This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Deeplearning is transforming the landscape of artificial intelligence (AI) by mimicking the way humans learn and interpret complex data. What is deeplearning? Deeplearning is a subset of artificial intelligence that utilizes neural networks to process complex data and generate predictions.
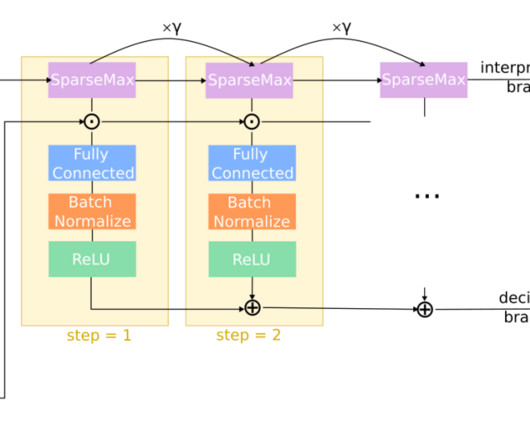
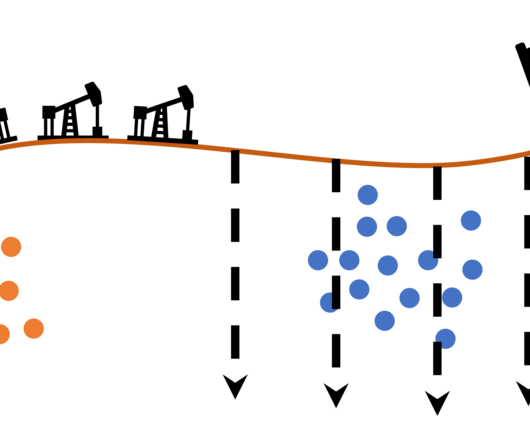
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. The major components of RELand are illustrated in Fig.
Underpinning most artificial intelligence (AI) deeplearning is a subset of machine learning that uses multi-layered neural networks to simulate the complex decision-making power of the human brain. Deeplearning requires a tremendous amount of computing power.
ClusteringClustering groups similar data points based on their attributes. One common example is k-means clustering, which segments data into distinct groups for analysis. They’re pivotal in deeplearning and are widely applied in image and speech recognition.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
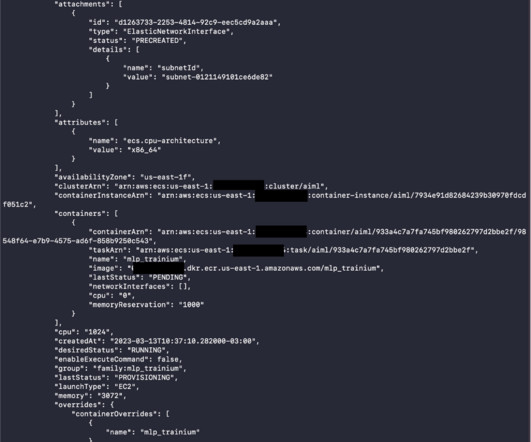
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deeplearning training. Create a task definition to define an ML training job to be run by Amazon ECS.
These services support single GPU to HyperPods (cluster of GPUs) for training and include built-in FMOps tools for tracking, debugging, and deployment. For a comprehensive list of supported deeplearning container images, refer to the available Amazon SageMaker DeepLearning Containers.
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
Libraries such as DeepSpeed (an open-source deeplearning optimization library for PyTorch) address some of these challenges, and can help accelerate model development and training. Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. Pre-training of a 1.5-billion-parameter
By analyzing and identifying patterns within this data, supervised learning algorithms can predict outcomes for new, unseen inputs. Definition of supervised learning At its core, supervised learning utilizes labeled data to inform a machine learning model.
Since then, this feature has been integrated into many of our managed Amazon Machine Images (AMIs), such as the DeepLearning AMI and the AWS ParallelCluster AMI. Create an EKS cluster with a node group This group includes a GPU instance family of your choice; in this example, we use the g5.2xlarge instance type. env-config.sh
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Building a Machine Learning platform (Lemonade). Design Patterns in Machine Learning for MLOps (by Pier Paolo Ippolito).
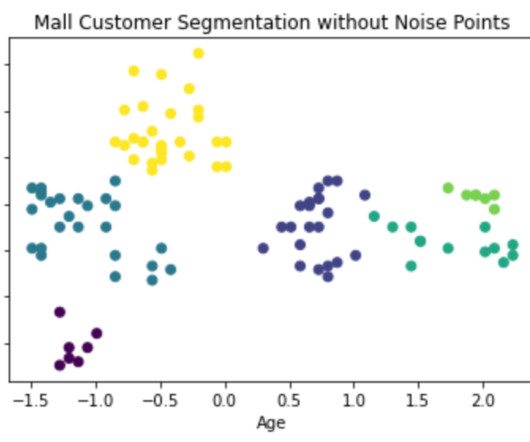
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
Figure 3 illustrates the visualization of the latent space and the process we discussed in the story, which aligns with the technical definition of the encoder and decoder. This can be helpful for visualization, data compression, and speeding up other machine learning algorithms. Or has to involve complex mathematics and equations?
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learneddefinitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
It’s fantastic for quickly developing high-quality models without deep ML expertise. Compute Resources : Azure ML provides scalable compute options like training clusters, inference clusters, and compute instances that can be automatically scaled based on workload demands. DeepLearning with Python by Francois Chollet.
Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. Also, this connector contains the functionality to automatically load feature definitions to help with creating feature groups. To do so, open the notebook 4b-processing-rs-to-fs.ipynb in your SageMaker Studio environment.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. The following figure shows schema definition and model which reference it. Docker images : ML models and applications are containerized using Docker.
The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering. The idea is to sort the labels into clusters to create a meta-label space.
Recent years have shown amazing growth in deeplearning neural networks (DNNs). Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete.
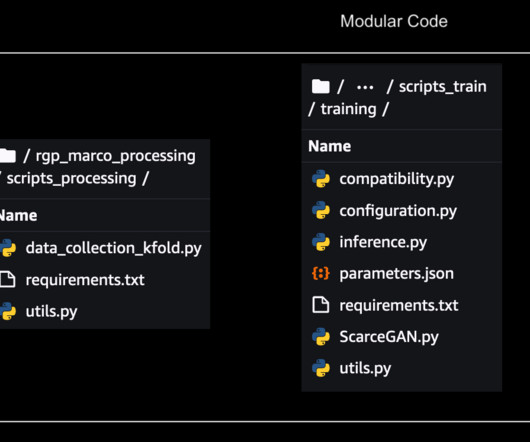
They’ve built a deep-learning model ScarceGAN, which focuses on identification of extremely rare or scarce samples from multi-dimensional longitudinal telemetry data with small and weak labels. This work has been published in CIKM’21 and is open source for rare class identification for any longitudinal telemetry data.
Now, with today’s announcement, you have another straightforward compute option for workflows that need to train or fine-tune demanding deeplearning models: running them on Trainium. Based in Canada, he helps customers deploy and optimize deeplearning training and inference workloads using AWS Inferentia and AWS Trainium.
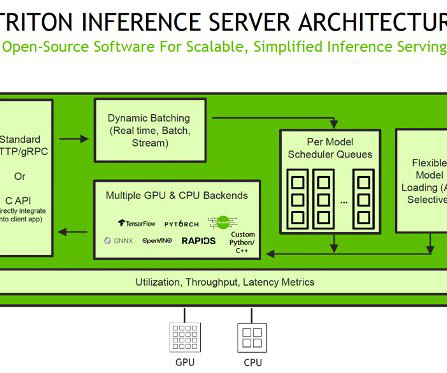
TensorRT is an SDK developed by NVIDIA that provides a high-performance deeplearning inference library. It’s optimized for NVIDIA GPUs and provides a way to accelerate deeplearning inference in production environments. Triton Inference Server supports ONNX as a model format.
Today, many modern Speech-to-Text APIs and Speaker Diarization libraries apply advanced DeepLearning models to perform tasks (A) and (B) near human-level accuracy, significantly increasing the utility of Speaker Diarization APIs. An embedding is a DeepLearning model’s low-dimensional representation of an input.
Patrick Lewis “We definitely would have put more thought into the name had we known our work would become so widespread,” Lewis said in an interview from Singapore, where he was sharing his ideas with a regional conference of database developers.
In this post, we share how LotteON improved their recommendation service using Amazon SageMaker and machine learning operations (MLOps). Therefore, we decided to introduce a deeplearning-based recommendation algorithm that can identify not only linear relationships in the data, but also more complex relationships.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
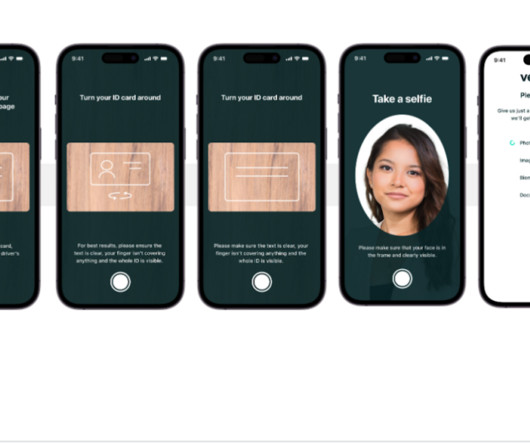
As an AI-powered solution, Veriff needs to create and run dozens of machine learning (ML) models in a cost-effective way. These models range from lightweight tree-based models to deeplearning computer vision models, which need to run on GPUs to achieve low latency and improve the user experience. Miguel Ferreira works as a Sr.
ClusteringClustering is a class of algorithms that segregates the data into a set of definiteclusters such that similar points lie in the same cluster and dissimilar points lie in different clusters. Several clustering algorithms (e.g., Figure 9: K -means clustering algorithm (source: Javatpoint ).
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deeplearning. This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape.
Model scale has become an absolutely essential aspect of modern deeplearning practice. And if there’s one thing we’ve learned from our collaborations at UCSD and with our industry partners, it’s that deeplearning jobs are never run in isolation. Why train large models? And why train many of them?
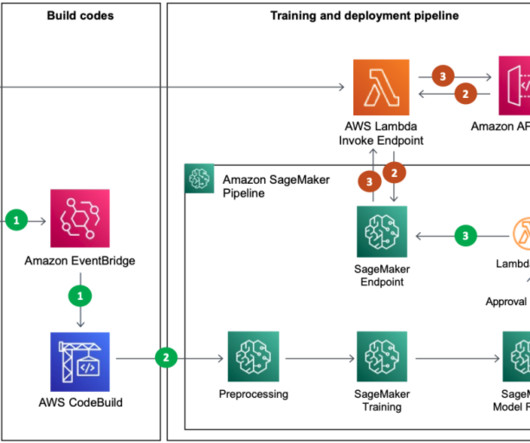
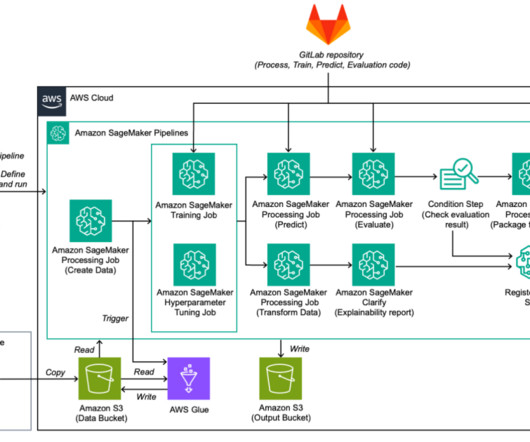
The first repository contains the definition and build code for the ML pipeline, and the second repository contains the code that runs inside each step, such as processing, training, prediction, and evaluation. This model is deeplearning rather than tree-based and has introduced noticeable improvements in online model performance.
Let’s explore the specific role and responsibilities of a machine learning engineer: Definition and scope of a machine learning engineer A machine learning engineer is a professional who focuses on designing, developing, and implementing machine learning models and systems.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. al 600+: Key technological concepts of generative AI 300+: DeepLearning — the core of any generative AI model: Deeplearning is a central concept of traditional AI that has been adopted and further developed in generative AI.
NOTES, DEEPLEARNING, REMOTE SENSING, ADVANCED METHODS, SELF-SUPERVISED LEARNING A note of the paper I have read Photo by Kelly Sikkema on Unsplash Hi everyone, In today’s story, I would share notes I took from 32 pages of Wang et al., 2022 Deeplearning notoriously needs a lot of data in training. 2022’s paper.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments.
The unprecedented amount of available data has been critical to many of deeplearning’s recent successes, but this big data brings its own problems. Active learning is a really powerful data selection technique for reducing labeling costs. It’s computationally demanding, resource hungry, and often redundant.
The unprecedented amount of available data has been critical to many of deeplearning’s recent successes, but this big data brings its own problems. Active learning is a really powerful data selection technique for reducing labeling costs. It’s computationally demanding, resource hungry, and often redundant.
The unprecedented amount of available data has been critical to many of deeplearning’s recent successes, but this big data brings its own problems. Active learning is a really powerful data selection technique for reducing labeling costs. It’s computationally demanding, resource hungry, and often redundant.
This can lead to enhancing accuracy but also increasing the efficiency of downstream tasks such as classification, retrieval, clusterization, and anomaly detection, to name a few. This can lead to higher accuracy in tasks like image classification and clusterization due to the fact that noise and unnecessary information are reduced.
While there is not a single definition of emergence that is used across domains, all definitions boil down to the same essential phenomenon of small changes to the quantitative parameters of a system making huge changes to its qualitative behavior.
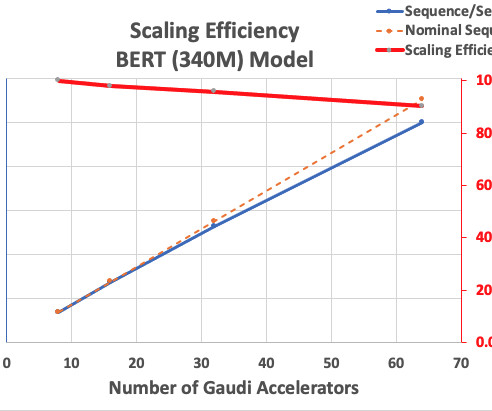
Databricks is getting up to 40% better price-performance with Trainium-based instances to train large-scale deeplearning models. Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. thousands of text documents).
TL;DR GPUs can greatly accelerate deeplearning model training, as they are specialized for performing the tensor operations at the heart of neural networks. Utilization The GPU utilization metric quantifies how the GPU is engaged during the training of deep-learning models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content