This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. Hence, databases are important for strategic data handling and enhanced operational efficiency. Hence, databases are important for strategic data handling and enhanced operational efficiency.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. For this post we’ll use a provisioned Amazon Redshift cluster.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
The ingestion pipeline (3) ingests metadata (1) from services (2), including Amazon DataZone, AWS Glue, and Amazon Athena , to a Neptune database after converting the JSON response from the service APIs into an RDF triple format. Run SPARQL queries in the Neptune database to populate additional triples from inference rules.
On June 12, 2025 at NVIDIA GTC Paris, learn more about cuML and clustering algorithms during the hands-on workshop, Accelerate Clustering Algorithms to Achieve the Highest Performance. Data-Intensive Workloads Today’s data is growing at an unprecedented rate which makes for highly complex data processing workflows for ML.
The post assumes a basic familiarity of foundation model (FMs) and large language models (LLMs), tokens, vector embeddings, and vector databases in AWS. Vector database The vector database is a critical component of most generative AI applications. A request to generate embeddings is sent to the LLM.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The dataset was stored in an Amazon Simple Storage Service (Amazon S3) bucket, which served as a centralized data repository.
Image generated with DALL-E 3 In the fast-paced world of Machine Learning (ML) research, keeping up with the latest findings is crucial and exciting, but let’s be honest — it’s also a challenge. Enter ML Conference Paper Explorer: your sidekick in navigating the ML paper maze with ease. What’s the next big thing in ML?
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The retrieved context and the user query are used to augment a prompt template.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database.
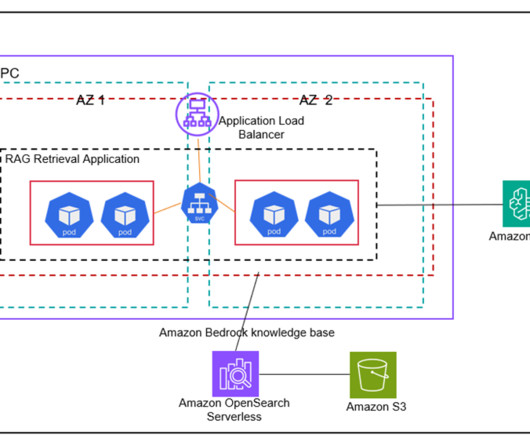
Our solution uses Amazon S3 as the source of unstructured data and populates an Amazon OpenSearch Serverless vector database via the use of Amazon Bedrock Knowledge Bases with the users existing files and folders and associated metadata. He leads cloud transformation and solution architecture for AWS customers and partners.
This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code. This is where ML CoPilot enters the scene. In this paper, the authors suggest the use of LLMs to make use of past ML experiences to suggest solutions for new ML tasks.
Thanks to machine learning (ML) and artificial intelligence (AI), it is possible to predict cellular responses and extract meaningful insights without the need for exhaustive laboratory experiments. These models use knowledge graphs databases of known biological interactionsto infer how a new gene disruption might affect a cell.
You can hear more details in the webinar this article is based on, straight from Kaegan Casey, AI/ML Solutions Architect at Seagate. from local or virtual machine to K8s cluster) and the need for bespoke deployments. from local or virtual machine to K8s cluster) and the need for bespoke deployments.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. The implementation included a provisioned three-node sharded OpenSearch Service cluster. Dr. Hemant Joshi has over 20 years of industry experience building products and services with AI/ML technologies.
With cloud computing, as compute power and data became more available, machine learning (ML) is now making an impact across every industry and is a core part of every business and industry. Amazon SageMaker Studio is the first fully integrated ML development environment (IDE) with a web-based visual interface.
Amazon SageMaker is a fully managed machine learning (ML) service providing various tools to build, train, optimize, and deploy ML models. ML insights facilitate decision-making. To assess the risk of credit applications, ML uses various data sources, thereby predicting the risk that a customer will be delinquent.
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems. These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems.
However, it lacked essential services required for machine learning (ML) applications, such as frontend and backend infrastructure, DNS, load balancers, scaling, blob storage, and managed databases. At that time, the application was deployed as a single monolithic container, which included Kafka and a database.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
By employing a multi-modal approach, the solution connects relevant data elements across various databases. The app container is deployed using a cost-optimal AWS microservice-based architecture using Amazon Elastic Container Service (Amazon ECS) clusters and AWS Fargate.
Snowpark ML is transforming the way that organizations implement AI solutions. Snowpark allows ML models and code to run on Snowflake warehouses. By “bringing the code to the data,” we’ve seen ML applications run anywhere from 4-100x faster than other architectures. library.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster.
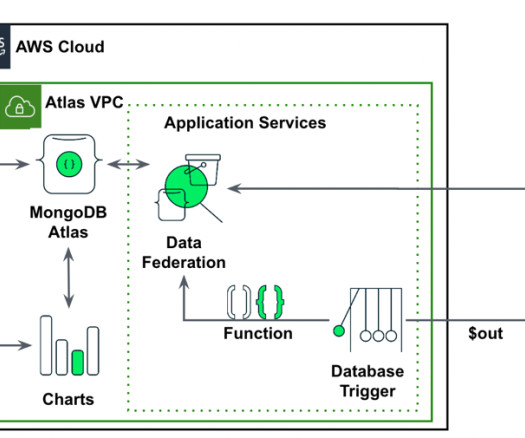
MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. If you need an automated workflow or direct ML model integration into apps, Canvas forecasting functions are accessible through APIs. Setup the Database access and Network access.
In this series, we will set up AWS OpenSearch , which will serve as a vector database for a semantic search application that well develop step by step. Amazon OpenSearch Service is a fully managed solution that simplifies the deployment, operation, and scaling of OpenSearch clusters in the AWS Cloud.
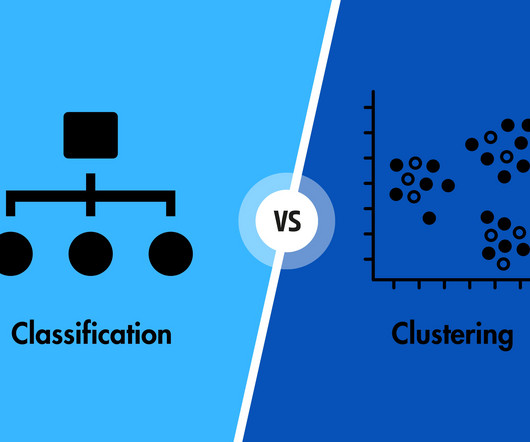
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
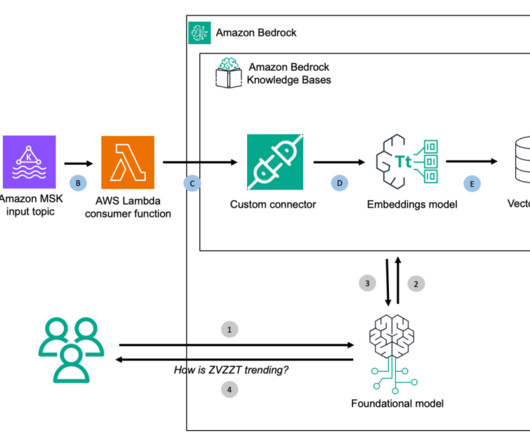
This feature chunks and converts input data into embeddings using your chosen Amazon Bedrock model and stores everything in the backend vector database. The next step is to use a SageMaker Studio terminal instance to connect to the MSK cluster and create the test stream topic. On the next screen, review your selections. ZVZZT $3,413.23
Custom geospatial machine learning : Fine-tune a specialized regression, classification, or segmentation model for geospatial machine learning (ML) tasks. For scalability and search performance, we index the embedding vectors in a vector database. Karsten holds a PhD in applied ML.
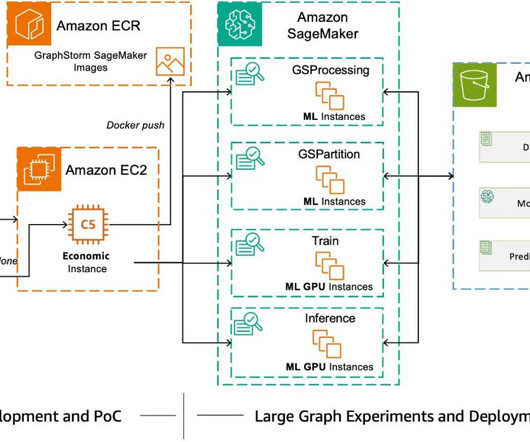
GraphStorm is a low-code enterprise graph machine learning (ML) framework that provides ML practitioners a simple way of building, training, and deploying graph ML solutions on industry-scale graph data. We encourage ML practitioners working with large graph data to try GraphStorm.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Webex’s focus on delivering inclusive collaboration experiences fuels their innovation, which uses artificial intelligence (AI) and machine learning (ML), to remove the barriers of geography, language, personality, and familiarity with technology. Its solutions are underpinned with security and privacy by design.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
The diverse and rich database of models brings unique challenges for choosing the most efficient deployment infrastructure that gives the best latency and performance. In these cases, the model sizes are smaller, which means the communication overhead with GPUs or ML accelerator instances outweighs their compute performance benefits.
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. This NoSQL database is optimized for rapid access, making sure the knowledge base remains responsive and searchable.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. For more information, see Creating connectors for third-party ML platforms. You created an OpenSearch ML model group and model that you can use to create ingest and search pipelines.
Their architecture combines high-performance FSx for Lustre storage with NVIDIA GPU clusters for training, and NVIDIA Triton Inference Server handles production deployment. Prior to his current role, he was Vice President, Relational Database Engines where he led Amazon Aurora, Redshift, and DSQL.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. What does a modern technology stack for streamlined ML processes look like?
Azure Machine Learning is Microsoft’s enterprise-grade service that provides a comprehensive environment for data scientists and ML engineers to build, train, deploy, and manage machine learning models at scale. You can explore its capabilities through the official Azure ML Studio documentation. Awesome, right?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content