This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It allows datascientists and machine learning engineers to interact with their data and models and to visualize and share their work with others with just a few clicks. SageMaker Canvas has also integrated with Data Wrangler , which helps with creating data flows and preparing and analyzing your data.
Let’s explore each of these components and its application in the sales domain: Synapse Data Engineering: Synapse Data Engineering provides a powerful Spark platform designed for large-scale data transformations through Lakehouse. Here, we changed the data types of columns and dealt with missing values.
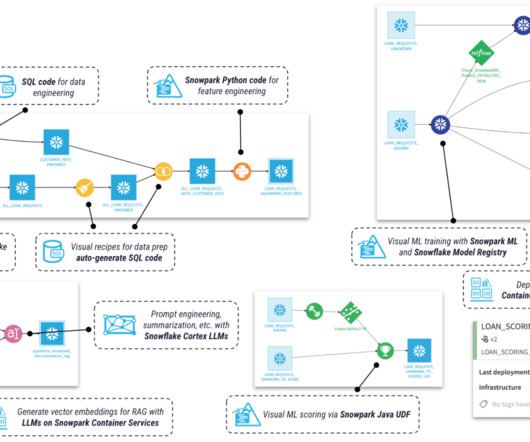
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Moreover, ETL pipelines play a crucial role in breaking down data silos and establishing a single source of truth.
For instance, a Data Science team analysing terabytes of data can instantly provision additional processing power or storage as required, avoiding bottlenecks and delays. The cloud also offers distributed computing capabilities, enabling faster processing of complex algorithms across multiple nodes.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly. A datascientist team orders a new JuMa workspace in BMW’s Catalog.
Snowflake’s cloud-agnosticism, separation of storage and compute resources, and ability to handle semi-structured data have exemplified Snowflake as the best-in-class clouddata warehousing solution. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
When data leaders move to the cloud, it’s easy to get caught up in the features and capabilities of various cloud services without thinking about the day-to-day workflow of datascientists and data engineers. Failing to make production data accessible in the cloud.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Every organization needs data to make many decisions. The data is ever-increasing, and getting the deepest analytics about their business activities requires technical tools, analysts, and datascientists to explore and gain insight from large data sets. Google BigQuery.
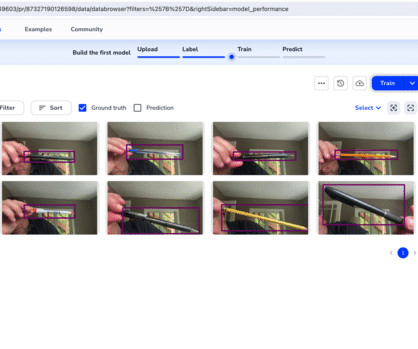
Amazon SageMaker Ground Truth is a fully managed data labeling service that provides flexibility to build and manage custom workflows. With Ground Truth, you can label image, video, and point clouddata for object detection, object tracking, and semantic segmentation tasks.
If you haven’t already, moving to the cloud can be a realistic alternative. Clouddata warehouses provide various advantages, including the ability to be more scalable and elastic than conventional warehouses. Can’t get to the data. Datapipeline maintenance. However, there are ways to get around this.
The audience grew to include datascientists (who were even more scarce and expensive) and their supporting resources (e.g., After that came data governance , privacy, and compliance staff. Power business users and other non-purely-analytic data citizens came after that. Data engineers want to catalog datapipelines.
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
Integrating helpful metadata into user workflows gives all people, from datascientists to analysts , the context they need to use data more effectively. The Benefits and Challenges of the Modern Data Stack Why are such integrations needed? Before a data user leverages any data set, they need to be able to learn about it.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack.
Two decades ago, powerful business intelligence systems relied on on-premise data warehouses, usually fed by overnight batch ETL processes that took multiple hours to complete. To speed analytics, datascientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The CloudData Migration Challenge. Datapipeline orchestration.
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI DataCloud , Fivetran, and Azure to automate invoice processing. Migrations from legacy on-prem systems to clouddata platforms like Snowflake and Redshift. This is where AI truly shines.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
However, creating a computer vision AI requires datascientists to train models for months before they can give results, right? AI can be trained to determine even the most subtle defects in products while being available 24 hours a day, seven days a week.
Simply put, AI-ready data is structured, high-quality information that can be easily used to train machine learning models and run AI applications with minimal engineering effort . Equally important, first-party behavioral data is a source of competitive advantage for brands building AI agents. in a query-ready form.
The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, clouddata ingestion, storage, machine learning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud. Outside of work, Fauzan enjoys spending time in nature.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. And so that’s where we got started as a clouddata warehouse.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. And so that’s where we got started as a clouddata warehouse.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Furthermore, a shared-data approach stems from this efficient combination. What will You Attain with Snowflake?
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse.
Last week, the Alation team had the privilege of joining IT professionals, business leaders, and data analysts and scientists for the Modern Data Stack Conference in San Francisco. In “The modern data stack is dead, long live the modern data stack!” Cloud costs are growing prohibitive. Let’s dive in!
Both persistent staging and data lakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer datapipeline. It’s not just a dumping ground for data, but a crucial step in your customer data processing workflow.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content