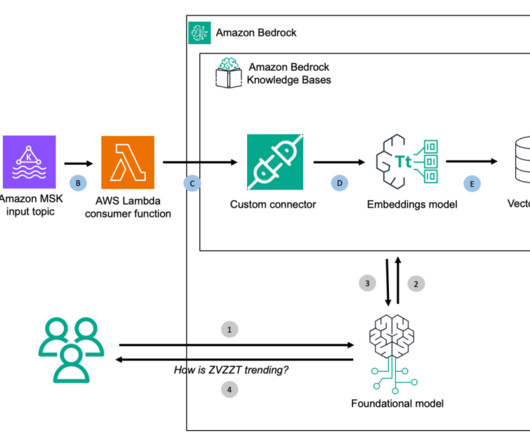
With custom data connectors, you can quickly ingest specific documents from custom data sources without requiring a full sync and ingest streaming data without the need for intermediary storage. The next step is to use a SageMaker Studio terminal instance to connect to the MSK cluster and create the test stream topic.
A users question is used as the query to retrieve relevant documents from a database. The documents returned by the search are added to the prompt that is passed to the LLM together with the users question. Source Step 1: Setting up Well begin by installing the necessary dependencies (I used Python 3.11.4 langchain-openai== 0.0.6
With HyperPod, users can begin the process by connecting to the login/head node of the Slurm cluster. Alternatively, you can also use the AWS CloudFormation template provided in the Own Account workshop and follow the instructions to set up a cluster and a development environment to access and submit jobs to the cluster.
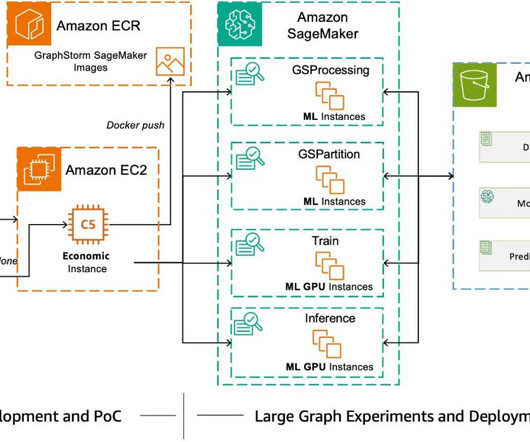
Although GraphStorm can run efficiently on single instances for small graphs, it truly shines when scaling to enterprise-level graphs in distributed mode using a cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances or Amazon SageMaker. Today, AWS AI released GraphStorm v0.4. billion edges after adding reverse edges.
Its agent for software development can solve complex tasks that go beyond code suggestions, such as building entire application features, refactoring code, or generating documentation. Attendees will learn practical applications of generative AI for streamlining and automating document-centric workflows. Hear from Availity on how 1.5
In this project, we code in Python. Downloading YouTube Comments via Python API: The project starts by extracting comments from YouTube videos related to this specific movie. We can do this by using YouTube APIs, which facilitates access to user comments through Python. The end product? Created with ChatGPT-DALL-E 2.
For instance, when developing a medical search engine, obtaining a large dataset of real user queries and relevant documents is often infeasible due to privacy concerns surrounding personal health information. These PDFs will serve as the source for generating document chunks.
Common Challenges in Data Ingestion Pipeline Challenge 1: Data Extraction: Parsing Complex Data Structures: Extracting data from various types of documents, such as PDFs with embedded tables or images, can be challenging. Program synthesis for symbolic reasoning, utilizing languages like Python or SQL. However, you know the catch.
Scikit-learn stands out as a prominent Python library in the machine learning realm, providing a versatile toolkit for data scientists and enthusiasts alike. Scikit-learn is an open-source library that simplifies machine learning in Python. Scikit-learn is an open-source library that simplifies machine learning in Python.
These services support single GPU to HyperPods (cluster of GPUs) for training and include built-in FMOps tools for tracking, debugging, and deployment. Having access to a JupyterLab IDE with Python 3.9, To get started, complete the following steps: Install the latest version of the sagemaker-python-sdk using pip. 3.10, or 3.11
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
The algorithm learns to find patterns or structure in the data by clustering similar data points together. WHAT IS CLUSTERING? Clustering is an unsupervised machine learning technique that is used to group similar entities. Those groups are referred to as clusters.
How to implement Multichannel transcription with AssemblyAI You can use the API or one of the AssemblyAI SDKs to implement Multichannel transcription (see developer documentation ). Both traditional clustering methods like K-means, or more advanced algorithms employing neural networks are common.
You’ll sign up for a Qdrant cloud account, install the necessary libraries, set up our environment variables, and instantiate a cluster — all the necessary steps to start building something. Check out the documentation to learn how to get set up locally. Source: Author You’ll need to create your cluster and get your API key.
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It is also very common as well to combine K-Means with PCA for visualizing the clustering results, and many clustering applications follow that path (e.g. this link ).
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. As part of a single cluster run, you can spin up a cluster of Trn1 instances with Trainium accelerators. Trn1 UltraClusters can host up to 30,000 Trainium devices and deliver up to 6 exaflops of compute in a single cluster.
You can explore its capabilities through the official Azure ML Studio documentation. Azure ML SDK : For those who prefer a code-first approach, the Azure Machine Learning Python SDK allows data scientists to work in familiar environments like Jupyter notebooks while leveraging Azure’s capabilities. Awesome, right?
It is similar to TensorFlow, but it is designed to be more Pythonic. Scikit-learn Scikit-learn is an open-source machine learning library for Python. TensorFlow was also used by Netflix to improve its recommendation engine. PyTorch PyTorch is another open-source software library for numerical computation using data flow graphs.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
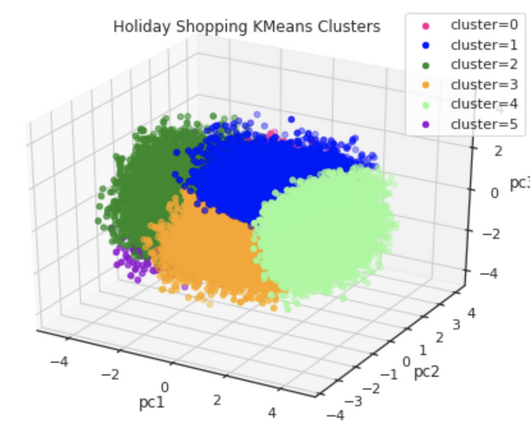
Here is an example plot we will create by just asking in plain English to create 3 clusters (using kmeans) using income and spending variables, and present the breakdown of spending for each cluster without writing any code. Streamlit is an open-source Python library to create interactive web applications and data dashboards.
However, this also calls for the need to build processes to split large text data from various documents, which is required for RAG applications, into smaller chunks so that they can be embedded and retrieved efficiently as vectors. We can split a large document or text into smaller chunks. Return the chunks as an ARRAY.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content