
Business Intelligence for Fairs, Congresses and Exhibitions
Smart Data Collective
APRIL 14, 2021
Main features include the ability to access and operationalize data through the LookML library. It also allows you to create your data and creating consistent dataset definitions using LookML. Formerly known as Periscope, Sisense is a business intelligence tool ideal for cloud data teams.
















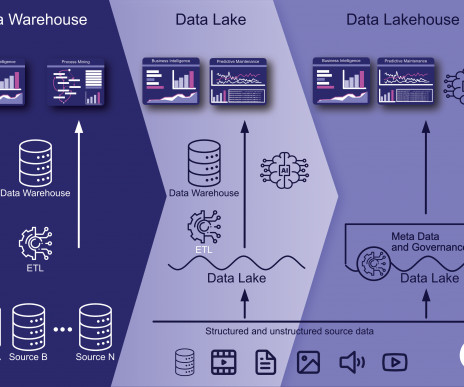








Let's personalize your content