This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
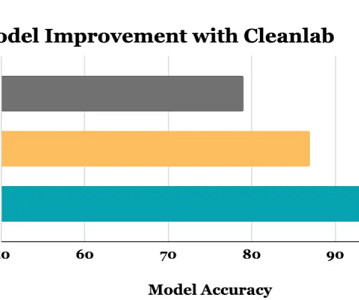
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Everybody knows you need to clean your data to get good ML performance. How does cleanlab work?
Welcome to another exciting tutorial on building your machine learning skills! Today, we’re diving into something super practical that will help you gather data for your ML projects – how to download video from YouTube easily and efficiently! What is Y2Mate? Want audio-only for your speech recognition system?
ML teams have a very important core purpose in their organizations - delivering high-quality, reliable models, fast. With users’ productivity in mind, at DagHub we aimed for a solution that will provide ML teams with the whole process out of the box and with no extra effort.
As AI adoption continues to accelerate, developing efficient mechanisms for digesting and learning from unstructured data becomes even more critical in the future. This could involve better preprocessing tools, semi-supervisedlearning techniques, and advances in natural language processing. read HTML).
The quality of your training data in Machine Learning (ML) can make or break your entire project. Iterative Training : Models should be retrained and fine-tuned with new data to keep up with evolving scenarios, especially in fields like healthcare, finance, and autonomous driving.
Established in 1987 at the University of California, Irvine, it has become a global go-to resource for ML practitioners and researchers. The global Machine Learning market continues to expand. What is the UCI Machine Learning Repository? It provides diverse datasets for research, education, and real-world applications.
A Large Language Model (LLM) is a language model consisting of a neural network with many parameters (typically billions of weights or more), trained on large quantities of unlabeled text using self-supervisedlearning or semi-supervised learning.LLM works on the Transformer Architecture.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content