This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the data-driven world […] The post Monitoring DataQuality for Your BigDataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise.
Bigdata engineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on bigdata to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
Summary: BigData refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build datapipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Bigdatapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. However, data engineering is not without its challenges.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
In this blog, we are going to unfold the two key aspects of data management that is Data Observability and DataQuality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. Without the capabilities of Tecton , the architecture might look like the following diagram.
Databricks Databricks is a cloud-native platform for bigdata processing, machine learning, and analytics built using the Data Lakehouse architecture. Delta Lake Delta Lake is an open-source storage layer that provides reliability, ACID transactions, and data versioning for bigdata processing frameworks such as Apache Spark.
Working with massive structured and unstructured data sets can turn out to be complicated. It’s obvious that you’ll want to use bigdata, but it’s not so obvious how you’re going to work with it. So, let’s have a close look at some of the best strategies to work with large data sets. Metadata makes the task a lot easier.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. What is Data Engineering? million by 2028.
With data catalogs, you won’t have to waste time looking for information you think you have. Once your information is organized, a data observability tool can take your dataquality efforts to the next level by managing data drift or schema drift before they break your datapipelines or affect any downstream analytics applications.
Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
Tools like Git and Jenkins are not suited for managing data. By capturing metadata, such as transformations, storage configurations, versions, owners, lineage, statistics, dataquality, and other relevant attributes of the data, a feature platform can address these issues. This is where a feature platform comes in handy.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning.
This is achieved by using the pipeline to transfer data from a Splunk index into an S3 bucket, where it will be cataloged. With EDA, you can generate visualizations and analyses to validate whether you have the right data, and whether your ML model build is likely to yield results that are aligned to your organization’s expectations.
Join us in the city of Boston on April 24th for a full day of talks on a wide range of topics, including Data Engineering, Machine Learning, Cloud Data Services, BigData Services, DataPipelines and Integration, Monitoring and Management, DataQuality and Governance, and Data Exploration.
Machine learning engineer vs data scientist: The growing importance of both roles Machine learning and data science have become integral components of modern businesses across various industries. Machine learning, a subset of artificial intelligence , enables systems to learn and improve from data without being explicitly programmed.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. Read More: Advanced SQL Tips and Tricks for Data Analysts.
Organizations that can master the challenges of data integration, dataquality, and context will be well positioned to identify opportunities and threats quickly, and then to take decisive action to gain competitive advantage. Today, companies realize the true potential of that capability.
Such growth makes it difficult for many enterprises to leverage bigdata; they end up spending valuable time and resources just trying to manage data and less time analyzing it. What are the big differentiators between HPCC Systems and other bigdata tools? Spark is indeed a popular bigdata tool.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. Saurabh Gupta is a Principal Engineer at Zeta Global.
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data. Bias can also find its way into a model’s outputs long after deployment.
The right data integration solution helps you streamline operations, enhance dataquality, reduce costs, and make better data-driven decisions. It synthesizes all the metadata around your organization’s data assets and arranges the information into a simple, easy-to-understand format.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. Compute, bigdata, large commoditized models—all important stages.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. Compute, bigdata, large commoditized models—all important stages.
Amazon SageMaker Catalog serves as a central repository hub to store both technical and business catalog information of the data product. To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the dataquality metrics and data lineage events to track and drive transparency in datapipelines.
Internally within Netflix’s engineering team, Meson was built to manage, orchestrate, schedule, and execute workflows within ML/Datapipelines. Meson managed the lifecycle of ML pipelines, providing functionality such as recommendations and content analysis, and leveraged the Single Leader Architecture.
Datapipelines must seamlessly integrate new data at scale. Diverse data amplifies the need for customizable cleaning and transformation logic to handle the quirks of different sources. You can build and manage an incremental datapipeline to update embeddings on Vectorstore at scale.
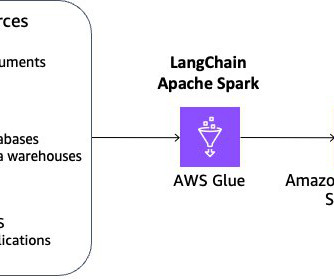
Their datapipeline (as shown in the following architecture diagram) consists of ingestion, storage, ETL (extract, transform, and load), and a data governance layer. Multi-source data is initially received and stored in an Amazon Simple Storage Service (Amazon S3) data lake.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content