

Evaluation of generative AI techniques for clinical report summarization
AWS Machine Learning Blog
MAY 13, 2024
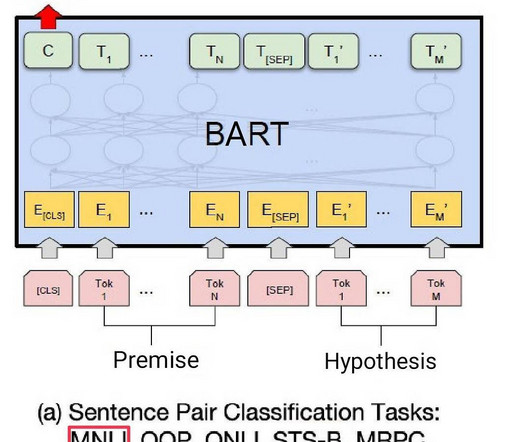
We benchmark the results with a metric used for evaluating summarization tasks in the field of natural language processing (NLP) called Recall-Oriented Understudy for Gisting Evaluation (ROUGE). Evaluating LLMs is an undervalued part of the machine learning (ML) pipeline. It is time-consuming but, at the same time, critical.






Let's personalize your content