This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. And Why did it happen?).
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Thus ensuring optimal performance.
Accordingly, one of the most demanding roles is that of AzureData Engineer Jobs that you might be interested in. The following blog will help you know about the AzureData Engineering Job Description, salary, and certification course. How to Become an AzureData Engineer?
Machine learning algorithms play a central role in building predictive models and enabling systems to learn from data. Big data platforms such as Apache Hadoop and Spark help handle massive datasets efficiently. Together, these tools enable DataScientists to tackle a broad spectrum of challenges. Masters or Ph.D.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. But we believe that this data shows something significant.
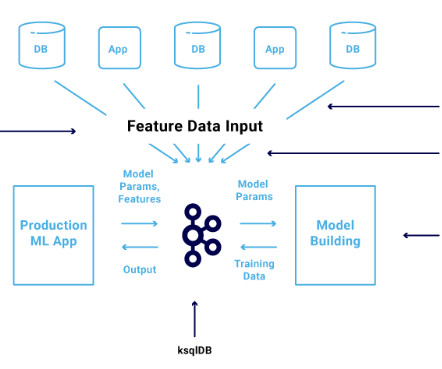
Each snapshot has a separate manifest file that keeps track of the data files associated with that snapshot and hence can be restored/queries whenever needed. Versioning also ensures a safer experimentation environment, where datascientists can test new models or hypotheses on historical data snapshots without impacting live data.
Data science is an increasingly attractive career path for many people. If you want to become a datascientist, then you should start by looking at the career options available. Northwestern University has a great list of ways that people can pursue a career in data science. Data processing is often done in batches.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption.
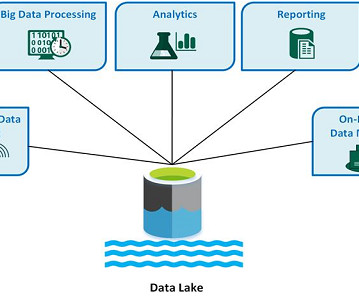
It is typically a single store of all enterprise data, including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics, and machine learning. Data processing happens in batch mode with the data stored at rest and can take minutes or even hours.
Data professionals are in high demand all over the globe due to the rise in big data. The roles of datascientists and data analysts cannot be over-emphasized as they are needed to support decision-making. This article will serve as an ultimate guide to choosing between Data Science and Data Analytics.
Answering one of the most common questions I get asked as a Senior DataScientist — What skills and educational background are necessary to become a datascientist? Photo by Eunice Lituañas on Unsplash To become a datascientist, a combination of technical skills and educational background is typically required.
The top 10 AI jobs include Machine Learning Engineer, DataScientist, and AI Research Scientist. Essential skills for these roles encompass programming, machine learning knowledge, data management, and soft skills like communication and problem-solving. Key Skills Experience with cloud platforms (AWS, Azure).
Since data is left in its raw form within the data lake, it’s easier for data teams to experiment with models and analysis techniques with greater flexibility. So let’s take a look at a few of the leading industry examples of data lakes. Snowflake Snowflake is a cross-cloud platform that looks to break down data silos.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Their work ensures that data flows seamlessly through the organisation, making it easier for DataScientists and Analysts to access and analyse information.
Even very traditional sectors, such as farming, use massive amounts of data to control multiple factors in their business. The Big Data in Agriculture initiative involves over 8,000 researchers , which shows how much demand there is for datascientists in these fields. Online Courses.
The rise of advanced technologies such as Artificial Intelligence (AI), Machine Learning (ML) , and Big Data analytics is reshaping industries and creating new opportunities for DataScientists. Automated Machine Learning (AutoML) will democratize access to Data Science tools and techniques.
Data Science focuses on analysing data to find patterns and make predictions. Data engineering, on the other hand, builds the foundation that makes this analysis possible. Without well-structured data, DataScientists cannot perform their work efficiently.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. However, these tools have functional gaps for more advanced data workflows.
Cloud platforms like AWS , Google Cloud Platform (GCP), and Microsoft Azure provide managed services for Machine Learning, offering tools for model training, storage, and inference at scale. Big data tools and Cloud computing platforms have become essential in providing the scalability and processing power required for effective ML workflows.
Building Your Data Science Team Data science talent is in high demand. Here are some options to consider: Hire DataScientists: This is ideal for complex projects requiring expertise in specific areas. Upskill Existing Employees: Train employees with analytical skills in data science fundamentals.
When it comes to data complexity, it is for sure that in machine learning, we are dealing with much more complex data. First of all, machine learning engineers and datascientists often use data from different data vendors. Some data sets are being corrected by data entry specialists and manual inspectors.
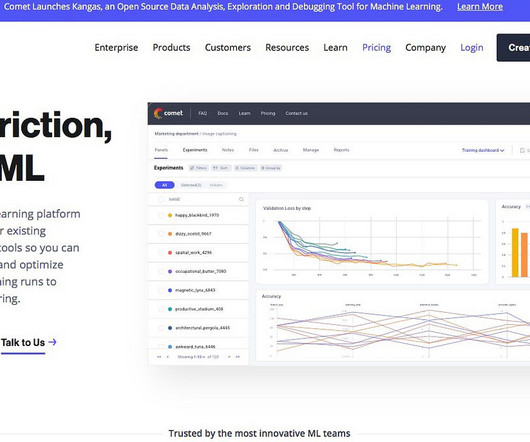
Comet is an all-inclusive cloud-based platform that can help datascientists and machine learning engineers streamline their workflow and improve the efficiency of their experimentation process. Comet also integrates with popular data storage and processing tools like Amazon S3, Google Cloud Storage, and Hadoop.
So, a better database architecture would be to maintain multiple tables where one of the tables maintains the past 3 months history with session-level details, whereas other tables may contain weekly aggregated click, ATC, and order data. Keeping track of which data was used to run an experiment sometimes becomes painful for a DataScientist.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content