This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
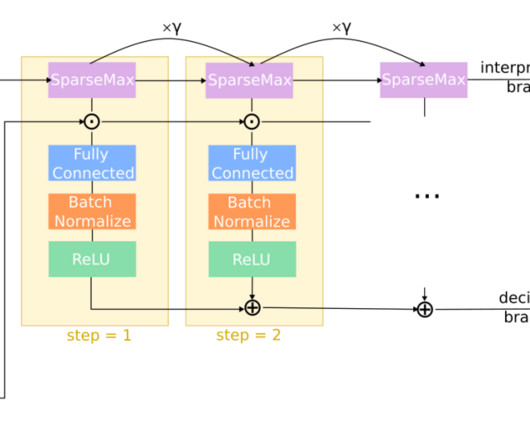
In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance time by half. The major components of RELand are illustrated in Fig.
It’s like having a super-powered tool to sort through information and make better sense of the world. By comprehending these technical aspects, you gain a deeper understanding of how regression algorithms unveil the hidden patterns within your data, enabling you to make informed predictions and solve real-world problems.
This is used for tasks like clustering, dimensionality reduction, and anomaly detection. For example, clustering customers based on their purchase history to identify different customer segments. Feature engineering: Creating informative features can help reduce bias and improve model performance.
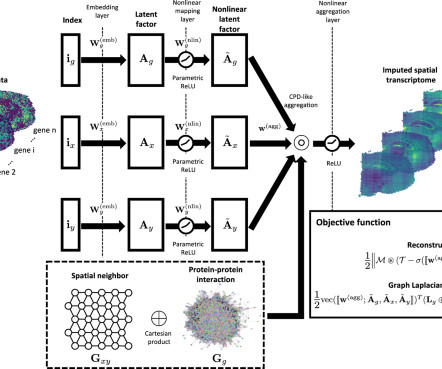
Extensive experiments on 22 Visium spatial transcriptomics datasets and 3 high-resolution Stereo-seq datasets as well as simulation data demonstrate that GNTD consistently improves the imputation accuracy in cross-validations driven by nonlinear tensor decomposition and incorporation of spatial and functional information, and confirm that the imputed (..)
Cross-validation can further be used to verify that the model generalizes well on unseen data. Hence you will have clustering and dimensionality reduction as the main two kinds of unsupervised learning. Hence you will have clustering and dimensionality reduction as the main two kinds of unsupervised learning.
It excels in soft clustering, handling overlapping clusters, and modelling diverse cluster shapes. Its ability to model complex, multimodal data distributions makes it invaluable for clustering , density estimation, and pattern recognition tasks. GMM handles overlapping and non-spherical clusters better than K-Means.
They often play a crucial role in clustering and segmenting data, helping businesses identify trends without prior knowledge of the outcome. It enhances data classification by increasing the complexity of input data, helping organizations make informed decisions based on probabilities.
This region faces dry conditions and high demand for water, and these forecasts are essential for making informed decisions. Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. Lower is better.
The following application is a ML approach using unsupervised learning to automatically identify use cases in each opportunity based on various text information, such as name, description, details, and product service group. The approach uses three sequential BERTopic models to generate the final clustering in a hierarchical method.
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. Embeddings are vector representations of text that capture semantic and contextual information.
These packages are built to handle various aspects of machine learning, including tasks such as classification, regression, clustering, dimensionality reduction, and more. These packages cover a wide array of areas including classification, regression, clustering, dimensionality reduction, and more.
This capability allows businesses to make informed decisions based on data-driven insights, enhancing strategic planning and risk management. As organisations accumulate more data, ML algorithms can scale accordingly, ensuring that decision-making is based on comprehensive and up-to-date information. predicting house prices).
Clustering Metrics Clustering is an unsupervised learning technique where data points are grouped into clusters based on their similarities or proximity. Evaluation metrics include: Silhouette Coefficient - Measures the compactness and separation of clusters.
Statistical modeling in R is enables by Data Scientists to extract meaningful information friom data and test hypotheses, ensuring that decision-making is efficient. This could be linear regression, logistic regression, clustering , time series analysis , etc. This may involve finding values that best represent to observed data.
Computer Vision This is a field of computer science that deals with the extraction of information from images and videos. EDA guides subsequent preprocessing steps and informs the selection of appropriate AI algorithms based on data insights. NLP tasks include machine translation, speech recognition, and sentiment analysis.
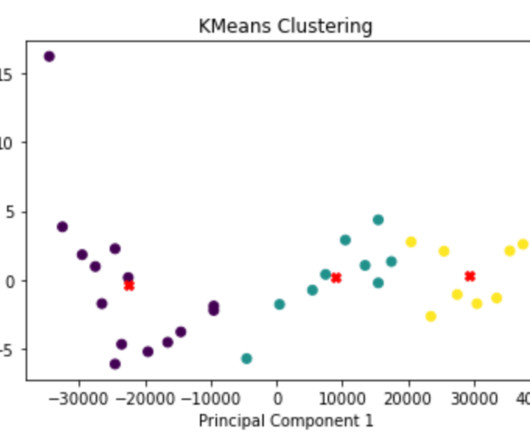
A Complete Guide about K-Means, K-Means ++, K-Medoids & PAM’s in K-Means Clustering. A Complete Guide about K-Means, K-Means ++, K-Medoids & PAM’s in K-Means Clustering. To address such tasks and uncover behavioral patterns, we turn to a powerful technique in Machine Learning called Clustering. K = 3 ; 3 Clusters.
Clustering algorithms such as K-means and hierarchical clustering are examples of unsupervised learning techniques. It involves selecting, extracting, and transforming raw data into informative features that capture the underlying patterns and relationships in the data. How do you handle missing values in a dataset?
These models use the transformer architecture , a type of natural language processing (NLP), to interpret the vast amount of genomic information available, allowing researchers and scientists to extract meaningful insights more accurately than with existing in silico approaches and more cost-effectively than with existing in situ techniques.
For instance, understanding distributions helps select appropriate models and evaluate their likelihood, while hypothesis testing aids in validating assumptions about data. Machine Learning Algorithms and Techniques Machine Learning offers a variety of algorithms and techniques that help models learn from data and make informed decisions.
To make the correct coverage identification, a multitude of information over time must be accounted for, including the way defenders lined up before the snap and the adjustments to offensive player movement once the ball is snapped. Advances in neural information processing systems 30 (2017). Gomez, Łukasz Kaiser, and Illia Polosukhin.
It enables organizations to create powerful, data-driven models that reveal patterns, trends, and insights, leading to more informed decision-making and more effective automation. MLOps practices include cross-validation, training pipeline management, and continuous integration to automatically test and validate model updates.
It encompasses various models and techniques, applicable across industries like finance and healthcare, to drive informed decision-making. Introduction Statistical Modeling is crucial for analysing data, identifying patterns, and making informed decisions. Popular clustering algorithms include k-means and hierarchical clustering.
By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Data Science is the art and science of extracting valuable information from data.
This usually involved gathering market and property information, socio-economic data about a city on a zip code level and information regarding access to amenities (e.g., This would entail a roughly +/-€24,520 price difference on average, compared to the true price, using MAE (Mean Absolute Error) CrossValidation.
Clustering and dimensionality reduction are common tasks in unSupervised Learning. For example, clustering algorithms can group customers by purchasing behaviour, even if the group labels are not predefined. customer segmentation), clustering algorithms like K-means or hierarchical clustering might be appropriate.
Organisations must develop strategies to store and manage this vast amount of information effectively. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
It involves identifying relevant information and reducing complexity, which improves accuracy and efficiency. It involves identifying the most relevant information from a dataset and converting it into a set of features that capture the essential patterns and relationships in the data. What is Feature Extraction?
Data analytics deals with checking the existing hypothesis and information and answering questions for a better and more effective business-related decision-making process. Long format DataWide-Format DataHere, each row of the data represents the one-time information of a subject. What is Cross-Validation?
Mastering Data Analyst Interviews: Top 50+ Q&A Data Analysts are pivotal in deciphering complex datasets to drive informed business decisions. Techniques such as cross-validation, regularisation , and feature selection can prevent overfitting. In my previous role, we had a project with a tight deadline.
Now you might be wondering why you should believe me with all this information. It offers implementations of various machine learning algorithms, including linear and logistic regression , decision trees , random forests , support vector machines , clustering algorithms , and more.
Summary of approach: The approach was inspired by the idea that all speech contains two types of information: 1) what was said, and 2) how it was said. We developed multiple sub-models to try and capture information across both of these types. Cluster 0 was in English and included many people talking to an Alexa.
This step is crucial to ensure that the pipeline has access to relevant and up-to-date information. Techniques such as dimensionality reduction, feature selection, or feature extraction can be employed to identify and create the most informative features for the ML algorithm. Perform cross-validation using StratifiedKFold.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content