This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datamining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging datamining to gain a competitive edge, improve decision-making, and optimize operations.
Datamining has emerged as a vital tool in todays data-driven environment, enabling organizations to extract valuable insights from vast amounts of information. As businesses generate and collect more data than ever before, understanding how to uncover patterns and trends becomes essential for making informed decisions.
Datamining has become increasingly crucial in today’s digital age, as the amount of data generated continues to skyrocket. In fact, it’s estimated that by 2025, the world will generate 463 exabytes of data every day, which is equivalent to 212,765,957 DVDs per day!
What is K Means Clustering K-Means is an unsupervised machine learning approach that divides the unlabeled dataset into various clusters. In this scenario, the machine’s task is to arrange unsorted data based on parallels, patterns, and variances without any prior data training.
Summary: Clustering in datamining encounters several challenges that can hinder effective analysis. Key issues include determining the optimal number of clusters, managing high-dimensional data, and addressing sensitivity to noise and outliers. What is Clustering?
This data alone does not make any sense unless it’s identified to be related in some pattern. Datamining is the process of discovering these patterns among the data and is therefore also known as Knowledge Discovery from Data (KDD). Machine learning provides the technical basis for datamining.
Instead, we let the system discover information and outline the hidden structure that is invisible to our eye. As a result, unsupervised ML algorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes. Overall, unsupervised algorithms get to the point of unspecified data bits.
This distribution demonstrates how data points tend to cluster around a central mean, with equal probabilities existing for values above and below that mean. Related concepts in statistics Normal distribution interrelates with various fundamental concepts in statistics and data science.
Data science tools are integral for navigating the intricate landscape of data analysis, enabling professionals to transform raw information into valuable insights. As the demand for data-driven decision-making grows, understanding the diverse array of tools available in the field of data science is essential.
Meta Description: Discover the key functionalities of datamining, including data cleaning, integration. Summary: Datamining functionalities encompass a wide range of processes, from data cleaning and integration to advanced techniques like classification and clustering.
Each of the following datamining techniques cater to a different business problem and provides a different insight. Knowing the type of business problem that you’re trying to solve will determine the type of datamining technique that will yield the best results. Often, they provide critical and actionable information.
Accordingly, data collection from numerous sources is essential before data analysis and interpretation. DataMining is typically necessary for analysing large volumes of data by sorting the datasets appropriately. What is DataMining and how is it related to Data Science ? What is DataMining?
The purpose of data archiving is to ensure that important information is not lost or corrupted over time and to reduce the cost and complexity of managing large amounts of data on primary storage systems. This information helps organizations understand what data they have, where it’s located, and how it can be used.
Understanding big data analytics Structured data – RDBMS handling the data deluge The growing volume of data becomes overwhelming for organizations, leaving them grappling with its sheer magnitude. Relational databases emerge as the solution, bringing order to the data deluge.
Data management software helps in reducing the cost of maintaining the data by helping in the management and maintenance of the data stored in the database. It also helps in providing visibility to data and thus enables the users to make informed decisions. They vary in terms of their complexity and application.
Data science applications Data science contributes to personalization engines by providing the methods needed to parse large datasets, extract valuable insights, and inform personalized strategies. DataMining: Methods that extract patterns from large datasets to inform personalization strategies.
Established in 1996, HIPAA ensures that the confidential information of patients remains private. This is more important during the era of big data, since patient information is more vulnerable in a digital format. Big data has created a new range of tools meant to make online privacy more feasible.
This collection of open-source utilities are primarily designed to help solve issues related to distributed storage, which is normally associated with crunching large numbers and tracking information that comes in from multiple sources. Some groups are turning to Hadoop-based datamining gear as a result.
One new feature is the ability to create a radius, which wouldn’t be possible without the highly refined datamining and analytics features embedded in the core of the Google Maps algorithm. The Emerging Role of Big Data with Google Analytics. Creating a radius for custom maps.
It works for videos of any length and provides well-organized summaries that extract key concepts, highlights, keywords, channel information, and other relevant data from videos and shorts. Master clustering with this guide covering foundation and practical use. Discover the ideal algorithm for your data needs.
Natural Language Processing (NLP): Data scientists are incorporating NLP techniques and technologies to analyze and derive insights from unstructured data such as text, audio, and video. This enables them to extract valuable information from diverse sources and enhance the depth of their analysis. H2O.ai: – H2O.ai
Furthermore, it has been estimated that by 2025, the cumulative data generated will triple to reach nearly 175 zettabytes. Demands from business decision makers for real-time data access is also seeing an unprecedented rise at present, in order to facilitate well-informed, educated business decisions.
Advanced analytics has transformed the way organizations approach decision-making, unlocking deeper insights from their data. By integrating predictive modeling, machine learning, and datamining techniques, businesses can now uncover trends and patterns that were previously hidden.
Afterwards, we will provide some additional information on creating a more data-driven SEO strategy, particularly around the theme of earning backlinks. Search engines use datamining tools to find links from other sites. It’s a bad idea to link from the same domain, or the same cluster of domains repeatedly.
Online transaction processing (OLTP) is a data processing technique that involves the concurrent execution of multiple transactions, such as online banking, shopping, order entry, or text messaging. Initially, the OLTP concept was restricted to in-person exchanges that involved the transfer of goods, money, services, or information.
This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code. In the realm of data science, seasoned professionals often carry out research to comprehend how similar issues have been tackled in the past.
Significantly, the technique allows the model to work independently by discovering its patterns and previously undetected information. Therefore, it mainly deals with unlabelled data. The ability of unsupervised learning to discover similarities and differences in data makes it ideal for conducting exploratory data analysis.
Common databases appear unable to cope with the immense increase in data volumes. Managing and analyzing these huge arrays of information in due time becomes a real challenge for marketers. This is where the BigQuery data warehouse comes into play. The BigQuery tool was designed to be the centerpiece of data analysis.
New users may find establishing a user profile vector difficult due to limited information about their interests. Like content-based recommendations, collaborative systems have their limitations: Identifying the -closest users for new users is difficult because of the limited information about their interests.
In this era of information overload, utilizing the power of data and technology has become paramount to drive effective decision-making. Decision intelligence is an innovative approach that blends the realms of data analysis, artificial intelligence, and human judgment to empower businesses with actionable insights.
Introduction In the age of big data, where information flows like a relentless river, the ability to extract meaningful insights is paramount. Association rule mining (ARM) emerges as a powerful tool in this data-driven landscape, uncovering hidden patterns and relationships between seemingly disparate pieces of information.
Evolutionary computing algorithms can analyze lots of medical information, spot patterns, and optimize diagnostic methods to help doctors make accurate and fast diagnoses. Evolutionary computing has been successfully applied to various problem domains, including optimization, machine learning, scheduling, datamining, and many others.
Use cases for Matplotlib include creating line plots, histograms, scatter plots, and bar charts to represent data insights visually. Seaborn Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics. It offers simple and efficient tools for datamining and Data Analysis.
Introduction Data Analysis transforms raw data into valuable insights that drive informed decisions. It systematically examines data to uncover patterns, trends, and relationships that help organisations solve problems and make strategic choices. Data Analysis plays a crucial role in filtering and structuring this data.
The surge of digitization and its growing penetration across the industry spectrum has increased the relevance of text mining in Data Science. Text mining is primarily a technique in the field of Data Science that encompasses the extraction of meaningful insights and information from unstructured textual data.
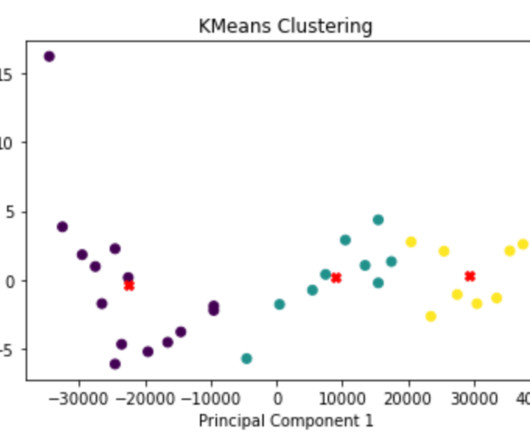
A Complete Guide about K-Means, K-Means ++, K-Medoids & PAM’s in K-Means Clustering. A Complete Guide about K-Means, K-Means ++, K-Medoids & PAM’s in K-Means Clustering. To address such tasks and uncover behavioral patterns, we turn to a powerful technique in Machine Learning called Clustering. K = 3 ; 3 Clusters.
For Data Analysts needing help, there are numerous resources available, including Stack Overflow, mailing lists, and user-contributed code. The more popular Python becomes, the more users contribute information on their user experience, creating a self-perpetuating spiral of acceptance and support.
Mastering programming, statistics, Machine Learning, and communication is vital for Data Scientists. A typical Data Science syllabus covers mathematics, programming, Machine Learning, datamining, big data technologies, and visualisation. This skill allows the creation of predictive models and insights from data.
Controlling information is their weapon. Protecting freedom for information spread keeps all other freedoms protected (and defendable). It is akin to us trying to go "off-grid" digitally as to not be tracked or have our datamined and shared. Open source for freedom. Blockchain for publishing freedom.
Customer Segmentation using K-Means Clustering One of the most crucial uses of data science is customer segmentation. You will need to use the K-clustering method for this GitHub datamining project. This renowned unsupervised machine learning approach splits data into K clusters based on similarities.
It relies on tools like datamining , machine learning , and statistics to help businesses make decisions. Here are the steps involved in predictive analytics: Collect Data : Gather information from various sources like customer behavior, sales, or market trends.
By analyzing the sentiment of users towards certain products, services, or topics, sentiment analysis provides valuable insights that empower businesses and organizations to make informed decisions, gauge public opinion, and improve customer experiences. Noise in data can arise due to data collection errors, system glitches, or human errors.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. Introduction In the rapidly evolving field of Data Science, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Pandas: A powerful library for data manipulation and analysis, offering data structures and operations for manipulating numerical tables and time series data. Scikit-learn: A simple and efficient tool for datamining and data analysis, particularly for building and evaluating machine learning models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content