This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
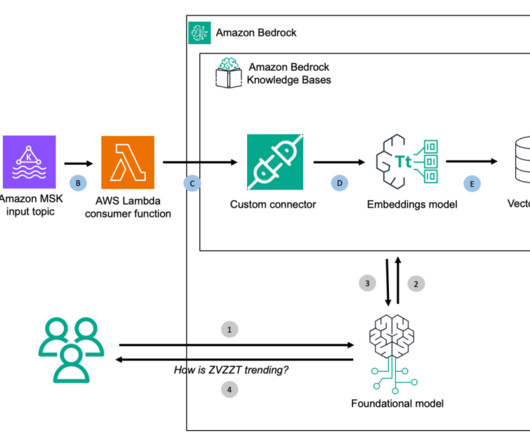
Think of the examples of clickstream data, credit card swipes, Internet of Things (IoT) sensor data, log analysis and commodity priceswhere both current data and historical trends are important to make a learned decision. In this step, you follow the detailed instructions that are mentioned at Create a topic in the Amazon MSK cluster.
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., Clusters : Clusters are groups of interconnected nodes that work together to process and store data.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Is K-means clustering different from KNN? The radar analyzes the different areas in which this company, which specializes in emerging technologies such as the blockchain, big data, cloud and the Internet of Things, as well as machine learning. Can you explain how unsupervised and supervised machine learning are different?
Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture. Some NoSQL databases are also utilized as platforms for data lakes. To preserve your digital assets, data must lastly be secured.
From there, a machine learning framework like TensorFlow, H2O, or Spark MLlib uses the historical data to train analytic models with algorithms like decision trees, clustering, or neural networks. Tiered Storage enables long-term storage with low cost and the ability to more easily operate large Kafka clusters.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special data modelling steps? You can shard your Citus database by creating a schema per tenant, as an alternative to distributing tables by a tenant ID column.
We use Knowledge Bases for Amazon Bedrock to fetch from historical data stored as embeddings in the Amazon OpenSearch Service vector database. You can use Fargate with Amazon ECS to run containers without having to manage servers, clusters, or virtual machines. You can use LCEL to build the SQL chain.
Producers and consumers A ‘producer’, in Apache Kafka architecture, is anything that can create data—for example a web server, application or application component, an Internet of Things (IoT) , device and many others. Here are a few of the most striking examples.
Processing frameworks like Hadoop enable efficient data analysis across clusters. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). Key Takeaways Big Data originates from diverse sources, including IoT and social media. What is Big Data?
Processing frameworks like Hadoop enable efficient data analysis across clusters. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). Key Takeaways Big Data originates from diverse sources, including IoT and social media. What is Big Data?
Database management is an area empowered by distributed computing, as are distributed databases, which perform faster by having tasks broken down into smaller actions. Manufacturing also deals with designing and creating Internet of Things (IoT) gadgets and tools that collect and transmit data.
This dataset comprises a multi-center critical care database collected from over 200 hospitals, which makes it ideal to test our FL experiments. We used the eICU Collaborative Research Database , a multi-center intensive care unit (ICU) database, comprising 200,859 patient unit encounters for 139,367 unique patients.
Introduction The Internet of Things (IoT) connects billions of devices, generating massive real-time data streams. IoT data visualization converts raw data generated by Internet of Things (IoT) devices into visual formats such as charts, graphs, maps, and dashboards. What is IoT Visualization?
Scalability : NiFi can be deployed in a clustered environment, enabling organizations to scale their data processing capabilities as their data needs grow. IoT Data Processing With the rise of the Internet of Things (IoT), NiFi is increasingly used to process data generated by IoT devices.
A trusted leader in AI, Internet of Things (IoT), customer experience, and network and workflow management, CCC delivers innovations that keep people’s lives moving forward when it matters most. CCC cloud technology connects more than 30,000 businesses digitizing mission-critical workflows, commerce, and customer experiences.
IoT (Internet of Things) Edge Computing: With the increasing number of connected devices and the amount of data generated, companies are implementing IoT edge computing, which uses edge devices, such as gateways, routers, or even small-scale data centers, to process and analyze data closer to the source, and reduce the need for central data centers.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content