

Why using Infrastructure as Code for developing Cloud-based Data Warehouse Systems?
Data Science Blog
SEPTEMBER 19, 2023
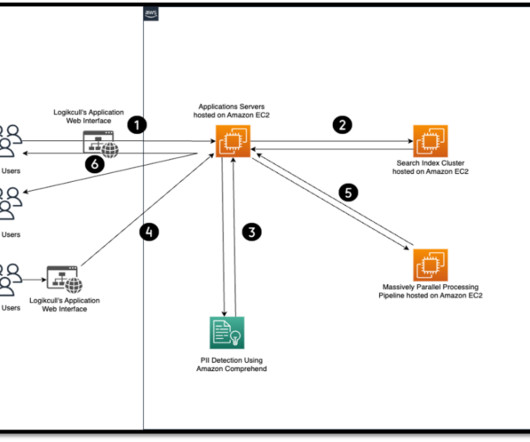
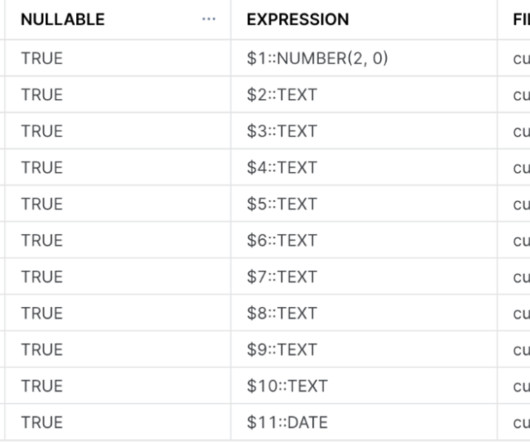
In the contemporary age of Big Data, Data Warehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?










































Let's personalize your content