This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
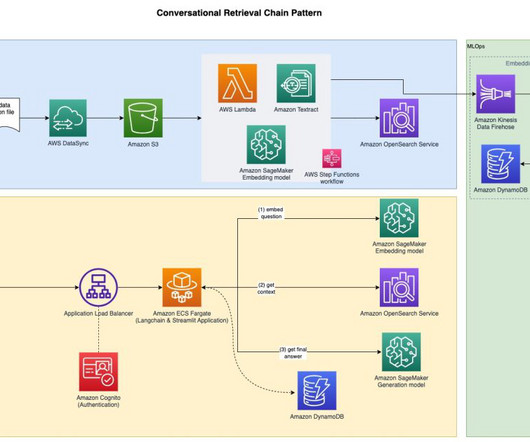
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
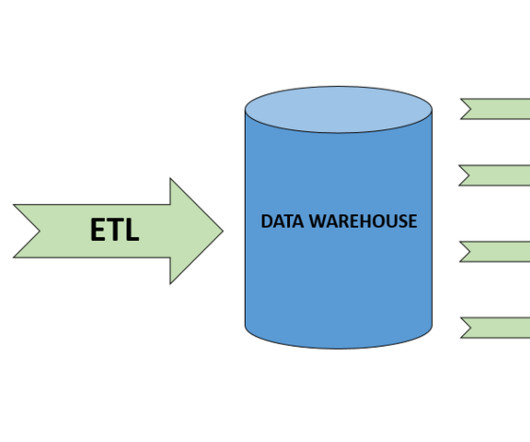
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Context Manager Pattern for Resource Management When working with resources like files, database connections, or network sockets, you need to ensure they’re properly opened and closed, even if an error occurs. Example: Suppose you’re fetching user data from a database and want to provide context when a database error occurs.
The ingestion pipeline (3) ingests metadata (1) from services (2), including Amazon DataZone, AWS Glue, and Amazon Athena , to a Neptune database after converting the JSON response from the service APIs into an RDF triple format. Run SPARQL queries in the Neptune database to populate additional triples from inference rules.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database.
Two popular players in this area are Alteryx Designer and Matillion ETL , both offering strong solutions for handling data workflows with Snowflake Data Cloud integration. Matillion ETL is purpose-built for the cloud, operating smoothly on top of your chosen data warehouse. Today we will focus on Snowflake as our cloud product.
The ETL (extract, transform, and load) technology market also boomed as the means of accessing and moving that data, with the necessary translations and mappings required to get the data out of source schemas and into the new DW target schema. The big data boom was born, and Hadoop was its poster child.
Summary: Choosing the right ETL tool is crucial for seamless data integration. At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. What is ETL?
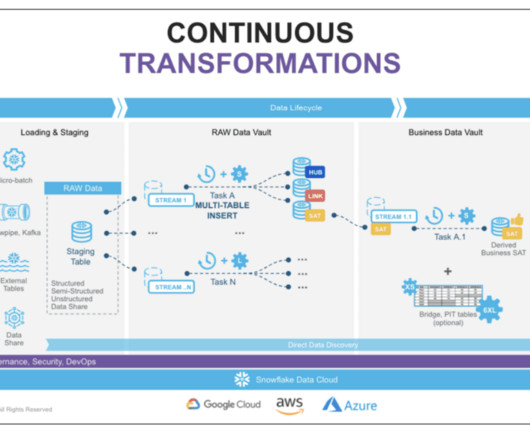
In this blog, we explore best practices and techniques to optimize Snowflake’s performance for data vault modeling , enabling your organizations to achieve efficient data processing, accelerated query performance, and streamlined ETL workflows. This reduces the complexity of the ETL process and improves development efficiency.
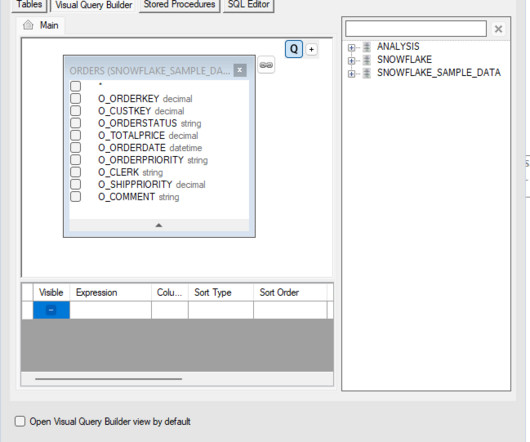
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes. An EMR cluster with EMR runtime roles enabled. Associating runtime roles with EMR clusters is supported in Amazon EMR 6.9. The EMR cluster should be created with encryption in transit.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
It consolidates data from various systems, such as transactional databases, CRM platforms, and external data sources, enabling organizations to perform complex queries and derive insights. Evaluate integration capabilities with existing data sources and Extract Transform and Load (ETL) tools.
When a query is constructed, it passes through a cost-based optimizer, then data is accessed through connectors, cached for performance and analyzed across a series of servers in a cluster. They stood up a file-based data lake alongside their analytical database. Uber has made the Presto query engine connect to real-time databases.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database.
They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs.
As an example, an IT team could easily take the knowledge of database deployment from on-premises and deploy the same solution in the cloud on an always-running virtual machine. Data Processing: Snowflake can process large datasets and perform data transformations, making it suitable for ETL (Extract, Transform, Load) processes.
Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks. Using Parameter Store, we can centralize configuration settings, such as database connection strings, API keys, and environment variables, eliminating the need for hardcoding sensitive information within container images.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. ETL ARCHITECTURE DIAGRAM ETL stands for Extract, Transform, Load. ETL ensures data quality and enables analysis and reporting.
Learning about the framework of a service cloud platform is time consuming and frustrating because there is a lot of new information from many different computing fields (computer science/database, software engineering/developers, data science/scientific engineering & computing/research).
While both handle vast datasets across clusters, they differ in approach. It distributes large datasets across multiple nodes in a cluster , ensuring data availability and fault tolerance. Data is processed in parallel across the cluster in the map phase, while in the Reduce phase, the results are aggregated.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. databases), semi-structured (e.g., Data can be structured (e.g.,
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a data lake: a large and complex database of diverse datasets all stored in their original format.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Their primary responsibilities include: Data Collection and Preparation Data Scientists start by gathering relevant data from various sources, including databases, APIs, and online platforms. ETL Tools: Apache NiFi, Talend, etc.
Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods. While sensor data is typically numerical and has a well-defined format, such as timestamps and data points, it only fits the standard tabular structure of databases.
It acts as a catalogue, providing information about the structure and location of the data. · Hive Query Processor It translates the HiveQL queries into a series of MapReduce jobs. · Hive Execution Engine It executes the generated query plans on the Hadoop cluster. It manages the execution of tasks across different environments.
Scalability : NiFi can be deployed in a clustered environment, enabling organizations to scale their data processing capabilities as their data needs grow. Its visual interface allows users to design complex ETL workflows with ease. Apache NiFi is used for automating the flow of data between systems.
By having all their data in a single, globally available, governed platform, AMCs can build a strategic security master database and also support their workflows efficiently. Data movements lead to high costs of ETL and rising data management TCO.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
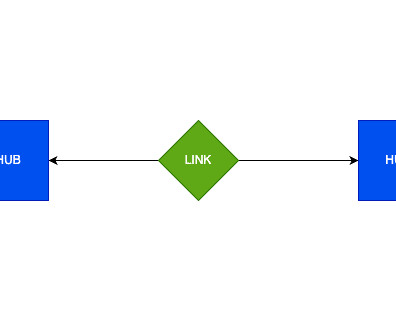
To set up this approach, a multi-cluster warehouse is recommended for stage loads, and separate multi-cluster warehouses can be used to run all loads in parallel. The multi-cluster virtual warehouse option automatically scales out and load balances all tasks as hubs, links, and satellites are introduced.
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka. p8 -pubout -out C:tmpnew_rsa_key_v1.pub
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). Understanding the differences between SQL and NoSQL databases is crucial for students.
Setting up the Information Architecture Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture.
Extraction, transformation and loading (ETL) tools dominated the data integration scene at the time, used primarily for data warehousing and business intelligence. Critical and quick bridges The demand for lineage extends far beyond dedicated systems such as the ETL example. It is rare for a site to have just one dedicated toolset.
You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines. To understand this, imagine you have a pipeline that extracts weather information from an API, cleans the weather information, and loads it into a database.
Relational database connectors are available. Talend Overview While Talend’s Open Studio for Data Integration is free-to-download software to start a basic data integration or an ETL project, it also comes powered with more advanced features which come with a price tag. Server update locks the entire cluster. Talend Free to use.
Techniques like binning, regression, and clustering are employed to smooth and filter the data, reducing noise and improving the overall quality of the dataset. It is known for its ability to connect to almost any database and offers features like reusable data flows, automating repetitive work.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
The notifications Lambda will get the information related to the prediction ID from DynamoDB, update the entry with status value to “completed” or “error,” and perform the necessary action depending on the callback mode saved in the database record. About the Authors Christopher Diaz is a Lead R&D Engineer at CCC Intelligent Solutions.
SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. The SELECT statement retrieves data from a database, while SELECT DISTINCT eliminates duplicate rows from the result set. Data Warehousing and ETL Processes What is a data warehouse, and why is it important?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content