This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It supports various data types and offers advanced features like data sharing and multi-cluster warehouses.
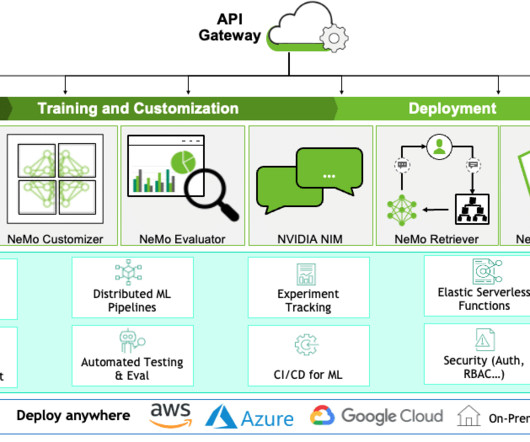
Then, taking an application to production requires much more time and effort: For data management, security and governance: Automating, scaling, versioning and productizing datapipelines. Ensuring data security, lineage and risk controls. Adding application security (authentication, RBAC, auditing).
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. This ensures that the data is accurate, consistent, and reliable.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
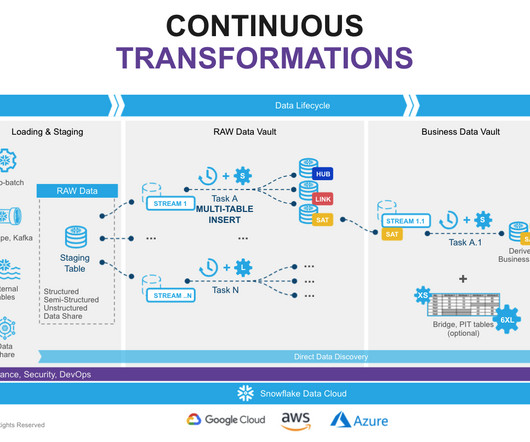
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
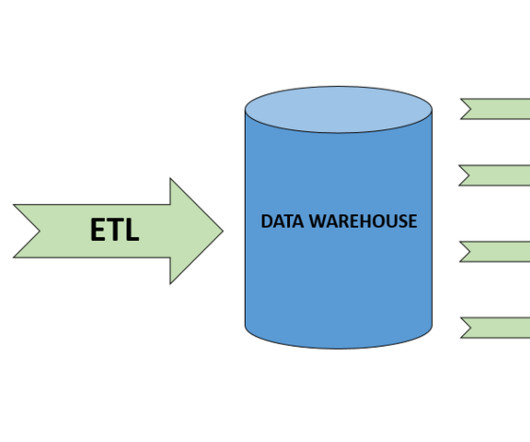
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. BigQuery supports various data ingestion methods, including batch loading and streaming inserts, while automatically optimizing query execution plans through partitioning and clustering.
IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Key Features: Graphical Framework: Allows users to design datapipelines with ease using a graphical user interface. Read More: Advanced SQL Tips and Tricks for Data Analysts.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. With the help of Snowflake clusters, organizations can effectively deal with both rush times and slowdowns since they ensure scalability upon demand.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Team composition The team comprises datapipeline engineers, ML engineers, full-stack engineers, and data scientists. Organization Acquia Industry Software-as-a-service Team size Acquia built an ML team five years ago in 2017 and has a team size of 6.
How can we build up toward our vision in terms of solvable data problems and specific data products? data sources or simpler datamodels) of the data products we want to build? What are we working towards? What are the dependencies (e.g. How can we resolve those dependencies step-by-step?
Scikit-learn provides a consistent API for training and using machine learning models, making it easy to experiment with different algorithms and techniques. It also provides tools for model evaluation , including cross-validation, hyperparameter tuning, and metrics such as accuracy, precision, recall, and F1-score.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a data engineering team as one of the first engineers. We were focused on building datapipelines and models to protect our users from malicious phonecalls. Passionate about working with Go, Zig codebases.
But if your issue is suffered by many but you don't all cluster together in latitude and longitude then that issue has less weight. Designing AI datapipelines to process billions of data points. I wonder if we can move away from representation purely on where you live. Where you live means something.
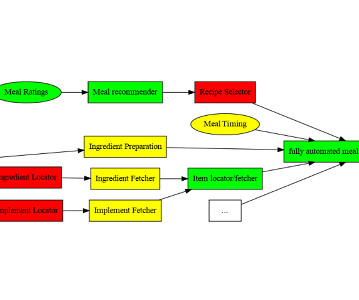
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content