This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
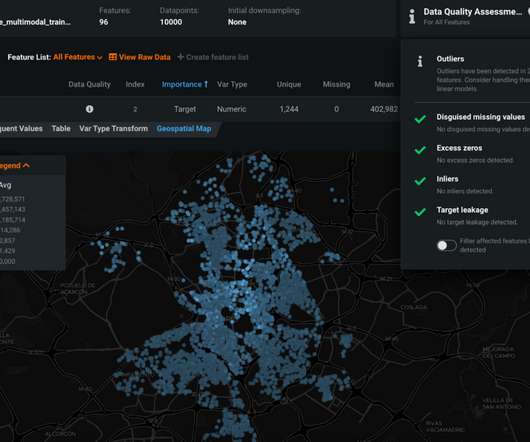
It excels in soft clustering, handling overlapping clusters, and modelling diverse cluster shapes. Its ability to model complex, multimodal data distributions makes it invaluable for clustering , density estimation, and pattern recognition tasks. GMM handles overlapping and non-spherical clusters better than K-Means.
A separate blog post describes the results and winners of the Hindcast Stage , all of whom won prizes in subsequent phases. This blog post presents the winners of all remaining stages: Forecast Stage where models made near-real-time forecasts for the 2024 forecast season. Lower is better.
The approach uses three sequential BERTopic models to generate the final clustering in a hierarchical method. Clustering We use the Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH) method to form different use case clusters. Lastly, a third layer is used for some of the clusters to create sub-topics.
SVM-based classifier: Amazon Titan Embeddings In this scenario, it is likely that user interactions belonging to the three main categories ( Conversation , Services , and Document_Translation ) form distinct clusters or groups within the embedding space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
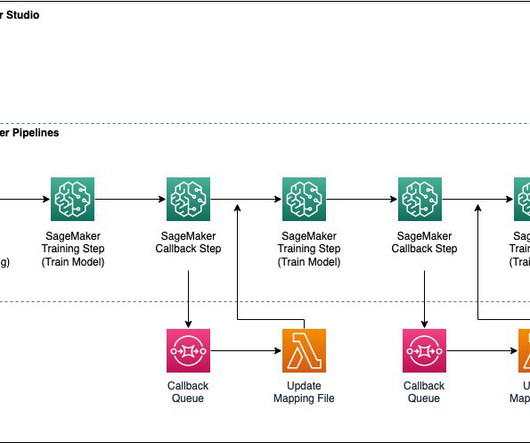
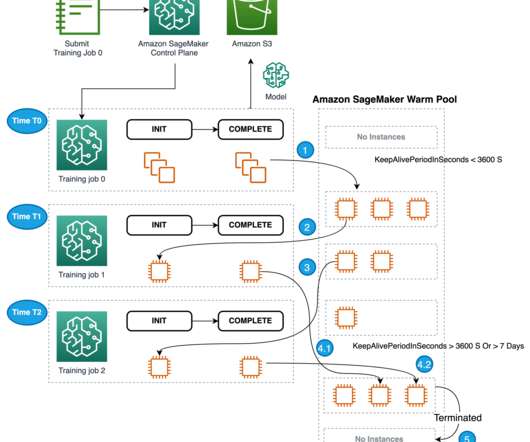
To reduce variance, Best Egg uses k-fold crossvalidation as part of their custom container to evaluate the trained model. After the first training job is complete, the instances used for training are retained in the warm pool cluster. The trained model artifact is registered and versioned in the SageMaker model registry.
In this blog post, we dive into all aspects of ML model performance: which metrics to use to measure performance, best practices that can help and where MLOps fits in. Clustering Metrics Clustering is an unsupervised learning technique where data points are grouped into clusters based on their similarities or proximity.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Solution overview In this blog post we address pre-training a genomic language model on an assembled genome. You can, for example, use the boto3 library to obtain this S3 URI.
This blog will delve into the major challenges faced by Machine Learning professionals, supported by statistics and real-world examples. The algorithm identifies patterns and structures within the data, such as clustering similar items or reducing dimensionality. spam detection) and regression tasks (e.g., predicting house prices).
Focusing on the various statistical models in R with examples, the following blog will help you learn in detail about these techniques and enhance your knowledge. This could be linear regression, logistic regression, clustering , time series analysis , etc. What is Statistical Modeling?
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. This blog outlines essential Machine Learning Engineer skills to help you thrive in this fast-evolving field. The global Machine Learning market was valued at USD 35.80
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. We perform a five-fold cross-validation to select the best model during training, and perform hyperparameter optimization to select the best settings on multiple model architecture and training parameters.
This blog aims to explain what Statistical Modeling is, highlight its key components, and explore its applications across various sectors. These models do not rely on predefined labels; instead, they discover the inherent structure in the data by identifying clusters based on similarities. What is Statistical Modeling?
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. Clustering and dimensionality reduction are common tasks in unSupervised Learning. customer segmentation), clustering algorithms like K-means or hierarchical clustering might be appropriate.
This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
For example, the model produced a RMSLE (Root Mean Squared Logarithmic Error) CrossValidation of 0.0825 and a MAPE (Mean Absolute Percentage Error) CrossValidation of 6.215. This would entail a roughly +/-€24,520 price difference on average, compared to the true price, using MAE (Mean Absolute Error) CrossValidation.
Summary: This blog covers 15 crucial artificial intelligence interview questions, ranging from fundamental concepts to advanced techniques. In this blog post, we will explore 15 essential artificial intelligence interview questions that cover a range of topics, from fundamental principles to cutting-edge techniques.
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Read the full blog here — [link] Data Science Interview Questions for Freshers 1. What is Cross-Validation? Cross-Validation is a Statistical technique used for improving a model’s performance.
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. Techniques such as cross-validation, regularisation , and feature selection can prevent overfitting. In my previous role, we had a project with a tight deadline.
This blog aims to explore the role of a Machine Learning Engineer, delve into salary insights, and assess future career prospects, providing a comprehensive guide for aspiring and current professionals in the field. You should be comfortable with cross-validation, hyperparameter tuning, and model evaluation metrics (e.g.,
This blog will explore the importance of feature extraction, its techniques, and its impact on model efficiency and accuracy. Projecting data into two or three dimensions reveals hidden structures and clusters, particularly in large, unstructured datasets. Selecting the right features is crucial for improving model performance.
For more practical guidance about extracting ML features from speech data, including example code to generate transformer embeddings, see this blog post ! Cluster 0 was in English and included many people talking to an Alexa. Cluster 1 and 2 were both Spanish. Cluster 3 was Mandarin. This had a few concrete impacts.
Perform cross-validation using StratifiedKFold. We perform cross-validation using the StratifiedKFold method, which splits the training data into K folds, maintaining the proportion of classes in each fold. The model is trained K times, using K-1 folds for training and one fold for validation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content