This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
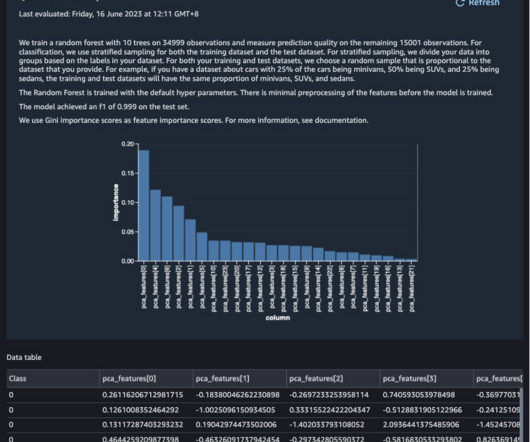
High-qualitydata is paramount for extracting knowledge and gaining insights. By improving dataquality, preprocessing facilitates better decision-making and enhances the effectiveness of data mining techniques, ultimately leading to more valuable outcomes. customer ID vs. customer number).
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
This market is growing as more businesses discover the benefits of investing in big data to grow their businesses. One of the biggest issues pertains to dataquality. Even the most sophisticated big data tools can’t make up for this problem. Data cleansing and its purpose.
On successful authentication, you will be redirected to the data flow page. Browse to locate loan dataset from the Snowflake database Select the two loans datasets by dragging and dropping them from the left side of the screen to the right. The high priority warning has disappeared, indicating improved dataquality.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Data transformation. This process helps to transform raw data into cleandata that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for data scientists to select and cleandata, create features, and automate data preparation in ML workflows without writing any code.
The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data. The objective is to enhance the dataquality and prepare the data sets for the analysis. What is Data Manipulation?
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. Files: Data stored in flat files, CSVs, or Excel sheets.
Summary: This comprehensive guide explores data standardization, covering its key concepts, benefits, challenges, best practices, real-world applications, and future trends. By understanding the importance of consistent data formats, organizations can improve dataquality, enable collaborative research, and make more informed decisions.
We also reached some incredible milestones with Tableau Prep, our easy-to-use, visual, self-service data prep product. In 2020, we added the ability to write to external databases so you can use cleandata anywhere. Tableau Prep can now be used across more use cases and directly in the browser.
By employing ETL, businesses ensure that their data is reliable, accurate, and ready for analysis. This process is essential in environments where data originates from various systems, such as databases , applications, and web services. The key is to ensure that all relevant data is captured for further processing.
Organisations leverage diverse methods to gather data, including: Direct Data Capture: Real-time collection from sensors, devices, or web services. Database Extraction: Retrieval from structured databases using query languages like SQL. Aggregation: Summarising data into meaningful metrics or aggregates.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and cleandata from multiple sources, ensuring it is suitable for analysis. Sources of DataData can come from multiple sources.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
Data scrubbing is often used interchangeably but there’s a subtle difference. Cleaning is broader, improving dataquality. This is a more intensive technique within datacleaning, focusing on identifying and correcting errors. Data scrubbing is a powerful tool within this cleaning service.
Data scientists must decide on appropriate strategies to handle missing values, such as imputation with mean or median values or removing instances with missing data. The choice of approach depends on the impact of missing data on the overall dataset and the specific analysis or model being used.
So, let me present to you an Importing Data in Python Cheat Sheet which will make your life easier. For initiating any data science project, first, you need to analyze the data. In this Importing Data in Python Cheat Sheet article, we will explore the essential techniques and libraries that will make data import a breeze.
There are 5 stages in unstructured data management: Data collection Data integration DatacleaningData annotation and labeling Data preprocessing Data Collection The first stage in the unstructured data management workflow is data collection. We get your data RAG-ready.
We also reached some incredible milestones with Tableau Prep, our easy-to-use, visual, self-service data prep product. In 2020, we added the ability to write to external databases so you can use cleandata anywhere. Tableau Prep can now be used across more use cases and directly in the browser.
With the help of data pre-processing in Machine Learning, businesses are able to improve operational efficiency. Following are the reasons that can state that Data pre-processing is important in machine learning: DataQuality: Data pre-processing helps in improving the quality of data by handling the missing values, noisy data and outliers.
This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., databases, APIs, CSV files). Ensuring Time Consistency: Ensure that the data is organized chronologically, as time order is crucial for time series analysis. Making Data Stationary: Many forecasting models assume stationarity.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
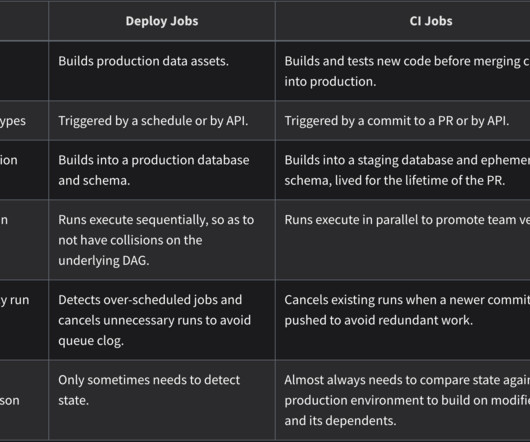
Sidebar Navigation: Provides a catalog sidebar for browsing resources by type, package, file tree, or database schema, reflecting the structure of both dbt projects and the data platform. Deploy jobs are designed to build into production databases, running sequentially to prevent conflicts.
Pandas are widely use for handling missing data and cleaningdata frames, while Scikit-learn provides tools for normalisation and encoding. NumPy and SciPy can also help apply statistical methods for data imputation and feature transformation. Frequently Asked Questions What is the UCI Machine Learning Repository?
It’s about how to draw and analyze dataquality and machine learning quality, which is actually very related to this current trend of data-centric AI. You could have a missing value, you could have a wrong value, and you have a whole bunch of those data examples. We’d like to bring them together.
It’s about how to draw and analyze dataquality and machine learning quality, which is actually very related to this current trend of data-centric AI. You could have a missing value, you could have a wrong value, and you have a whole bunch of those data examples. We’d like to bring them together.
AI Agents and GenAI: Enhancing DataQuality and Compliance Dr. Martin Manhem bu , GovTech Founder & Professor, shared insights on how AI agents can transform data acquisition, management, and governance. Key Points: Data Acquisition: Automated data collection from APIs, IoT devices, and databases.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content