This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Sign Up for the CloudData Science Newsletter. Amazon Athena and Aurora add support for ML in SQL Queries You can now invoke Machine Learning models right from your SQL Queries. Comprehend can now be used to classify documents in real-time. Document classification no longer needs to be performed in batch processes.
The data in Amazon Redshift is transactionally consistent and updates are automatically and continuously propagated. Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? IaC allows for swift disaster recovery by codifying the entire infrastructure.
Available Service information One or more regions affected Products Americas (regions) Europe (regions) Asia Pacific (regions) Middle East (regions) Africa (regions) Multi-regions Global Access Approval Access Context Manager Access Transparency Agent Assist AI Platform Prediction AI Platform Training AlloyDB for PostgreSQL Anthos Service Mesh API (..)
This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights. A standout application is the SQL-to-natural language capability, which translates complex SQL queries into plain English and vice versa, bridging the gap between technical and business teams.
Snowflake’s cloud-agnosticism, separation of storage and compute resources, and ability to handle semi-structured data have exemplified Snowflake as the best-in-class clouddata warehousing solution. Snowflake supports data sharing and collaboration across organizations without the need for complex data pipelines.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a clouddata warehouse like Snowflake. Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code.
Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Data management approaches are varied and may be categorised in the following: Clouddata management. Master data management.
The bill presents Charges for serverless features as individual line items, with Snowflake-managed compute resources and Cloud Services charges bundled into a single line item for each serverless feature. We can set the STATEMENT_TIMEOUT_IN_SECONDS parameter to define the maximum time a SQL statement can run before it is canceled.
“ Vector Databases are completely different from your clouddata warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. When documents are split into smaller chunks, search systems can find relevant sections more precisely and quickly.
It comes with a rather lightweight intellisense, and highlights for both SQL and Jinja use. The real power is the ability to run your models and view the outputs, or even have your SQL compiled to verify that your Jinja or SQL compiles into the correct model. Our team of data experts are happy to assist. Reach out today!
Additionally, Tableau allows customers using BigQuery ML to easily visualize the results of predictive machine learning models run on data stored in BigQuery. This minimizes the amount of SQL you need to write to create and execute models, as well as analyze the results—making machine learning techniques easier to use.
Fivetran enables healthcare organizations to ingest data securely and effectively from a variety of sources into their target destinations, such as Snowflake or other clouddata platforms, for further analytics or curation for sharing data with external providers or customers.
Services such as the Snowflake DataCloud can house massive amounts of data and allows users to write queries to rapidly transform raw data into reports and further analyses. For somebody who cannot access their database directly or who lacks expert-level skills in SQL, this provides a significant advantage.
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
Additionally, Tableau allows customers using BigQuery ML to easily visualize the results of predictive machine learning models run on data stored in BigQuery. This minimizes the amount of SQL you need to write to create and execute models, as well as analyze the results—making machine learning techniques easier to use.
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode.
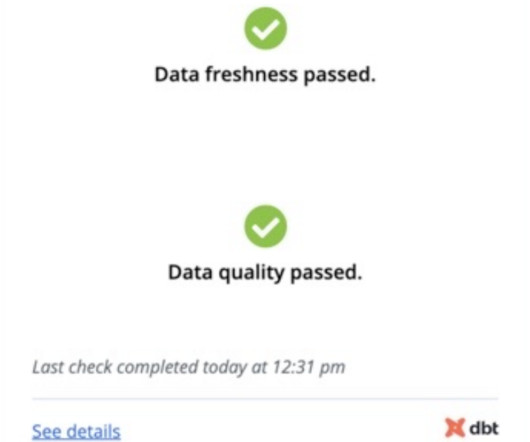
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and documentdata in the clouddata warehouse. This graph is an example of one analysis, documented in our internal catalog.
Cloud-Based Computing While Teradata was once successful at managing and analyzing large data sets, the growing volume, variety, and speed of data now require more advanced data analytics provided by cloud-based solutions. You can find more information about the costs here in their documentation section.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. For greater detail, see the Snowflake documentation.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. Some of the other ways are creating a table 1) using the command line in Google Cloud console, 2) using the APIs, or 3) from Vertex AI Workbench.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The CloudData Migration Challenge. Data pipeline orchestration.
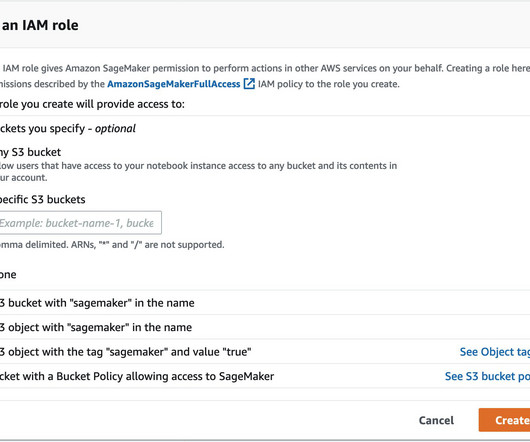
SageMaker Canvas allows interactive data exploration, transformation, and preparation without writing any SQL or Python code. Complete the following steps to prepare your data: On the SageMaker Canvas console, choose Data preparation in the navigation pane. On the Create menu, choose Document. Choose Create.
Data warehousing is a vital constituent of any business intelligence operation. Companies can build Snowflake databases expeditiously and use them for ad-hoc analysis by making SQL queries. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
Organizations need to ensure that data use adheres to policies (both organizational and regulatory). In an ideal world, you’d get compliance guidance before and as you use the data. Imagine writing a SQL query or using a BI dashboard with flags & warnings on compliance best practice within your natural workflow.
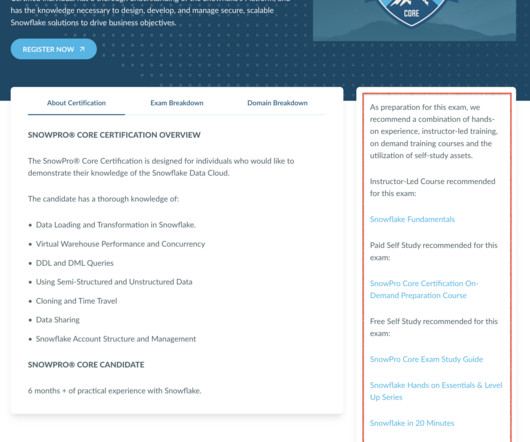
The SnowPro Advanced Administrator Certification targets Snowflake Administrators, Snowflake DataCloud Administrators, Database Administrators, Cloud Infrastructure Administrators, and CloudData Administrators. How Many Days Will It Take to Learn Snowflake?
DataRobot AI Cloud 8.0 DataRobot For the AI-driven Business: Empower Your Business with No-Code Solutions that Deliver Timely, Continuous, and Trusted Insights from more of Your Data. DataRobot AI Cloud 8.0 With DataRobot AI Cloud 8.0, for the AI-driven Business appeared first on DataRobot AI Cloud. Learn More.
Real-time processing is essential for applications requiring immediate data insights. Support : Are there resources available for troubleshooting, such as documentation, forums, or customer support? Security : Does the tool ensure data privacy and security during the ETL process?
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack.
With Fivetran, you can quickly and easily switch between different data warehouse technologies in which to land your data, as well as popular open-source lake formats such as Apache Iceberg. Thanks to SQL-centric transformations, you no longer need to have deep experience in a particular tool or programming language.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
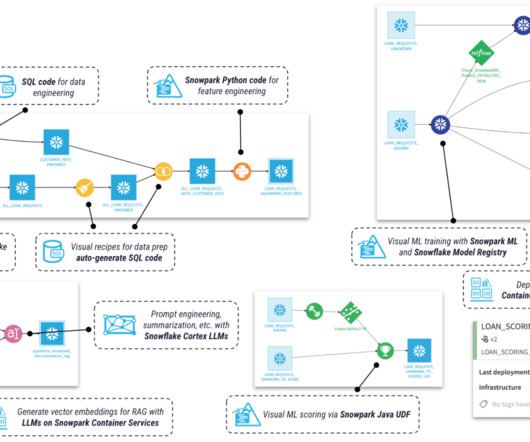
Organizations must ensure their data pipelines are well designed and implemented to achieve this, especially as their engagement with clouddata platforms such as the Snowflake DataCloud grows. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable data pipelines.
ThoughtSpot is a cloud-based AI-powered analytics platform that uses natural language processing (NLP) or natural language query (NLQ) to quickly query results and generate visualizations without the user needing to know any SQL or table relations. Why Use ThoughtSpot?
People are Overwhelmed by Too Much Data, with No Means to Govern It at Scale. Data stewards are challenged by an ever-increasing volume of data. They often lack guidance into how to prioritize curation and datadocumentation efforts. Alation Policy Center empowers data stewards to govern Snowflake data.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse.
Data Collector also offers replication and Change Data Capture (CDC) to be able to accurately and efficiently get your data into Snowflake. Data Collector can use Snowflake’s native Snowpipe in its pipelines. Replication of calculated values is not supported during Change Processing.
Founded in 2014 by three leading cloud engineers, phData focuses on solving real-world data engineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading clouddata platform.
Amazon Redshift is a fully managed, fast, secure, and scalable clouddata warehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a data warehouse such as Amazon Redshift. This should return the records successfully for further data processing and analysis.
dbt Labs is a robust platform that allows individuals comfortable with SQL to incorporate software engineering’s best practices into their data transformation pipelines. These practices encompass aspects such as code versioning, testing, documentation, and modular programming. What is dbt?
Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your clouddata warehouse. However, targeted web advertising may only require linkage to a browser or device ID.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content