This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data, undoubtedly, is one of the most significant components making up a machine learning (ML) workflow, and due to this, data management is one of the most important factors in sustaining ML pipelines.
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on June 11, 2025 in Language Models Image by Author | Canva If you work in a data-related field, you should update yourself regularly. Data scientists use different tools for tasks like data visualization, datamodeling, and even warehouse systems.
Welcome to the world of databases, where the choice between SQL (Structured Query Language) and NoSQL (Not Only SQL) databases can be a significant decision. In this blog, we’ll explore the defining traits, benefits, use cases, and key factors to consider when choosing between SQL and NoSQL databases.
It offers full BI-Stack Automation, from source to data warehouse through to frontend. It supports a holistic datamodel, allowing for rapid prototyping of various models. It also supports a wide range of data warehouses, analytical databases, data lakes, frontends, and pipelines/ETL. Mixed approach of DV 2.0
This blog delves into a detailed comparison between the two data management techniques. In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. Hence, databases are important for strategic data handling and enhanced operational efficiency.
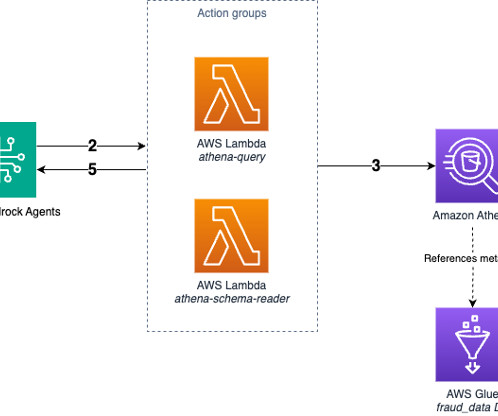
Text-to-SQL empowers people to explore data and draw insights using natural language, without requiring specialized database knowledge. Amazon Web Services (AWS) has helped many customers connect this text-to-SQL capability with their own data, which means more employees can generate insights.
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
So why using IaC for Cloud Data Infrastructures? This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure. Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern.
In this blog post, we will be discussing 7 tips that will help you become a successful data engineer and take your career to the next level. Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases.
Reading Larry Burns’ “DataModel Storytelling” (TechnicsPub.com, 2021) was a really good experience for a guy like me (i.e., someone who thinks that datamodels are narratives). The post Tales of DataModelers appeared first on DATAVERSITY. The post Tales of DataModelers appeared first on DATAVERSITY.
So, I had to cut down my January 2021 list of things of importance in DataModeling in this new, fine year (I hope)! The post 2021: Three Game-Changing DataModeling Perspectives appeared first on DATAVERSITY. Common wisdom has it that we humans can only focus on three things at a time.
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share best practices on developing Text-to-SQL use cases using Meta Llama 3 models. Meta Llama 3’s capabilities enhance accuracy and efficiency in understanding and generating SQL queries from natural language inputs.
Data is an essential component of any business, and it is the role of a data analyst to make sense of it all. Power BI is a powerful data visualization tool that helps them turn raw data into meaningful insights and actionable decisions. Check out this course and learn Power BI today!
Tabular data is the data in the typical table — some columns and rows are structured well, like in Excel or SQLdata. It's the most common usage of data forms in many data use cases. With the power of LLM, we would learn how to explore the data and perform datamodeling.
Data is driving most business decisions. In this, datamodeling tools play a crucial role in developing and maintaining the information system. Moreover, it involves the creation of a conceptual representation of data and its relationship. Datamodeling tools play a significant role in this.
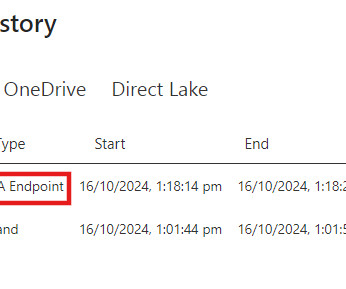
However, in Power BI Service, we can only refresh the entire semantic model, as there is no out-of-the-box solution for refreshing a single table. In this blog, we will explain how to refresh a single table in Power BI Service using XMLA Endpoints. Now, open SQL Server Management Studio (SSMS).
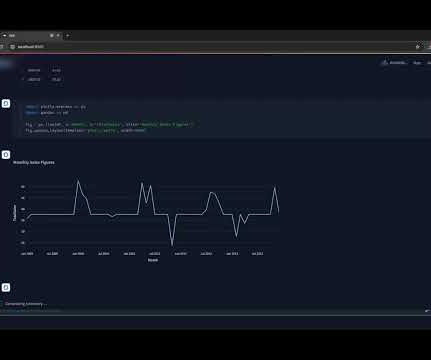
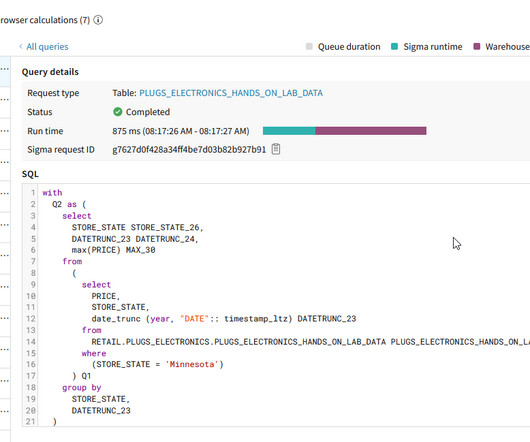
Sigma Computing , a cloud-based analytics platform, helps data analysts and business professionals maximize their data with collaborative and scalable analytics. One of Sigma’s key features is its support for custom SQL queries and CSV file uploads. These tools allow users to handle more advanced data tasks and analyses.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
As Indian companies across industries increasingly embrace data-driven decision-making, artificial intelligence (AI), and automation, the demand for skilled data scientists continues to surge. Validation techniques ensure models perform well on unseen data. Data Manipulation: Pandas, NumPy, dplyr.
I’m not going to go into huge details on this as if you follow AI / LLM (which I assume you do if you are reading this) but in a nutshell, RAG is the process whereby you feed external data into an LLM alongside prompts to ensure it has all of the information it needs to make decisions. What is GraphRAG? Why use Graphs and what are they?
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. HBase is employed to offer real-time key-based access to data.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special datamodelling steps? In this blog post, you’ll get a high-level overview of schema-based sharding and other new Citus 12 features: What is schema-based sharding?
However, to harness the full potential of Snowflake’s performance capabilities, it is essential to adopt strategies tailored explicitly for data vault modeling. Because of data vault’s modeling structure, transformation queries for moving data between these layers can become exceedingly complex.
Sigma Computing is a powerful datamodeling and analysis platform designed to leverage the power of modern cloud technology. Once connected to Snowflake , Sigma utilizes Machine Generated SQL to produce the most optimal results. Check out this blog to master the fundamentals. True or False. True or False.
The new ISO 39075 Graph Query Language Standard is to hit the data streets in late 2023 (?). If graph databases are standardized pretty soon, what will happen to SQL? Not simply because legacy SQL has a tremendous inertia, but because relational database paradigms […]. They will very likely stay around for a long time.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode. In 2021, Microsoft enabled Custom SQL queries to be run to Snowflake in DirectQuery mode further enhancing the connection capabilities between the platforms.
Summary: Business Intelligence Analysts transform raw data into actionable insights. They use tools and techniques to analyse data, create reports, and support strategic decisions. Key skills include SQL, data visualization, and business acumen. Introduction We are living in an era defined by data.
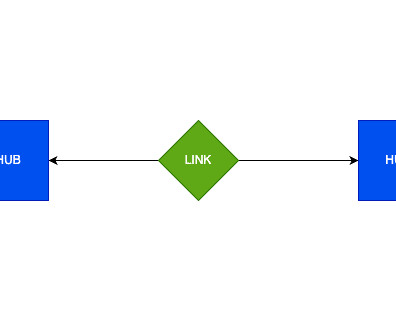
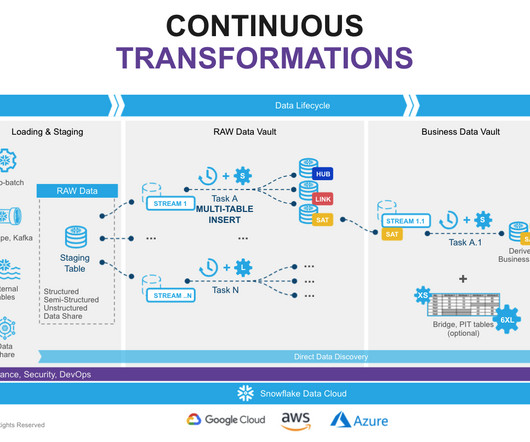
In this blog, our focus will be on exploring the data lifecycle along with several Design Patterns, delving into their benefits and constraints. Data architects can leverage these patterns as starting points or reference models when designing and implementing data vault architectures.
Best 8 data version control tools for 2023 (Source: DagsHub ) Introduction With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
In this blog post, I'll describe my analysis of Tableau's history to drive analytics innovation—in particular, I've identified six key innovation vectors through reflecting on the top innovations across Tableau releases. Query allowed customers from a broad range of industries to connect to clean useful data found in SQL and Cube databases.
This blog explores PostgreSQL vs MySQL, two popular RDBMS solutions, highlighting their differences to help you choose the right one for your needs. It is open-source and uses Structured Query Language (SQL) to manage and manipulate data. PostgreSQLs architecture is highly flexible, supporting many datamodels and workloads.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
Power BI Datamarts provides a low/no code experience directly within Power BI Service that allows developers to ingest data from disparate sources, perform ETL tasks with Power Query, and load data into a fully managed Azure SQL database. Note: At the time of writing this blog, Power BI Datamarts is in preview.
Accordingly, one of the most demanding roles is that of Azure Data Engineer Jobs that you might be interested in. The following blog will help you know about the Azure Data Engineering Job Description, salary, and certification course. Having experience using at least one end-to-end Azure data lake project.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
All of which have a specific role used to collect, store, process, and analyze data. This blog will hone in on the new collaboration, how to implement it into your workbooks, and why Sigma users should be excited about the feature. Using SQL-centric transformations to modeldata to be deployed.
In this blog, we will cover what tables and pivot tables are, the advantages and limitations of each, and the factors to consider when choosing which element to use. At the end of this blog, you will have a firm understanding of both elements and how to utilize each in your day-to-day data exploration.
To address these complexities, a powerful data warehousing solution like the Snowflake Data Cloud , coupled with an effective datamodeling approach such as the Data Vault architecture, can be a winning combination. What is a Data Vault Architecture? Contact phData!
The answer probably depends more on the complexity of your queries than the connectedness of your data. Relational databases (with recursive SQL queries), document stores, key-value stores, etc., Multi-model databases combine graphs with two other NoSQL datamodels – document and key-value stores.
Summary: This blog delves into hierarchies in dimensional modelling, highlighting their significance in data organisation and analysis. Real-world examples illustrate their application, while tools and technologies facilitate effective hierarchical data management in various industries.
Blog - Everest Group Requirements gathering: ChatGPT can significantly simplify the requirements gathering phase by building quick prototypes of complex applications. GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content