This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning algorithms for unstructured data include: K-means: This algorithm is a data visualization technique that processes data points through a mathematical equation with the intention of clustering similar data points.
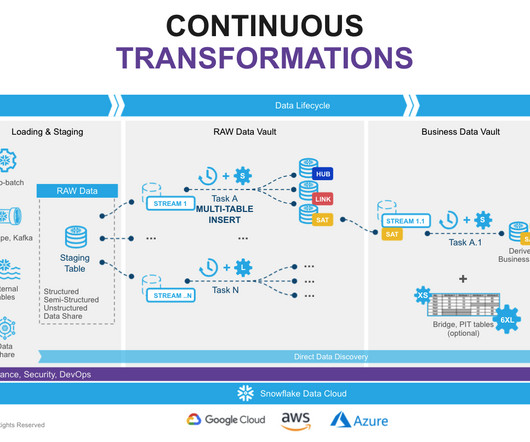
The implementation of a data vault architecture requires the integration of multiple technologies to effectively support the design principles and meet the organization’s requirements. Having model-level data validations along with implementing a dataobservability framework helps to address the data vault’s data quality challenges.
The degree of positive results is generally clustered in companies with under 500 employees and companies with 1,000- 5,000 employees. Forty percent say they are taking steps involving people, including improving data literacy skills and addressing staffing and resources.
Read More: Advanced SQL Tips and Tricks for Data Analysts. Hadoop Hadoop is an open-source framework designed for processing and storing big data across clusters of computer servers. It serves as the foundation for big data operations, enabling the storage and processing of large datasets.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
There is systematic process to analyze and respond to issues beyond deployment decision making; use Observational study to track potential model performance overtime, such as concept drift (declining accuracy of decision making and/or predictive power).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content