This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineeringBooks for beginners encompass a range of topics, from foundational principles to advanced data processing methods. Lakhs to ₹ 20.0
Welcome to Beyond the Data, a series that investigates the people behind the talent of phData. DataEngineer at phData. DataEngineer? As a Senior DataEngineer, I wear many hats. On the technical side, I clean and organize data, design storage solutions, and build transformation pipelines.
Before a bank can start the process of certifying a risk model, they first need to understand what data is being used and how it changes as it moves from a database to a model.
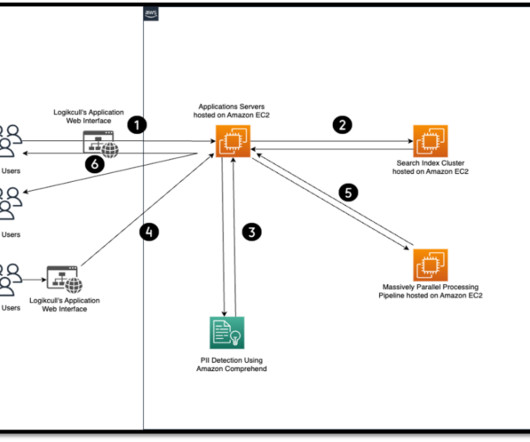
Outside of work, he enjoys playing lawn tennis and reading books. Jeff Newburn is a Senior Software Engineering Manager leading the DataEngineering team at Logikcull – A Reveal Technology. He oversees the company’s data initiatives, including data warehouses, visualizations, analytics, and machine learning.
Find out how to weave data reliability and quality checks into the execution of your datapipelines and more. More Speakers and Sessions Announced for the 2024 DataEngineering Summit Ranging from experimentation platforms to enhanced ETL models and more, here are some more sessions coming to the 2024 DataEngineering Summit.
You have a specific book in mind, but you have no idea where to find it. You enter the title of the book into the computer and the library’s digital inventory system tells you the exact section and aisle where the book is located.
It provides the combination of data lake flexibility and data warehouse performance to help to scale AI. A data lakehouse is a fit-for-purpose data store. A data lakehouse with multiple query engines and storage can allow engineers to share data in open formats.
We didn’t have access to hundreds of dataengineers out in the marketplace,” Lavorini points out. DataPipeline Capabilities This team’s scope is massive because the datapipelines are huge and there are many different capabilities embedded in them. Register (and book a meeting with our team).
If you’d like a more personalized look into the potential of Snowflake for your business, definitely book one of our free Snowflake migration assessment sessions. These casual, informative sessions offer straightforward answers and honest advice for moving your data to Snowflake.
American Family Insurance: Governance by Design – Not as an Afterthought Who: Anil Kumar Kunden , Information Standards, Governance and Quality Specialist at AmFam Group When: Wednesday, June 7, at 2:45 PM Why attend: Learn how to automate and accelerate datapipeline creation and maintenance with data governance, AKA metadata normalization.
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipelineengine for streaming, CDC, and batch ingestion from any source to any destination. The biggest reason is the ease of use.
Dataengineers, data scientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. To read more about LLMOps and MLOps, checkout the O’Reilly book “Implementing MLOps in the Enterprise” , authored by Iguazio ’s CTO and co-founder Yaron Haviv and by Noah Gift.
In this blog, I’ll address some of the questions we did not have time to answer live, pulling from both Dr. Reichental’s book as well as my own experience as a data governance leader for 30+ years. Can you have proper data management without establishing a formal data governance program? Communication is essential.
Activity Schema Modeling: Capturing the Customer Journey in Action Now that we’ve got our Lego blocks of customer data, let’s talk about another game-changing approach that’s shaking up the world of customer data modeling: Activity Schema Modeling. Your customer data game will never be the same.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content