This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. And Why did it happen?). or What might be the best course of action?
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? appeared first on Data Science Blog.
In Late January 2019, Microsoft launched 3 new certifications aimed at DataScientists/Engineers. They launched the Microsoft Professional Program in Data Science back in 2017. Here are details about the 3 certification of interest to datascientists and dataengineers.
When data leaders move to the cloud, it’s easy to get caught up in the features and capabilities of various cloud services without thinking about the day-to-day workflow of datascientists and dataengineers. Failing to make production data accessible in the cloud.
It 10x’s our world-class AI platform by dramatically increasing the flexibility of DataRobot for datascientists who love to code and share their expertise across teams of all skill levels. Data Exploration, Visualization, and First-Class Integration. Put simply, Zepl helps make DataRobot easily customizable. Stay tuned.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads. Hear also from Adidas, GlobalFoundries, and University of California, Irvine.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly. JuMa automatically provisions a new AWS account for the workspace.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
This solution offers the following benefits: Seamless integration – SageMaker Canvas empowers you to integrate and use data from various sources, including clouddata warehouses like BigQuery, directly within its no-code ML environment.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Each snapshot has a separate manifest file that keeps track of the data files associated with that snapshot and hence can be restored/queries whenever needed.
However, we are making a few changes, most importantly, ODSC East will feature 2 co-located summits, The DataEngineering Summit , and the Ai X Generative AI Summit. In-person attendees will have access to the Ai X Generative Summit and the DataEngineering Summit.
In the previous blog , we discussed how Alation provides a platform for datascientists and analysts to complete projects and analysis at speed. In this blog we will discuss how Alation helps minimize risk with active data governance. But governance is a time-consuming process (for users and data stewards alike).
The audience grew to include datascientists (who were even more scarce and expensive) and their supporting resources (e.g., After that came data governance , privacy, and compliance staff. Power business users and other non-purely-analytic data citizens came after that. Dataengineers want to catalog data pipelines.
Datascientists run experiments. To work effectively, datascientists need agility in the form of access to enterprise data, streamlined tooling, and infrastructure that just works. We’ve tightened the loop between ML data prep , experimentation and testing all the way through to putting models into production.
Integrating helpful metadata into user workflows gives all people, from datascientists to analysts , the context they need to use data more effectively. The Benefits and Challenges of the Modern Data Stack Why are such integrations needed? Before a data user leverages any data set, they need to be able to learn about it.
Organizations must ensure their data pipelines are well designed and implemented to achieve this, especially as their engagement with clouddata platforms such as the Snowflake DataCloud grows. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable data pipelines.
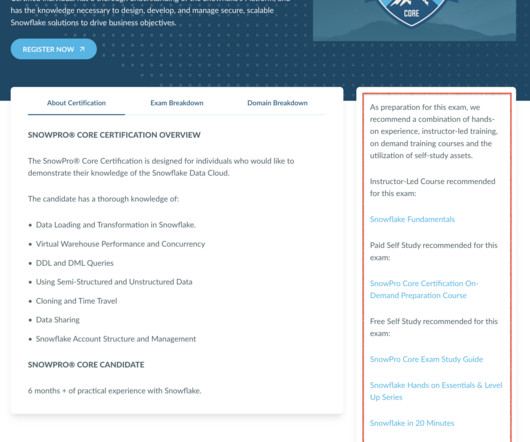
The SnowPro Advanced Administrator Certification targets Snowflake Administrators, Snowflake DataCloud Administrators, Database Administrators, Cloud Infrastructure Administrators, and CloudData Administrators. I found the DataEngineering Simplified’s playlists particularly beneficial during my studies.
Data security posture management is particularly beneficial for organizations that have committed to a cloud-first vision and are moving away from a mixed cloud/on-premises infrastructure. Automatically find and categorize data across all clouds. Avoid exposing clouddata and reduce the attack surface.
Fifth Third faced a number of pain points borne of a large data landscape. The Problem: The Data Challenges. The data challenges at Fifth Third will sound familiar to anyone working in an enterprise data landscape. To meet that growing demand, they decided to make everyone a data citizen.
Data analysts and engineers use dbt to transform, test, and document data in the clouddata warehouse. Making this data visible in the data catalog will let data teams share their work, support re-use, and empower everyone to better understand and trust data.
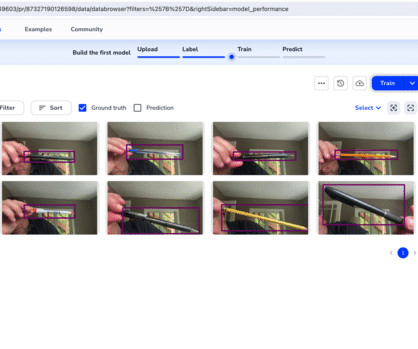
From data collection and cleaning to feature engineering, model building, tuning, and deployment, ML projects often take months for developers to complete. And experienced datascientists can be hard to come by. The following diagram shows the SageMaker Canvas data flow after adding visual transformations.
This week, IDC released its second IDC MarketScape for Data Catalogs report, and we’re excited to share that Alation was recognized as a leader for the second consecutive time. These include data analysts, stewards, business users , and dataengineers. Alation launched Alation Cloud Service (ACS) in April, 2021.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack.
However, creating a computer vision AI requires datascientists to train models for months before they can give results, right? Many dataengineering consulting companies could also answer these questions for you, or maybe you think you have the talent on your team to do it in-house. Why phData?
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
And that’s really key for taking data science experiments into production. And one of the biggest challenges that we see is taking an idea, an experiment, or an ML experiment that datascientists might be running in their notebooks and putting that into production.
And that’s really key for taking data science experiments into production. And one of the biggest challenges that we see is taking an idea, an experiment, or an ML experiment that datascientists might be running in their notebooks and putting that into production.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the clouddata warehouse. Jason: I’m curious to learn about your modern data stack.
With more data than ever before, the ability to find the right data has become harder than ever. Yet businesses need to find data to make data-driven decisions. However, dataengineers, datascientists, data stewards, and chief data officers face the challenge of finding data easily.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. This allows datascientists to keep their focus on the creation of models or their continuous improvement.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
People come to the data catalog to find trusted data, understand it, and use it wisely. Today a modern catalog hosts a wide range of users (like business leaders, datascientists and engineers) and supports an even wider set of use cases (like data governance , self-service , and cloud migration ).
Furthermore, a shared-data approach stems from this efficient combination. The background for the Snowflake architecture is metadata management, so customers can enjoy an additional opportunity to share clouddata among users or accounts. Simplify and Win Experienced dataengineers value simplicity.
ThoughtSpot is a cloud-based AI-powered analytics platform that uses natural language processing (NLP) or natural language query (NLQ) to quickly query results and generate visualizations without the user needing to know any SQL or table relations. Suppose your business requires more robust capabilities across your technology stack.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse.
Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: Data Storage and Processing : This is your foundation. You might choose a clouddata warehouse like the Snowflake AI DataCloud or BigQuery. Building a composable CDP requires some serious dataengineering chops.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content