This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
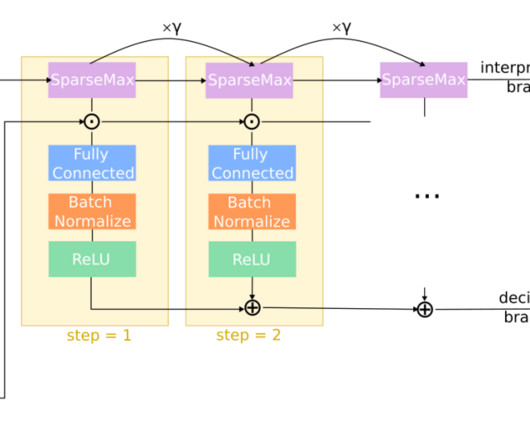
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. The major components of RELand are illustrated in Fig.
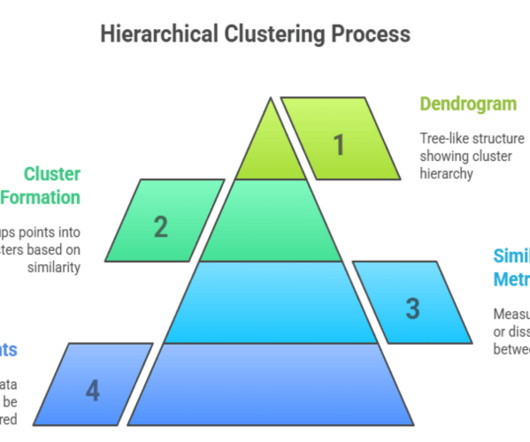
Summary: Hierarchical clustering in machine learning organizes data into nested clusters without predefining cluster numbers. Unlike partition-based methods such as K-means, hierarchical clustering builds a nested tree-like structure called a dendrogram that reveals the multi-level relationships between data points.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Clustering: Grouping similar data points to identify patterns. Key techniques in text mining Text mining has significantly advanced with the introduction of deeplearning. This development allows for more nuanced and sophisticated analyses as neural networks iteratively learn from vast datasets.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
Unsupervised Learning Algorithms Unsupervised learning covers all and any learning procedures in which the data has no labels or targets: you want to discover some hidden structure or pattern in that data. Hence you will have clustering and dimensionality reduction as the main two kinds of unsupervised learning.
Figure 1: Gaussian mixture model illustration [Image by AI] Introduction In a time where deeplearning (DL) and transformers steal the spotlight, its easy to forget about classic algorithms like K-means, DBSCAN, and GMM. Consider the everyday clustering puzzles: customer segmentation, social network analysis, or image segmentation.
Mixed Precision Training with FP8 As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deeplearning workloads. More details about FP8 can be found at FP8 Formats For DeepLearning. supports the Llama 3.1 (and Outside of work, he enjoys running, hiking, and cooking.
Researchers, data scientists, and machine learning practitioners alike have embraced t-SNE for its effectiveness in transforming extensive datasets into visual representations, enabling a clearer understanding of relationships, clusters, and patterns within the data.
Its extensive libraries, such as TensorFlow, PyTorch, and Scikit-learn, streamline the development of machine learning and deeplearning models. To excel in ML, you must understand its key methodologies: Supervised Learning: Involves training models on labeled datasets for tasks like classification (e.g.,
In this blog post, we will delve into the mechanics of the Grubbs test, its application in anomaly detection, and provide a practical guide on how to implement it using real-world data. Thakur, eds., Join the Newsletter! Website The post Anomaly Detection: How to Find Outliers Using the Grubbs Test appeared first on PyImageSearch.
This process relies on advanced algorithms and deeplearning models to differentiate between voices, producing a structured transcript with clear speaker boundaries. Speaker Embeddings with DeepLearning models : Once the audio is segmented, each segment is processed using a deeplearning model to extract speaker embeddings.
Gene set enrichment : Identify clusters of genes that behave similarly under perturbations and describe their common function. Single-cell ML models (SCGPT) : These use deeplearning to predict gene expression levels but struggle to provide clear biological explanations.
These resources can help you learn Python: Learn Python - Full Course for Beginners [Tutorial] - YouTube (Recommended) Python Crash Course For Beginners - YouTube TEXTBOOK: Learn Python The Hard Way Machine Learning: After you learn programming, you have to cover the basic concepts of machine learning before moving on with LLMs.
The primary components include: Graphics Processing Units (GPUs) These are specially designed for parallel processing, making them ideal for training deeplearning models. Foundation Models Foundation models are pre-trained deeplearning models that serve as the backbone for various generative applications.
In this builders’ session, learn how to pre-train an LLM using Slurm on SageMaker HyperPod. Explore the model pre-training workflow from start to finish, including setting up clusters, troubleshooting convergence issues, and running distributed training to improve model performance. You must bring your laptop to participate.
This is the goal behind Neurosymbolic AI , a new approach that merges deeplearning with coherence-driven inference (CDI). To maximize coherence by separating true and false statements into different clusters. If a proposition supports another , it gets a positive connection.
For instance: MRI Scan Analysis: Deeplearning models, particularly Convolutional Neural Networks (CNNs), are trained on large datasets of MRI scans to classify images as cancerous or non-cancerous. Classification models extensively used to analyze medical imaging data for cancer detection.
Cho provided significant contributions on the computational side, helping develop key aspects of the methodology, including spectral clustering techniques that enabled the research team to group features based on their spatial relationships. Using this framework, you can enable automatic discovery without requiring any additional data.
Figure 4: Dynamo Smart Router helps reduce unnecessary computationTo achieve this, the NVIDIA Dynamo Smart Router calculates an overlap score between an incoming request, and the KV cache blocks active across the entire distributed GPU cluster. The EKS cluster and node creation process can take 15–30 minutes to complete.
He focuses on Deeplearning including NLP and Computer Vision domains. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning.
405B for synthetic data generation and distillation to fine-tune smaller models Mixed precision training Mixed precision training is a cutting-edge optimization technique in deeplearning that balances computational efficiency with model accuracy. Ilan holds a master’s degree in mathematical economics.
By using cutting-edge generative AI and deeplearning technologies, Apoidea has developed innovative AI-powered solutions that address the unique needs of multinational banks. Amazon SageMaker HyperPod offers an effective solution for provisioning resilient clusters to run ML workloads and develop state-of-the-art models.
The underlying DeepLearning Container (DLC) of the deployment is the Large Model Inference (LMI) NeuronX DLC. He focuses on developing scalable machine learning algorithms. 32xlarge Meta Llama 3.1 32xlarge Meta Llama 3.1 70B Neuron meta-textgenerationneuron-llama-3-1-70b ml.trn1.32xlarge ml.trn1.32xlarge, ml.trn1n.32xlarge,
SVM-based classifier: Amazon Titan Embeddings In this scenario, it is likely that user interactions belonging to the three main categories ( Conversation , Services , and Document_Translation ) form distinct clusters or groups within the embedding space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
ClusteringClustering groups similar data points based on their attributes. One common example is k-means clustering, which segments data into distinct groups for analysis. They’re pivotal in deeplearning and are widely applied in image and speech recognition.
SageMaker AI provides distributed training libraries and supports various distributed training options for deeplearning tasks. The training job runs on the SageMaker training cluster by distributing the computation across the four available GPUs on the selected instance type ml.g5.12xlarge.
Each word or sentence is mapped to a high-dimensional vector space, where similar meanings cluster together. exceptions.InsecureRequestWarning) def perform_search(query_text, model_id): """ Perform a search operation using the neural query on the OpenSearch cluster. Figure 3: What Is Semantic Search? disable_warnings(urllib3.exceptions.InsecureRequestWarning)
Using the embed_documents method of the SagemakerEndpointEmbeddings instance, you generate embeddings for documents or queries, which can be used for downstream tasks like similarity search, clustering, or classification. Bryan Yost is a Principle DeepLearning Architect at Amazon Web Services Generative AI Innovation Center.
Here is a quick overview of the areas our researchers are working on: Here are our most frequent collaborator institutions: Table of Contents Oral Papers Spotlight Papers Poster Papers Accountability, Transparency, And Interpretability Active Learning And Interactive Learning Applications Causality Chemistry, Physics, And Earth Sciences Computer Vision (..)
He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deeplearning on tabular data, and robust analysis of non-parametric space-time clustering.
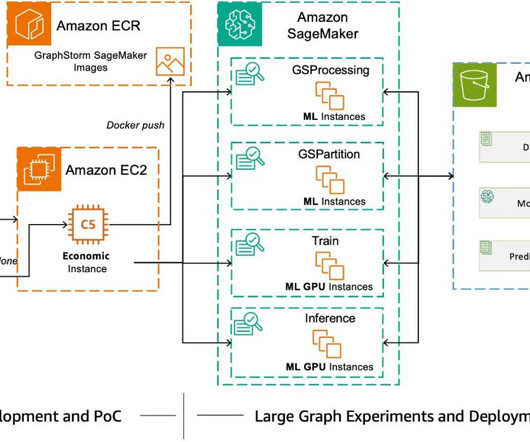
GraphStorm is a low-code enterprise graph machine learning (ML) framework that provides ML practitioners a simple way of building, training, and deploying graph ML solutions on industry-scale graph data. Today, AWS AI released GraphStorm v0.4.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. Dmitrys work covers a wide range of ML use cases, with a primary interest in Generative AI, deeplearning, and scaling ML across the enterprise.
This paper pretty much showed everyone how to train deep layers on a GPU 2014: NVIDIA released CuDNN a dedicated CUDA library for DeepLearning. We discuss the GPU memory, the processing cores, the LLM workflows happening inside them & common topologies for clustering. Photo by Thomas Foster on Unsplash 1.
It’s fantastic for quickly developing high-quality models without deep ML expertise. Compute Resources : Azure ML provides scalable compute options like training clusters, inference clusters, and compute instances that can be automatically scaled based on workload demands. DeepLearning with Python by Francois Chollet.
I have about 3 YoE training PyTorch models on HPC clusters and 1 YoE optimizing PyTorch models, including with custom CUDA kernels. Ideal job would be designing, developing (CRDs, operators), monitoring and troubleshooting K8s clusters. I currently work at a public HPC center, where I am also doing a PhD.
The rise of generative AI has significantly increased the complexity of building, training, and deploying machine learning (ML) models. It now demands deep expertise, access to vast datasets, and the management of extensive compute clusters.
Deeplearning is transforming the landscape of artificial intelligence (AI) by mimicking the way humans learn and interpret complex data. What is deeplearning? Deeplearning is a subset of artificial intelligence that utilizes neural networks to process complex data and generate predictions.
Neural networks and their integration Neural networks play a pivotal role in supervised learning, especially in complex tasks such as image and speech recognition. These models mimic the human brain’s structure, allowing for sophisticated pattern recognition and improved accuracy through deeplearning techniques.
These services support single GPU to HyperPods (cluster of GPUs) for training and include built-in FMOps tools for tracking, debugging, and deployment. For a comprehensive list of supported deeplearning container images, refer to the available Amazon SageMaker DeepLearning Containers.
Amazon OpenSearch Service is a fully managed solution that simplifies the deployment, operation, and scaling of OpenSearch clusters in the AWS Cloud. Figure 2 : Amazon OpenSearch Service for Vector Search: Demo Key Features of AWS OpenSearch Scalability: Easily scale clusters up or down based on workload demands.
e "discovery.type=single-node" : Runs OpenSearch as a single-node cluster (since were not setting up a distributed system locally). You should see details about cluster health, the number of nodes, and the OpenSearch version. You should see details about cluster health, the number of nodes, and the OpenSearch version.
Introduction: Hi everyone, recently while participating in a DeepLearning competition, I. The post An Approach towards Neural Network based Image Clustering appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content