This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
This article delves into the essential components of data mining, highlighting its processes, techniques, tools, and applications. What is data mining? Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges.
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
These methods analyze data without pre-labeled outcomes, focusing on discovering patterns and relationships. They often play a crucial role in clustering and segmenting data, helping businesses identify trends without prior knowledge of the outcome. Well-prepareddata is essential for developing robust predictive models.
Data mining has emerged as a vital tool in todays data-driven environment, enabling organizations to extract valuable insights from vast amounts of information. As businesses generate and collect more data than ever before, understanding how to uncover patterns and trends becomes essential for making informed decisions.
Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificial intelligence. Machine learning algorithms are specialized computational models designed to analyze data, recognize patterns, and make informed predictions or decisions.
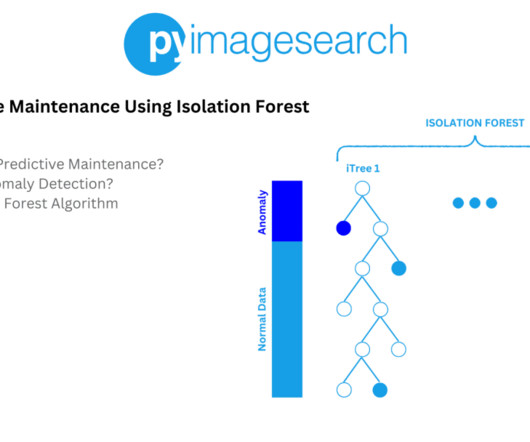
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? By leveraging anomaly detection, we can uncover hidden irregularities in transaction data that may indicate fraudulent behavior.
From marketing strategies that target specific demographics to sales optimizations that increase revenue, data science plays a crucial role in giving companies a competitive edge. Business applications Organizations leverage data science to improve various aspects of their operations.
You need data engineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. These features can find temporal patterns in the data that can influence the baseFare.
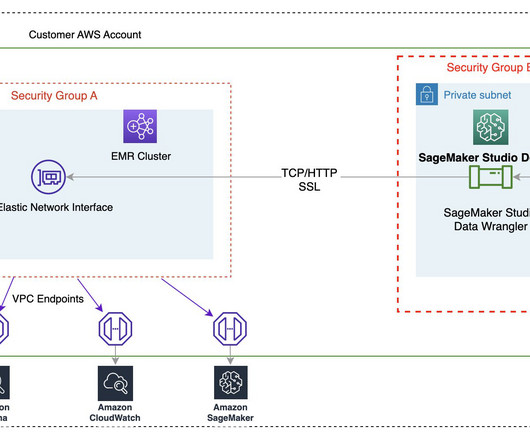
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
Data scientists and data engineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. This blog post will go through how data professionals may use SageMaker Data Wrangler’s visual interface to locate and connect to existing Amazon EMR clusters with Hive endpoints.
Supervised learning and unsupervised learning differ in how they process data and extract insights. One relies on structured, labeled information to make predictions, while the other uncovers hidden patterns in raw data. In this case, every data point has both input and output values already defined.
Throughout the field of data analytics, sampling techniques play a crucial role in ensuring accurate and reliable results. By selecting a subset of data from a larger population, analysts can draw meaningful insights and make informed decisions. Analyze the obtained sample data. Analyze the obtained sample data.
They classify, regress, or clusterdata based on learned patterns but do not create new data. In contrast, generative AI can handle unstructured data and produce new, original content, offering a more dynamic and creative approach to problem-solving. How is Generative AI Different from Traditional AI Models?
The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. Datapreparation is essential for model training and is also the first phase in the MLOps lifecycle. Next, you can use governance to share information about the environmental impact of your model.
Hadoop systems and data lakes are frequently mentioned together. Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture. This implies that data that may never be needed is not wasting storage space.
The amount of data that businesses collect is growing exponentially, and the types of data that businesses collect are becoming more diverse. This growing complexity of business data is making it more difficult for businesses to make informed decisions.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. For more information on the dataset used in this post, see DocVQA – Datasets.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
Datapreparation For this example, you will use the South German Credit dataset open source dataset. The following code demonstrates how to track your experiments when executing your code on a SageMaker ephemeral cluster using the @remote decorator. In both cases, you can track your experiments using MLflow.
This helps with datapreparation and feature engineering tasks and model training and deployment automation. The following application is a ML approach using unsupervised learning to automatically identify use cases in each opportunity based on various text information, such as name, description, details, and product service group.
By analyzing the sentiment of users towards certain products, services, or topics, sentiment analysis provides valuable insights that empower businesses and organizations to make informed decisions, gauge public opinion, and improve customer experiences. Noise in data can arise due to data collection errors, system glitches, or human errors.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Searching through this diverse content to find useful information is a significant challenge. You must bring a laptop to participate.
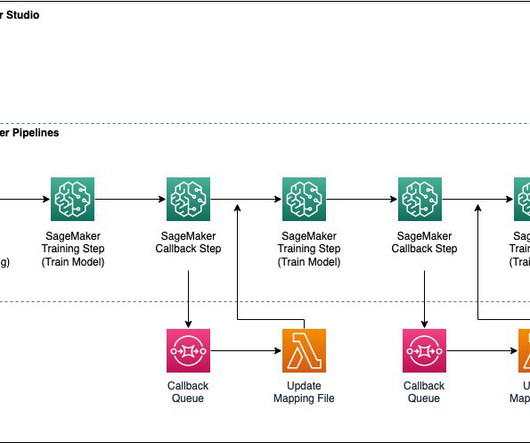
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. Ray AI Runtime (AIR) reduces friction of going from development to production.
It’s challenging to predict which jobs are pertinent to a job seeker based on the limited amount of information provided, usually contained to a few keywords and a location. Job pertinence is measured by the click probability (the probability of a job seeker clicking on a job for more information).
Competition at the leading edge of LLMs is certainly heating up, and it is only getting easier to train LLMs now that large H100 clusters are available at many companies, open datasets are released, and many techniques, best practices, and frameworks have been discovered and released.
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. Finally, launching clusters can introduce operational overhead due to longer starting time.
Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. In the processing job API, provide this path to the parameter of submit_jars to the node of the Spark cluster that the processing job creates. We attached the IAM role to the Redshift cluster that we created earlier.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering.
For more information about fine tuning Sentence Transformer, see Sentence Transformer training overview. Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring.
Data mining is often used in conjunction with other data analytics techniques, such as machine learning and predictive analytics, to build models that can be used to make predictions and inform decision-making. Data mining can be applied to many data types, including customer, financial, medical, and scientific data.
Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. This typically involves a lot of manual work cleaning data, removing duplicates, enriching and transforming it. Then you point to a few labeled examples (e.g.,
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. This method helps in identifying fraudulent transactions by grouping similar data points and detecting outliers. detection of potential failures or issues).
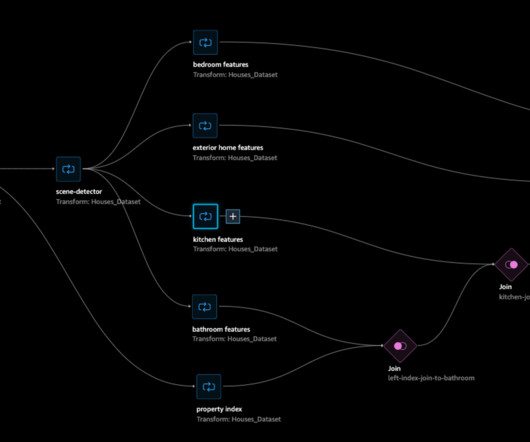
A significant influence was made by Harrison and Rubinfeld (1978), who published a groundbreaking paper and dataset that became known informally as the Boston housing dataset. A modern approach to a classic use case Home price estimation has traditionally occurred through tabular data where features of the property are used to inform price.
Computer Vision This is a field of computer science that deals with the extraction of information from images and videos. DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes.
Data contains information, and information can be used to predict future behaviors, from the buying habits of customers to securities returns. The financial services industry (FSI) is no exception to this, and is a well-established producer and consumer of data and analytics.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. For more information, see Zeta Global’s home page. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. Data is split into a training dataset and a testing dataset. Details of the datapreparation code are in the following notebook.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
Here are the steps involved in predictive analytics: Collect Data : Gather information from various sources like customer behavior, sales, or market trends. Clean and Organise Data : Prepare the data by removing errors and making it ready for analysis.
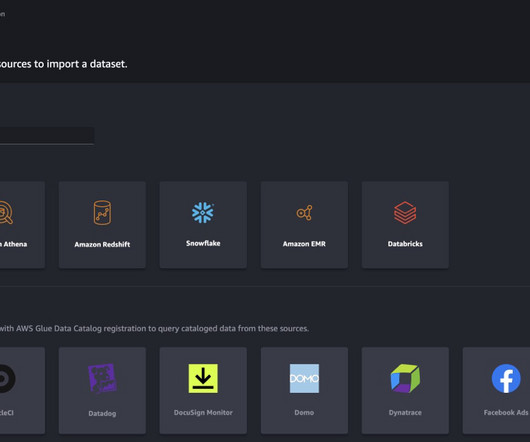
This addition enhances data accessibility and management within your development environment. or lower) or in a custom environment, refer to appendix for more information. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas.
It encompasses various models and techniques, applicable across industries like finance and healthcare, to drive informed decision-making. Introduction Statistical Modeling is crucial for analysing data, identifying patterns, and making informed decisions. Datapreparation also involves feature engineering.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content